import pdfplumber
import pandas as pd
def extract_tables_to_excel(pdf_path, excel_path):
# 打开PDF文件
with pdfplumber.open(pdf_path) as pdf:
# 创建一个空的DataFrame列表,用于存储所有表格数据
all_tables = []
# 遍历PDF的每一页
for page in pdf.pages:
# 提取当前页的表格
tables = page.extract_tables()
# 将每页的表格转换为DataFrame,并添加到all_tables列表中
for table in tables:
df = pd.DataFrame(table)
all_tables.append(df)
# 将所有表格数据合并为一个DataFrame
combined_tables = pd.concat(all_tables, ignore_index=True)
# 将合并后的表格数据保存到Excel文件中
combined_tables.to_excel(excel_path, index=False)
# PDF文件路径
pdf_path = '1.pdf'
# Excel文件路径
excel_path = 'output_tables.xlsx'
# 调用函数
extract_tables_to_excel(pdf_path, excel_path)
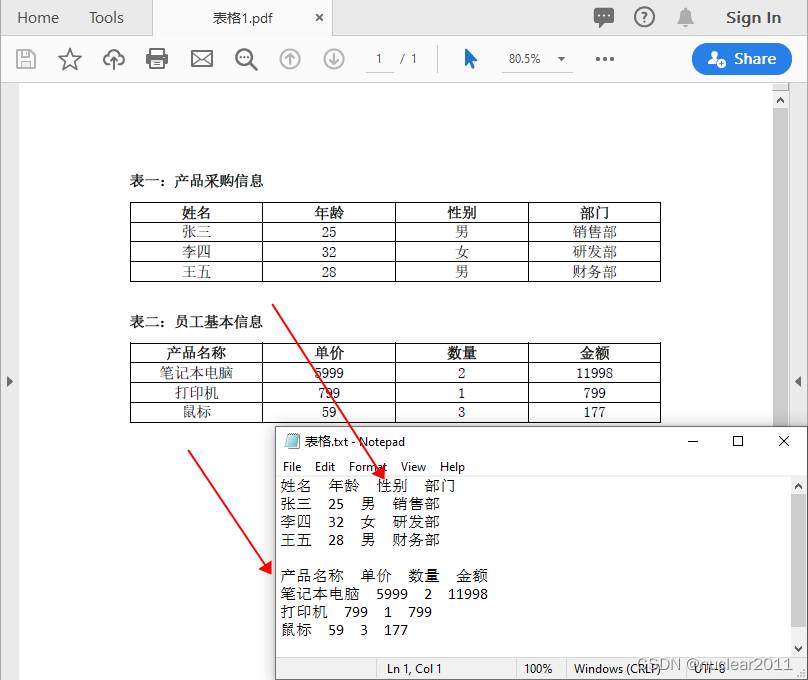
Python 提取PDF表格数据并保存到TXT文本或Excel文件
2024-07-18 09:38:03 34 阅读