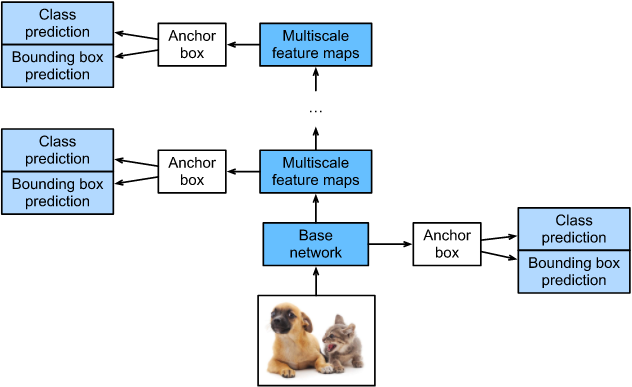
在Java中,无锁编程是一种在多线程环境下避免使用传统锁机制(如synchronized关键字或ReentrantLock)的技术。这种技术可以提高程序的并发性能,尤其是在高并发场景下,因为它减少了锁的竞争和上下文切换的开销。
数据结构与无锁编程
无锁编程通常涉及使用原子操作、CAS(Compare and Swap)指令以及尾部指针等技术来实现线程安全的数据结构。下面是一些常见的无锁数据结构及其在Java中的实现方式:
1. 原子变量
Java提供了AtomicInteger, AtomicLong, AtomicReference等类,它们支持原子操作,可以在不使用锁的情况下更新变量。
2. 无锁队列
例如,ConcurrentLinkedQueue就是一种无锁队列,它使用了CAS操作来保证线程安全。每次插入或删除操作都会尝试修改队列的头部或尾部引用,如果修改失败(因为有其他线程正在修改),则会重试直到成功。
3. 无锁栈
可以使用AtomicReference来实现一个无锁栈。栈顶元素作为AtomicReference对象的值,入栈和出栈操作都通过CAS操作进行。
4. 无锁列表
类似地,可以使用AtomicReference来维护一个双向链表,其中每个节点包含指向下一个节点的AtomicReference字段,这样可以实现线程安全的插入和删除操作。
5. 无锁哈希表
无锁哈希表通常使用细粒度锁或无锁算法实现。例如,ConcurrentHashMap在JDK 8及更高版本中采用了基于数组+链表/红黑树的结构,并且使用了CAS操作和分割锁来实现线程安全。
实现细节
无锁编程的关键在于使用CAS操作。CAS操作是一个原子操作,它尝试将内存位置的值从旧值更新为新值,只有当该位置的值仍然为旧值时才会成功。如果CAS操作失败,则需要重试,直到成功为止。
例如,在实现无锁队列时,入队操作可能如下所示:
public class LockFreeQueue<T> {
private static class Node<T> {
T data;
AtomicReference<Node<T>> next;
public Node(T data) {
this.data = data;
this.next = new AtomicReference<>(null);
}
}
private final AtomicReference<Node<T>> tail = new AtomicReference<>(new Node<>(null));
public void enqueue(T item) {
Node<T> newNode = new Node<>(item);
Node<T> currentTail = tail.get();
while (!currentTail.next.compareAndSet(null, newNode)) {
currentTail = tail.get(); // 重试,因为tail可能已经被更新了
}
tail.compareAndSet(currentTail, newNode); // 更新tail
}
}
无锁编程需要对并发编程有深入的理解,包括了解CPU缓存一致性、内存模型、ABA问题等概念。此外,无锁编程虽然可以提高并发性能,但代码往往更复杂,调试也更加困难。因此,在设计时需要权衡其利弊。
无锁编程在Java中可以通过使用java.util.concurrent.atomic包下的类来实现,这些类提供了原子操作的支持,从而可以构建高性能的并发数据结构。下面我将展示如何使用AtomicReference来实现一个简单的无锁栈。
无锁栈实现
我们将创建一个无锁栈LockFreeStack,它将使用AtomicReference来存储栈顶元素的引用。这个栈将提供push和pop操作。
首先定义一个Node类,用于存储栈中的元素和下一个节点的引用:
static class Node<T> {
final T data;
final AtomicReference<Node<T>> next;
Node(T data) {
this.data = data;
this.next = new AtomicReference<>(null);
}
}
然后是LockFreeStack类的实现:
import java.util.concurrent.atomic.AtomicReference;
public class LockFreeStack<T> {
private final AtomicReference<Node<T>> top = new AtomicReference<>(null);
public void push(T value) {
Node<T> newNode = new Node<>(value);
Node<T> oldTop;
do {
oldTop = top.get();
newNode.next.set(oldTop);
} while (!top.compareAndSet(oldTop, newNode));
}
public T pop() {
Node<T> oldTop, newTop;
do {
oldTop = top.get();
if (oldTop == null) return null; // 栈为空
newTop = oldTop.next.get();
} while (!top.compareAndSet(oldTop, newTop));
return oldTop.data;
}
}
应用案例
为了验证LockFreeStack的正确性和性能,我们可以创建一个多线程环境,其中多个线程同时向栈中添加和移除元素。这将模拟高并发场景下栈的操作。
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
import java.util.stream.IntStream;
public class LockFreeStackTest {
public static void main(String[] args) throws InterruptedException {
LockFreeStack<Integer> stack = new LockFreeStack<>();
ExecutorService executor = Executors.newFixedThreadPool(10);
IntStream.range(0, 10).forEach(i -> {
executor.submit(() -> {
for (int j = 0; j < 1000; j++) {
stack.push(j);
if (stack.size() > 100) { // 模拟随机弹出
stack.pop();
}
}
});
});
executor.shutdown();
executor.awaitTermination(1, TimeUnit.MINUTES);
System.out.println("Final size of the stack: " + stack.size());
}
public int size() {
int size = 0;
for (Node<Integer> node = top.get(); node != null; node = node.next.get()) {
size++;
}
return size;
}
}
在这个例子中,我们创建了一个固定大小的线程池,并让10个线程分别向栈中添加和移除元素。size()方法用于计算栈中元素的数量,以验证最终状态是否正确。
请注意,实际的生产环境中,你可能需要更复杂的错误处理和测试,以确保无锁数据结构在所有情况下都能正确工作。此外,对于像size()这样的辅助方法,也需要采取适当的措施来确保其线程安全性,可能需要重新设计或者使用其他并发工具来实现。
为了更好地理解上述无锁栈LockFreeStack的代码,我们可以使用表格形式逐步分析push和pop操作的过程。这里假设我们有一个初始为空的栈,并且我们将要执行一系列的push和pop操作。
初始状态
| top | next |
|---|---|
| null | N/A |
步骤 1: 第一次 push 操作
假设我们要向栈中push值1。
push操作前的状态
| top | next |
|---|---|
| null | N/A |
push操作过程
- 创建新节点
Node1,数据值为1。 - 将
Node1的next设置为top.get(),此时top.get()返回null。 - 使用
compareAndSet尝试将top的值从null改为Node1。
push操作后的状态
| top | next |
|---|---|
| Node1 | null |
步骤 2: 第二次 push 操作
假设我们要向栈中push值2。
push操作前的状态
| top | next |
|---|---|
| Node1 | null |
push操作过程
- 创建新节点
Node2,数据值为2。 - 将
Node2的next设置为top.get(),此时top.get()返回Node1。 - 使用
compareAndSet尝试将top的值从Node1改为Node2。
push操作后的状态
| top | next |
|---|---|
| Node2 | Node1 |
步骤 3: 第一次 pop 操作
pop操作前的状态
| top | next |
|---|---|
| Node2 | Node1 |
pop操作过程
- 获取
top.get(),此时返回Node2。 - 将
top的值从Node2改为Node2.next.get(),即Node1。
pop操作后的状态
| top | next |
|---|---|
| Node1 | null |
步骤 4: 第三次 push 操作
假设我们要向栈中push值3。
push操作前的状态
| top | next |
|---|---|
| Node1 | null |
push操作过程
- 创建新节点
Node3,数据值为3。 - 将
Node3的next设置为top.get(),此时top.get()返回Node1。 - 使用
compareAndSet尝试将top的值从Node1改为Node3。
push操作后的状态
| top | next |
|---|---|
| Node3 | Node1 |
通过以上步骤,我们可以看到无锁栈是如何通过AtomicReference和compareAndSet方法来保证线程安全地进行push和pop操作的。在多线程环境中,即使有多个线程同时尝试修改栈,由于compareAndSet的原子性,也能确保栈的一致性和完整性。
为了提供一个清晰的视图,让我们将上述步骤整合到一个连续的表格中,以展示LockFreeStack在执行一系列push和pop操作时的状态变化。假设我们的操作序列是:push(1), push(2), pop(), push(3)。
| 操作 | top | top.next | 描述 |
|---|---|---|---|
| 初始 | null |
- | 栈初始化为空 |
push(1) |
Node1 |
null |
创建Node1,数据值为1;top设为Node1 |
push(2) |
Node2 |
Node1 |
创建Node2,数据值为2;top设为Node2 |
pop() |
Node1 |
null |
弹出Node2;top设为Node1 |
push(3) |
Node3 |
Node1 |
创建Node3,数据值为3;top设为Node3 |
这个表格展示了栈在不同操作下的状态转换。每次push操作都会创建一个新的节点,并将其设为新的top,而每次pop操作则会将top的值更新为其next节点,从而实现了栈的基本功能,同时保持了无锁的线程安全特性。
请注意,这个表格简化了AtomicReference和compareAndSet的内部机制,实际的代码会检查当前top的值是否与预期相同,如果相同则更新top,否则重试,以确保操作的原子性和线程安全性。