大数据技术概述:Hadoop、Spark等大数据技术介绍
目录
引言
随着数据量的爆炸性增长,传统的数据处理和分析技术已经无法满足需求。大数据技术应运而生,通过分布式计算和存储解决了大规模数据处理的问题。本文将介绍两种主流的大数据技术:Hadoop和Spark,探讨它们的特点、安装配置和应用场景。
大数据简介
大数据指的是无法用传统数据库工具进行采集、管理和处理的海量数据集。大数据技术通过分布式存储和计算,能够高效地处理和分析这些数据,提取有价值的信息。常见的大数据技术包括Hadoop、Spark、Flink、Hive等。
Hadoop
Hadoop概述
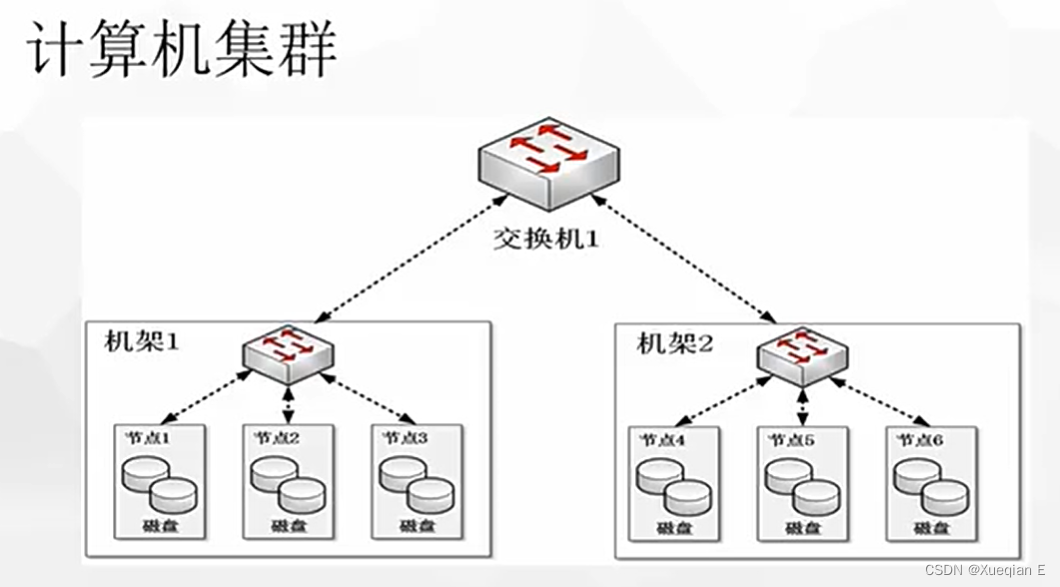
Hadoop是一个开源的分布式计算框架,由Apache基金会维护。Hadoop的核心是HDFS(Hadoop Distributed File System)和MapReduce编程模型,提供了可靠的分布式存储和计算能力。
Hadoop生态系统
Hadoop生态系统由多个组件组成,常见的包括:
- HDFS:分布式文件系统,负责数据存储。
- MapReduce:分布式计算框架,负责数据处理。
- YARN:资源管理器,负责集群资源的调度和管理。
- Hive:数据仓库工具,提供SQL查询功能。
- Pig:数据流处理语言,适用于复杂的数据分析任务。
- HBase:分布式NoSQL数据库,适用于高性能读写操作。
Hadoop的安装和配置
安装Hadoop
- 下载Hadoop:
wget https://downloads.apache.org/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
- 解压Hadoop:
tar -zxvf hadoop-3.3.1.tar.gz
- 配置Hadoop环境变量:
export HADOOP_HOME=/path/to/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
- 配置HDFS和YARN:
编辑$HADOOP_HOME/etc/hadoop/hdfs-site.xml,添加以下配置:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
编辑$HADOOP_HOME/etc/hadoop/yarn-site.xml,添加以下配置:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
</configuration>
- 格式化HDFS并启动Hadoop:
hdfs namenode -format
start-dfs.sh
start-yarn.sh
Spark
Spark概述
Spark是一个快速、通用的分布式计算系统,最初由加州大学伯克利分校的AMPLab开发,现由Apache基金会维护。Spark基于内存计算,具有比Hadoop MapReduce更高的处理速度和更丰富的API。
Spark的核心组件
- Spark Core:提供基本的分布式任务调度和内存管理。
- Spark SQL:支持使用SQL查询数据,并与Hive集成。
- Spark Streaming:用于实时数据流处理。
- MLlib:机器学习库,提供常用的机器学习算法。
- GraphX:图计算框架,适用于图数据的处理和分析。
Spark的安装和配置
安装Spark
- 下载Spark:
wget https://downloads.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
- 解压Spark:
tar -zxvf spark-3.1.2-bin-hadoop3.2.tgz
- 配置Spark环境变量:
export SPARK_HOME=/path/to/spark
export PATH=$PATH:$SPARK_HOME/bin
- 启动Spark:
start-master.sh
start-worker.sh spark://<master-url>:7077
Hadoop与Spark的比较
| 特性 | Hadoop | Spark |
|---|---|---|
| 核心组件 | HDFS, MapReduce, YARN | Spark Core, Spark SQL, Spark Streaming, MLlib, GraphX |
| 数据处理模式 | 批处理 | 批处理、实时处理 |
| 编程语言 | Java | Scala, Java, Python, R |
| 性能 | 受限于磁盘IO | 基于内存计算,性能更高 |
| 易用性 | 相对复杂 | API丰富,使用更简单 |
大数据技术的应用案例
案例1:银行业中的反欺诈检测
背景:一家大型银行需要实时检测交易中的欺诈行为。
解决方案:使用Spark Streaming处理实时交易数据,并通过MLlib进行欺诈检测。
结果:大幅提高了欺诈检测的准确性和实时性,降低了银行的损失。
案例2:电商网站的推荐系统
背景:一家电商网站希望提高用户的购买转化率。
解决方案:使用Hadoop和Spark构建推荐系统,分析用户行为数据并生成个性化推荐。
结果:推荐系统显著提高了用户的购买转化率和满意度。
结论
Hadoop和Spark作为两种主流的大数据技术,各有优势和应用场景。Hadoop适用于大规模批处理任务,而Spark则在实时处理和内存计算方面表现出色。通过合理选择和整合这些技术,可以有效应对各种大数据处理和分析需求,推动业务发展。