自然语言处理NLP--文本相似度面试题
-
-
- 问题 1: 什么是文本相似度,如何在搜索系统中应用?
- 问题 2: 如何使用TF-IDF进行文本相似度计算?
- 问题 3: 使用Word2Vec进行文本相似度计算的过程是怎样的?
- 问题 4: BERT如何用于文本相似度计算?
- 问题5:三种方法的优缺点?
- 问题6:如何优化TF-IDF的计算速度?
- 问题7: 如何处理计算文本相似度时的高维度数据问题?
- 问题8: 在处理文本相似度计算时,如何应对同义词和多义词的问题?
- 问题9: 如何在文本相似度计算中处理噪音数据(如拼写错误或非标准表达)?
- 问题10: 如何结合TF-IDF和Word2Vec的方法来提高文本相似度计算的效果?
- 使用Python实现TF-IDF、Word2Vec和BERT进行文本相似度计算的案例
-
问题 1: 什么是文本相似度,如何在搜索系统中应用?
回答:
文本相似度是用来衡量两段文本在语义上的相似程度的度量。文本相似度的应用包括信息检索、推荐系统、文本聚类和分类等。在搜索系统中,文本相似度可以帮助匹配用户查询与文档库中的相关文档,从而提高检索效果。
常见的文本相似度计算方法包括:
- 基于词频-逆文档频率 (TF-IDF) 的余弦相似度:将文本表示为词项向量,计算向量间的余弦值作为相似度。
- 词嵌入 (Word Embeddings):使用预训练的词嵌入模型(如Word2Vec, GloVe)将词转化为稠密向量,通过向量间的距离(如余弦距离或欧氏距离)计算相似度。
- 上下文嵌入 (Contextual Embeddings):使用BERT等上下文嵌入模型,将整段文本编码为稠密向量,通过向量间的距离计算相似度。
问题 2: 如何使用TF-IDF进行文本相似度计算?
回答:
TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用的文本表示方法,通过考虑词语在文档中的频率以及在整个文档集合中的反向频率来衡量词的重要性。使用TF-IDF进行文本相似度计算的步骤如下:
构建词汇表:从文档集合中提取所有出现的词语,构建词汇表。
计算TF值:对于每个文档,计算每个词语的词频(Term Frequency),即该词语在文档中出现的次数。
计算IDF值:计算每个词语的逆文档频率(Inverse Document Frequency),公式为:
I D F ( t ) = log ( N D F ( t ) ) IDF(t) = \log(\frac{N}{DF(t)}) IDF(t)=log(DF(t)N)
其中,N是文档总数,DF(t)是包含词语t的文档数量。计算TF-IDF值:对于每个词语,计算其TF-IDF值:
T F − I D F ( t , d ) = T F ( t , d ) × I D F ( t ) TF-IDF(t, d) = TF(t, d) \times IDF(t) TF−IDF(t,d)=TF(t,d)×IDF(t)
其中,TF(t, d)是词语t在文档d中的词频。计算文本向量的余弦相似度:将文档表示为TF-IDF向量,计算两个向量的余弦相似度:
cos ( θ ) = A ⃗ ⋅ B ⃗ ∣ ∣ A ⃗ ∣ ∣ ⋅ ∣ ∣ B ⃗ ∣ ∣ \cos(\theta) = \frac{\vec{A} \cdot \vec{B}}{||\vec{A}|| \cdot ||\vec{B}||} cos(θ)=∣∣A∣∣⋅∣∣B∣∣A⋅B
其中, A ⃗ \vec{A} A和 B ⃗ \vec{B} B是两个文档的TF-IDF向量。
问题 3: 使用Word2Vec进行文本相似度计算的过程是怎样的?
回答:
Word2Vec是一种将词语嵌入为稠密向量的模型,可以用于计算文本相似度。使用Word2Vec进行文本相似度计算的过程如下:
- 训练或加载预训练的Word2Vec模型:可以使用大规模语料库训练Word2Vec模型,或者使用预训练的模型(如Google News Word2Vec)。
- 将文本表示为词向量:将文本中的每个词语转换为Word2Vec词向量。
- 计算文本向量:通过对文本中所有词向量取平均值或加权平均值,得到整个文本的向量表示。
- 计算文本向量的相似度:使用余弦相似度或欧氏距离等方法计算两个文本向量之间的相似度。
这种方法相比于TF-IDF,更加注重词语之间的语义关系,能够捕捉到更丰富的语义信息。
问题 4: BERT如何用于文本相似度计算?
回答:
BERT(Bidirectional Encoder Representations from Transformers)是一个上下文嵌入模型,可以用于计算文本相似度。使用BERT进行文本相似度计算的步骤如下:
- 加载预训练的BERT模型:使用Transformers库加载预训练的BERT模型。
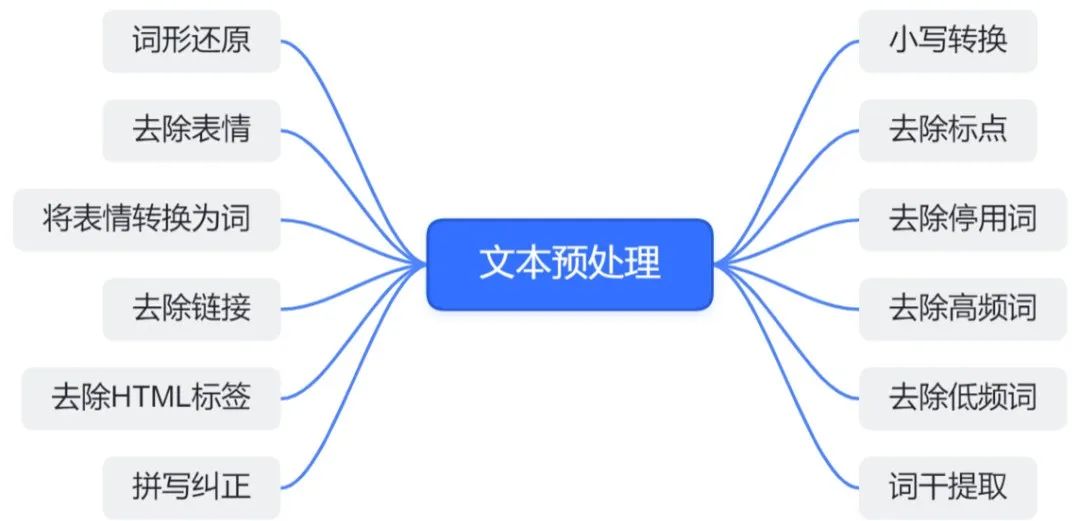
- 文本预处理:将输入文本进行分词,并转换为BERT模型所需的输入格式(包括输入IDs、注意力掩码等)。
- 生成文本向量:将预处理后的文本输入BERT模型,提取模型的最后一层隐藏状态向量。通常,使用[CLS]标记对应的向量作为整个文本的表示。
- 计算文本向量的相似度:使用余弦相似度或欧氏距离等方法计算两个文本向量之间的相似度。
BERT通过双向Transformer架构,可以捕捉到词语在上下文中的语义信息,因此在许多自然语言处理任务中表现优异。
问题5:三种方法的优缺点?
- TF-IDF
优点:
- 简单易懂:TF-IDF的计算方法直观,容易理解和实现。
- 快速高效:计算速度快,适合处理大规模文档集。
- 无训练需求:不需要预训练模型,可以直接基于词频和文档频率计算。
缺点:
- 无法捕捉语义关系:TF-IDF仅考虑词频,忽略了词语之间的语义关系。例如,"车"和"汽车"在TF-IDF中是完全不同的词。
- 稀疏表示:生成的TF-IDF向量通常非常稀疏,向量维度高,不利于存储和计算。
- 对词顺序不敏感:忽略了词语的顺序信息,不能反映上下文语义。
- Word2Vec
优点:
- 捕捉语义关系:Word2Vec通过训练词嵌入模型,能够捕捉词语之间的语义关系,类似的词会有相近的向量表示。
- 稠密向量表示:生成的词嵌入向量是稠密的,维度相对较低,便于存储和计算。
- 广泛应用:可以用于各种下游任务,如文本分类、聚类和情感分析等。
缺点:
- 忽略上下文信息:Word2Vec只能捕捉词语的静态语义,不考虑上下文。相同的词在不同语境中表示相同的向量。
- 需要大量训练数据:训练高质量的Word2Vec模型需要大量的语料库,否则效果不佳。
- 计算复杂度高:训练过程涉及大量计算,尤其在处理大规模语料库时,计算资源需求高。
- BERT
优点:
- 上下文语义表示:BERT通过双向Transformer架构,能够捕捉词语在不同上下文中的语义,生成上下文敏感的词向量。
- 高精度:在许多自然语言处理任务中,BERT的性能远超传统方法,效果显著。
- 预训练模型:可以利用大量预训练模型,省去了训练时间和资源,直接进行微调应用于具体任务。
缺点:
- 计算资源消耗大:BERT模型参数量大,推理和微调过程需要大量计算资源,训练速度慢。
- 复杂性高:模型结构复杂,实现和调试难度高,对使用者有较高的技术要求。
- 高存储需求:BERT模型体积较大,对存储资源需求高。
总结
- TF-IDF:适合快速、简单的文本相似度计算任务,但在处理语义关系和上下文方面表现较弱。
- Word2Vec:在捕捉词语语义关系方面表现较好,适用于需要语义表示的任务,但忽略了上下文信息。
- BERT:在处理上下文和语义表示方面性能最佳,适用于高精度自然语言处理任务,但计算和存储资源需求高,模型复杂度高。
根据具体应用场景和资源限制,选择合适的方法可以更有效地解决文本相似度计算问题。
这些问题涉及文本相似度计算的不同优化和处理策略,以下是详细的回答:
问题6:如何优化TF-IDF的计算速度?
优化策略:
- 预计算和缓存:在查询时,预先计算并缓存所有文档的TF-IDF向量,以避免每次查询时重新计算。
- 稀疏矩阵表示:使用稀疏矩阵存储TF-IDF向量,节省内存并提高计算速度。Scipy的稀疏矩阵模块是一个常用工具。
- 增量计算:对于新增文档,采用增量计算TF-IDF值,而不是重新计算整个文档集合的TF-IDF值。
- 并行计算:利用多线程或分布式计算框架(如Apache Spark)并行计算TF-IDF值,加速大规模数据处理。
- 优化查询流程:对于每次查询,仅计算与查询相关的文档子集的TF-IDF值,而不是整个文档集合。
问题7: 如何处理计算文本相似度时的高维度数据问题?
处理策略:
- 降维技术:使用主成分分析(PCA)、奇异值分解(SVD)等降维技术,将高维向量降至低维,从而减少计算复杂度。
- 特征选择:选择最有代表性的特征进行计算,过滤掉低频词和高频词,以减少维度。
- 局部敏感哈希(LSH):利用LSH进行近似最近邻搜索,减少高维数据的计算复杂度,同时保持相似度计算的准确性。
- 聚类技术:将文档聚类,将每个文档表示为其所属聚类的中心向量,降低维度。
- 稀疏表示和索引:使用稀疏表示和高效索引(如倒排索引)结构,减少存储和计算的开销。
问题8: 在处理文本相似度计算时,如何应对同义词和多义词的问题?
应对策略:
- 同义词词典:建立同义词词典,将同义词归一化为同一个标准词。例如,“car"和"automobile"都归一化为"car”。
- 词向量模型:使用Word2Vec、GloVe等词向量模型,将词语转化为语义相近的向量,可以捕捉同义词的相似性。
- 上下文嵌入模型:使用BERT等上下文嵌入模型,可以根据上下文理解多义词的不同含义,从而准确计算相似度。
- 知识图谱:利用知识图谱(如WordNet)理解词语之间的关系,增强同义词和多义词的处理能力。
- 扩展查询:在计算相似度时,对查询进行扩展,包括查询的同义词和相关词,从而提高相似度计算的准确性。
问题9: 如何在文本相似度计算中处理噪音数据(如拼写错误或非标准表达)?
处理策略:
- 拼写纠正:使用拼写检查和纠正算法(如Levenshtein距离),自动纠正拼写错误。
- 文本规范化:对文本进行规范化处理,包括去除特殊字符、统一大小写、标准化缩写词等。
- 数据清洗:在预处理阶段进行数据清洗,去除无关内容和低质量数据,提升计算的准确性。
- 使用鲁棒模型:使用能够容忍噪音数据的模型(如BERT等上下文嵌入模型),提高相似度计算的鲁棒性。
- 上下文信息:结合上下文信息,减少噪音数据对相似度计算的影响。
问题10: 如何结合TF-IDF和Word2Vec的方法来提高文本相似度计算的效果?
结合方法:
- 混合向量表示:将TF-IDF和Word2Vec生成的向量进行加权融合,生成混合向量。加权策略可以根据具体任务调整。
- 特征拼接:将TF-IDF向量和Word2Vec向量拼接成一个更长的向量,保留两者的信息,提高相似度计算的准确性。
- 层次化计算:先使用TF-IDF进行初步筛选,过滤掉明显不相关的文档,再使用Word2Vec进行精细化相似度计算。
- 模型集成:训练一个模型,将TF-IDF和Word2Vec的相似度分数作为特征,结合其他特征输入到模型中,综合判断文本相似度。
- 迭代优化:在实际应用中,不断迭代和优化TF-IDF和Word2Vec的融合方法,通过A/B测试和用户反馈,找到最优的组合策略。
这些策略和方法可以帮助在文本相似度计算中提升效果和效率,适应不同的应用场景和数据特点。
使用Python实现TF-IDF、Word2Vec和BERT进行文本相似度计算的案例
1. TF-IDF
使用scikit-learn库进行TF-IDF计算和相似度计算。
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# 示例文本
documents = [
"I love machine learning and natural language processing.",
"Deep learning is a key area of machine learning.",
"Cooking recipes often involve using different ingredients and techniques to create dishes."
]
# 初始化TF-IDF向量器
vectorizer = TfidfVectorizer()
# 计算TF-IDF矩阵
tfidf_matrix = vectorizer.fit_transform(documents)
# 计算相似度矩阵
similarity_matrix = cosine_similarity(tfidf_matrix)
print("TF-IDF相似度矩阵:")
print(similarity_matrix)
TF-IDF相似度矩阵:
[[1. 0.25791788 0.07097892]
[0.25791788 1. 0. ]
[0.07097892 0. 1. ]]
2. Word2Vec
使用gensim库进行Word2Vec训练和相似度计算。
from gensim.models import Word2Vec
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# 示例文本
sentences = [
["I", "love", "machine", "learning", "and", "natural", "language", "processing"],
["Deep", "learning", "is", "a", "key", "area", "of", "machine", "learning"],
["Cooking", "recipes", "often", "involve", "using", "different", "ingredients", "and", "techniques", "to", "create", "dishes"]
]
# 训练Word2Vec模型
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4)
# 获取文本向量表示
def get_sentence_vector(sentence, model):
vectors = [model.wv[word] for word in sentence if word in model.wv]
return np.mean(vectors, axis=0) if vectors else np.zeros(model.vector_size)
sentence_vectors = [get_sentence_vector(sentence, model) for sentence in sentences]
# 计算相似度矩阵
similarity_matrix = cosine_similarity(sentence_vectors)
print("Word2Vec相似度矩阵:")
print(similarity_matrix)
Word2Vec相似度矩阵:
[[1.0000001 0.3102629 0.139046 ]
[0.3102629 0.99999964 0.10446144]
[0.139046 0.10446144 1.0000001 ]]
3. BERT
使用transformers库进行BERT文本嵌入和相似度计算。
from transformers import BertTokenizer, BertModel
import torch
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# 示例文本
documents = [
"I love machine learning and natural language processing.",
"Deep learning is a key area of machine learning.",
"Cooking recipes often involve using different ingredients and techniques to create dishes."
]
# 加载预训练的BERT模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 获取文本向量表示
def get_sentence_embedding(sentence, tokenizer, model):
inputs = tokenizer(sentence, return_tensors='pt', padding=True, truncation=True)
with torch.no_grad():
outputs = model(**inputs)
# 使用 [CLS] 标记的嵌入向量作为句子的向量表示
cls_embedding = outputs.last_hidden_state[:, 0, :].squeeze()
return cls_embedding.numpy()
# 生成所有文本的嵌入向量
sentence_embeddings = [get_sentence_embedding(doc, tokenizer, model) for doc in documents]
# 将列表转换为二维矩阵
sentence_embeddings_matrix = np.vstack(sentence_embeddings)
# 计算相似度矩阵
similarity_matrix = cosine_similarity(sentence_embeddings_matrix)
print("BERT相似度矩阵:")
print(similarity_matrix)
BERT相似度矩阵:
[[1. 0.8768941 0.7478378]
[0.8768941 1.0000002 0.8036001]
[0.7478378 0.8036001 0.9999999]]





















![[米联客-安路飞龙DR1-FPSOC] FPGA基础篇连载-18 I2C MASTER控制器驱动设计](https://i-blog.csdnimg.cn/direct/63dc0072b2a143cbb5dec4330f11b57c.png)