什么是正则表达式
正则表达式(Regular Expression,简称Regex)是一种用于匹配字符串中字符模式的工具。它是由普通字符(例如字母、数字)以及一些特殊字符(称为元字符)组成的字符序列。这种模式用于在文本中搜索、匹配和替换字符串。
正则表达式是一种强大的文本处理工具,可以用来验证输入、搜索匹配、替换字符串以及解析复杂的文本格式。由于其灵活性和强大的功能,正则表达式被广泛应用于各种编程语言中,包括Python。
正则表达式的基础语法
正则表达式由许多元字符和符号组成,这些字符和符号具有特定的含义。以下是一些常见的正则表达式元字符及其作用:
1、普通字符:
匹配自身。例如,正则表达式abc匹配字符串中的abc。
2、点号(.):
匹配除换行符外的任意单个字符。例如,正则表达式a.b可以匹配aab、acb等,但不能匹配a\nb。
3、星号(*):
匹配前面的字符零次或多次。例如,正则表达式ab*c可以匹配ac、abc、abbc等。
4、加号(+):
匹配前面的字符一次或多次。例如,正则表达式ab+c可以匹配abc、abbc等,但不能匹配ac。
5、问号(?):
匹配前面的字符零次或一次。例如,正则表达式ab?c可以匹配ac或abc。
6、方括号([]):
匹配方括号内的任意一个字符。例如,正则表达式[abc]可以匹配a、b或c。
7、脱字符(^):
匹配字符串的开始位置。例如,正则表达式^abc匹配以abc开头的字符串。
8、美元符号($):
匹配字符串的结束位置。例如,正则表达式abc$匹配以abc结尾的字符串。
9、竖线(|):
表示逻辑或。例如,正则表达式a|b可以匹配a或b。
10、圆括号(()):
用于分组和提取子模式。例如,正则表达式(abc)可以匹配并提取abc。
11、反斜杠(\):
转义字符,用于匹配元字符的字面值。例如,正则表达式\.匹配点号本身,而不是任意字符。
正则表达式的高级特性
字符类
字符类是一种简化匹配特定字符集合的方法。方括号内的字符集合构成一个字符类。常见的字符类包括:
[a-z]:匹配任何小写字母。[A-Z]:匹配任何大写字母。[0-9]:匹配任何数字。[a-zA-Z0-9]:匹配任何字母或数字。[^a-z]:匹配除小写字母以外的任何字符。
预定义字符类
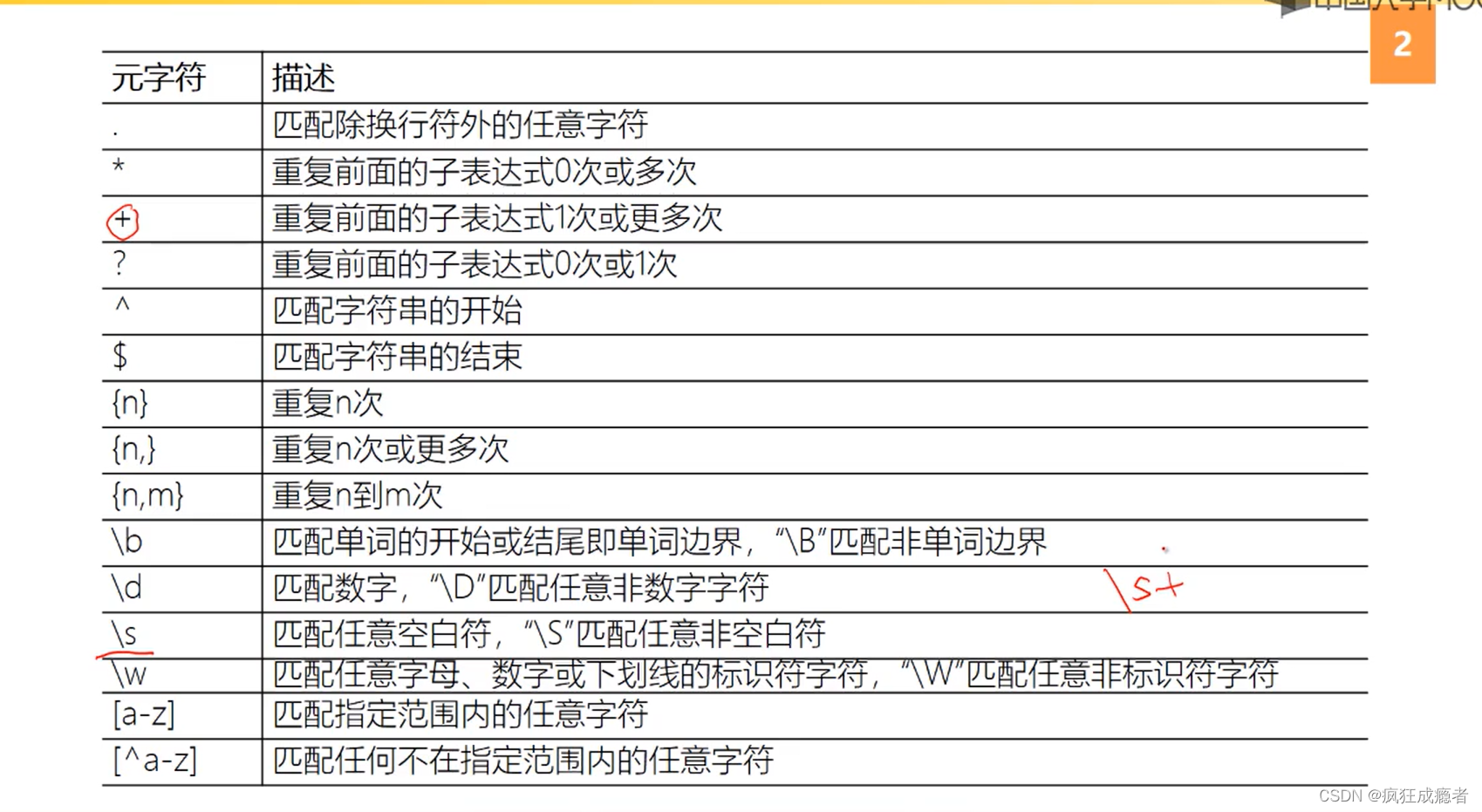
Python的正则表达式模块re中还定义了一些常用的预定义字符类,例如:
\d:匹配任何数字,相当于[0-9]。\D:匹配任何非数字字符,相当于[^0-9]。\w:匹配任何字母、数字或下划线字符,相当于[a-zA-Z0-9_]。\W:匹配任何非字母、数字或下划线字符,相当于[^a-zA-Z0-9_]。\s:匹配任何空白字符(包括空格、制表符、换页符等),相当于[ \t\n\r\f\v]。\S:匹配任何非空白字符,相当于[^ \t\n\r\f\v]。
边界匹配
正则表达式还提供了一些边界匹配符,用于匹配单词的边界或字符串的开始和结束:
\b:匹配单词边界。例如,正则表达式\bword\b匹配整个单词word,而不是wordy或sword。\B:匹配非单词边界。例如,正则表达式\Bword\B匹配awordb中的word部分。
贪婪与懒惰匹配
正则表达式中的量词(如*、+、?)默认是贪婪的,会尽可能多地匹配字符。可以通过在量词后面加?来将其变为懒惰匹配,即尽可能少地匹配字符。例如:
- 贪婪匹配:
<.*>会匹配整个字符串中的第一个<和最后一个>之间的所有字符。 - 懒惰匹配:
<.*?>会匹配第一个<和第一个>之间的字符。
Python中的正则表达式
Python提供了一个强大的正则表达式模块re,用于执行正则表达式操作。以下是一些常用的re模块方法:
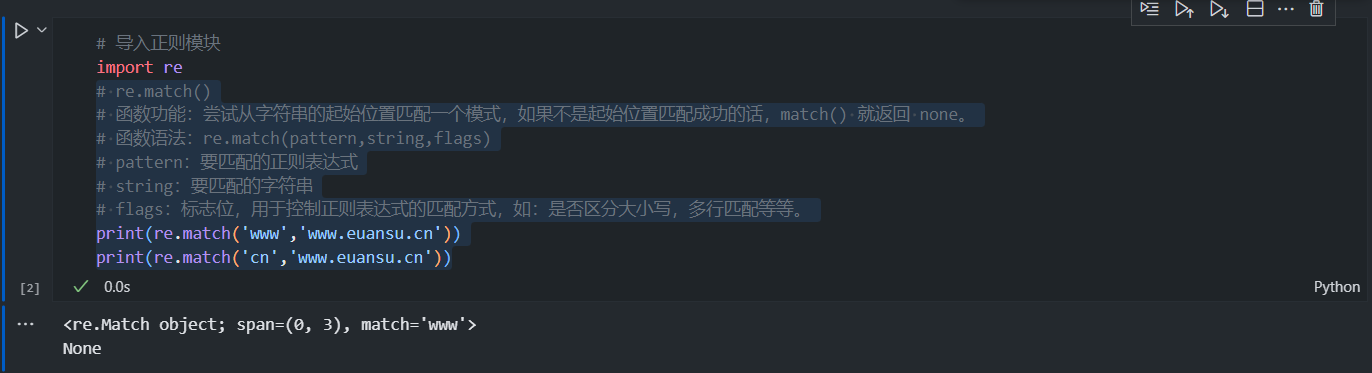
1、re.match()
- 用于从字符串的起始位置匹配正则表达式。如果匹配成功,返回一个匹配对象,否则返回
None。
import re
pattern = r'hello'
text = 'hello world'
match = re.match(pattern, text)
if match:
print(f"Match found: {match.group()}")
else:
print("No match")
2、re.search()
- 扫描整个字符串并返回第一个成功的匹配。
pattern = r'world'
text = 'hello world'
search = re.search(pattern, text)
if search:
print(f"Search found: {search.group()}")
else:
print("No match")
3、re.findall()
- 查找字符串中所有非重叠的匹配项,并以列表的形式返回。
pattern = r'\d+'
text = 'There are 123 apples and 456 oranges'
matches = re.findall(pattern, text)
print(matches) # Output: ['123', '456']
4、re.finditer()
- 与
findall类似,但返回的是一个迭代器,每个匹配项都是一个MatchObject。
pattern = r'\d+'
text = 'There are 123 apples and 456 oranges'
matches = re.finditer(pattern, text)
for match in matches:
print(match.group())
5、re.sub()
- 替换字符串中所有匹配的子串,并返回替换后的字符串。
pattern = r'apples'
replacement = 'bananas'
text = 'I have apples and apples'
new_text = re.sub(pattern, replacement, text)
print(new_text) # Output: 'I have bananas and bananas'
6、re.split()
- 根据匹配的子串将字符串分割成列表。
pattern = r'\s+'
text = 'I have apples and oranges'
result = re.split(pattern, text)
print(result) # Output: ['I', 'have', 'apples', 'and', 'oranges']
MatchObject对象
当正则表达式匹配成功时,re.match()、re.search()等方法会返回一个MatchObject对象。这个对象包含匹配的相关信息,可以通过以下方法访问:
group():返回匹配的子串。start():返回匹配的起始位置。end():返回匹配的结束位置。span():返回匹配的起始和结束位置。
import re
pattern = r'world'
text = 'hello world'
match = re.search(pattern, text)
if match:
print(f"Matched text: {match.group()}") # Output: world
print(f"Start position: {match.start()}") # Output: 6
print(f"End position: {match.end()}") # Output: 11
print(f"Span: {match.span()}") # Output: (6, 11)
编译正则表达式
对于需要多次使用的正则表达式,可以使用re.compile()将其编译成正则表达式对象,提高匹配效率。
import re
pattern = re.compile(r'\d+')
text = 'There are 123 apples and 456 oranges'
matches = pattern.findall(text)
print(matches) # Output: ['123', '456']
实例与应用
验证邮箱地址
import re
def validate_email(email):
pattern = r'^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$'
return re.match(pattern, email) is not None
email = 'example@example.com'
print(validate_email(email)) # Output: True
提取URL中的域名
import re
def extract_domain(url):
pattern = r'https?://(www\.)?([^/]+)'
match = re.search(pattern, url)
if match:
return match.group(2)
return None
url = 'https://www.example.com/path/to/page'
print(extract_domain(url)) # Output: example.com
替换文本中的敏感词
import re
def censor_text(text, sensitive_words):
pattern = '|'.join(map(re.escape, sensitive_words))
return re.sub(pattern, '****', text)
text = 'This is a bad and ugly example.'
sensitive_words = ['bad', 'ugly']
print(censor_text(text, sensitive_words)) # Output: This is a **** and **** example.
解析复杂文本格式
import re
log_entry = '2024-07-18 12:34:56 ERROR [main] - A critical error occurred'
pattern = r'(\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}) (\w+) \[(\w+)\] - (.*)'
match = re.match(pattern, log_entry)
if match:
timestamp, log_level, source, message = match.groups()
print(f"Timestamp: {timestamp}")
print(f"Log Level: {log_level}")
print(f"Source: {source}")
print(f"Message: {message}")
正则表达式是一种强大且灵活的文本处理工具,通过掌握其基础语法和高级特性,可以高效地解决各种复杂的文本匹配和处理问题。在Python中,利用re模块可以方便地使用正则表达式进行字符串操作。无论是数据验证、文本搜索与替换,还是解析复杂的文本格式,正则表达式都提供了极大的便利。