K最近邻(K-Nearest Neighbors, KNN)理论知识推导
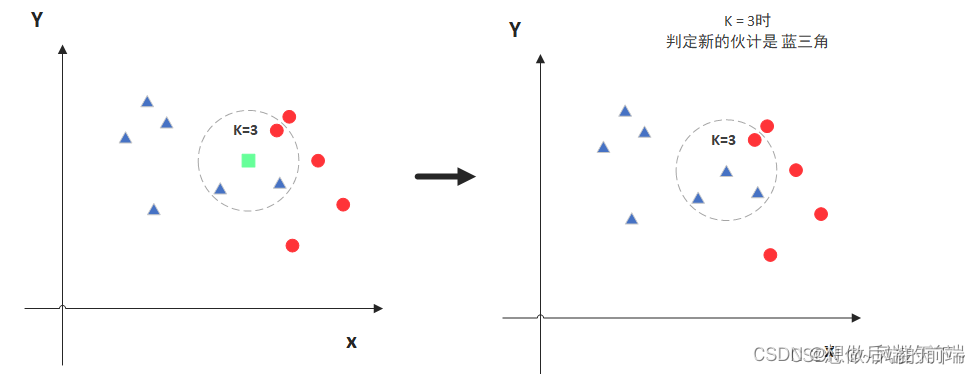
KNN算法是一个简单且直观的分类和回归方法,其基本思想是:给定一个样本点,找到训练集中与其最近的K个样本点,根据这些样本点的类别(分类问题)或值(回归问题)来预测该样本点的类别或值。
距离度量
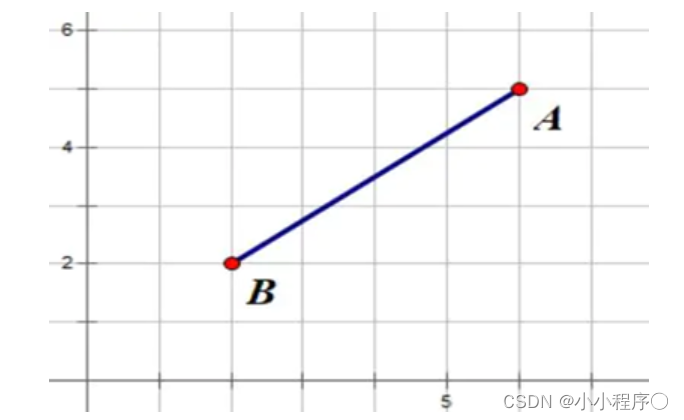
欧氏距离(Euclidean Distance)

曼哈顿距离(Manhattan Distance)
曼哈顿距离也称为L1距离或城市街区距离,适用于连续型和离散型变量。其计算公式为:

切比雪夫距离(Chebyshev Distance)

闵可夫斯基距离(Minkowski Distance)

余弦相似度(Cosine Similarity)
余弦相似度用于度量两个向量之间的角度差异,适用于文本数据和高维稀疏数据。其计算公式为:

汉明距离(Hamming Distance)
汉明距离用于度量两个字符串或向量之间不同字符或元素的数量,适用于离散变量。其计算公式为:

import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 生成随机多维数据
np.random.seed(42)
X = np.random.rand(200, 5)
y = np.random.choice([0, 1], size=200)
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 特征缩放
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 使用欧氏距离的KNN模型
knn_euclidean = KNeighborsClassifier(n_neighbors=3, metric='euclidean')
knn_euclidean.fit(X_train_scaled, y_train)
y_pred_euclidean = knn_euclidean.predict(X_test_scaled)
accuracy_euclidean = accuracy_score(y_test, y_pred_euclidean)
# 使用曼哈顿距离的KNN模型
knn_manhattan = KNeighborsClassifier(n_neighbors=3, metric='manhattan')
knn_manhattan.fit(X_train_scaled, y_train)
y_pred_manhattan = knn_manhattan.predict(X_test_scaled)
accuracy_manhattan = accuracy_score(y_test, y_pred_manhattan)
# 使用切比雪夫距离的KNN模型
knn_chebyshev = KNeighborsClassifier(n_neighbors=3, metric='chebyshev')
knn_chebyshev.fit(X_train_scaled, y_train)
y_pred_chebyshev = knn_chebyshev.predict(X_test_scaled)
accuracy_chebyshev = accuracy_score(y_test, y_pred_chebyshev)
print(f'欧氏距离模型的准确率: {accuracy_euclidean}')
print(f'曼哈顿距离模型的准确率: {accuracy_manhattan}')
print(f'切比雪夫距离模型的准确率: {accuracy_chebyshev}')

选择最近的K个邻居
根据距离排序,选择距离最小的K个样本点。
投票或平均
对于分类问题,对这K个邻居的类别进行投票,得票最多的类别作为预测类别;对于回归问题,对这K个邻居的值取平均,作为预测值。
KNN的优缺点:
优点:
- 简单易实现。
- 不需要模型训练。
- 对噪声数据不敏感(通过选择合适的K值)。
缺点:
- 计算复杂度高,需要计算所有样本点的距离。
- 存储复杂度高,需要存储所有训练数据。
- 对数据的尺度敏感,需要进行标准化处理。
参数解读
n_neighbors:K值,即选择的最近邻居的数量。weights:权重函数,用于预测。常用的有uniform(所有邻居权重相等)和distance(根据距离加权)。metric:距离度量方法,默认是欧氏距离。
实施步骤
- 数据准备:准备训练数据集和测试数据集。
- 特征标准化:对数据进行标准化处理。
- 选择K值和距离度量方法:初始化KNN模型。
- 模型训练:KNN算法不需要训练过程,但需要拟合数据。
- 预测:对测试数据进行预测,并计算准确率或误差。
- 选择K值:K值越小,模型越复杂;K值越大,模型越简单。一般通过交叉验证选择最佳K值。
- 距离度量方法:常用欧氏距离,选择合适的距离度量方法可以提高模型性能。
- 权重:uniform表示所有邻居权重相同,distance表示距离越近的邻居权重越大。
多维KNN模型
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from sklearn.model_selection import GridSearchCV
# 生成多维数据
np.random.seed(42)
X = np.random.rand(100, 3) * 100 # 三维特征数据
y = np.random.choice([0, 1], 100) # 二分类标签
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 初始化KNN分类模型
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
# 预测
y_pred = knn.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f'未优化分类模型的准确率: {accuracy:.2f}')
# 使用网格搜索优化KNN分类模型
param_grid = {'n_neighbors': range(1, 21), 'weights': ['uniform', 'distance']}
grid_search = GridSearchCV(KNeighborsClassifier(), param_grid, cv=5)
grid_search.fit(X_train, y_train)
best_knn = grid_search.best_estimator_
y_pred_optimized = best_knn.predict(X_test)
accuracy_optimized = accuracy_score(y_test, y_pred_optimized)
print(f'优化后分类模型的准确率: {accuracy_optimized:.2f}')
# 可视化三维数据分布和预测结果
fig = plt.figure(figsize=(18, 6))
# 未优化模型结果
ax1 = fig.add_subplot(121, projection='3d')
ax1.scatter(X_test[:, 0], X_test[:, 1], X_test[:, 2], c=y_test, marker='o', label='True Labels')
ax1.scatter(X_test[:, 0], X_test[:, 1], X_test[:, 2], c=y_pred, marker='x', label='Predicted Labels')
ax1.set_title('未优化模型')
ax1.set_xlabel('Feature 1')
ax1.set_ylabel('Feature 2')
ax1.set_zlabel('Feature 3')
ax1.legend()
# 优化后模型结果
ax2 = fig.add_subplot(122, projection='3d')
ax2.scatter(X_test[:, 0], X_test[:, 1], X_test[:, 2], c=y_test, marker='o', label='True Labels')
ax2.scatter(X_test[:, 0], X_test[:, 1], X_test[:, 2], c=y_pred_optimized, marker='x', label='Predicted Labels')
ax2.set_title('优化后模型')
ax2.set_xlabel('Feature 1')
ax2.set_ylabel('Feature 2')
ax2.set_zlabel('Feature 3')
ax2.legend()
plt.show()
可视化展示

警告:D:\PyCharm\PyCharm2024.1.3\plugins\python\helpers\pycharm_matplotlib_backend\backend_interagg.py:80: UserWarning: Glyph 26410 (\N{CJK UNIFIED IDEOGRAPH-672A}) missing from font(s) DejaVu Sans.
FigureCanvasAgg.draw(self)
D:\PyCharm\PyCharm2024.1.3\plugins\python\helpers\pycharm_matplotlib_backend\backend_interagg.py:80: UserWarning: Glyph 20248 (\N{CJK UNIFIED IDEOGRAPH-4F18}) missing from font(s) DejaVu Sans.
FigureCanvasAgg.draw(self)
D:\PyCharm\PyCharm2024.1.3\plugins\python\helpers\pycharm_matplotlib_backend\backend_interagg.py:80: UserWarning: Glyph 21270 (\N{CJK UNIFIED IDEOGRAPH-5316}) missing from font(s) DejaVu Sans.
FigureCanvasAgg.draw(self)
D:\PyCharm\PyCharm2024.1.3\plugins\python\helpers\pycharm_matplotlib_backend\backend_interagg.py:80: UserWarning: Glyph 27169 (\N{CJK UNIFIED IDEOGRAPH-6A21}) missing from font(s) DejaVu Sans.
FigureCanvasAgg.draw(self)
D:\PyCharm\PyCharm2024.1.3\plugins\python\helpers\pycharm_matplotlib_backend\backend_interagg.py:80: UserWarning: Glyph 22411 (\N{CJK UNIFIED IDEOGRAPH-578B}) missing from font(s) DejaVu Sans.
FigureCanvasAgg.draw(self)
D:\PyCharm\PyCharm2024.1.3\plugins\python\helpers\pycharm_matplotlib_backend\backend_interagg.py:80: UserWarning: Glyph 21518 (\N{CJK UNIFIED IDEOGRAPH-540E}) missing from font(s) DejaVu Sans.
FigureCanvasAgg.draw(self)
结果解释
未优化分类模型:
- 准确率:显示未优化模型的分类准确率,通常受初始参数设置的影响。
- 可视化:通过三维散点图展示真实标签和预测标签的分布情况,观察误分类样本的位置。
优化后分类模型:
- 准确率:通过网格搜索优化K值和距离度量方法后,显示优化后的分类准确率,通常高于未优化模型。
- 可视化:通过三维散点图展示真实标签和优化后模型的预测标签分布情况,观察误分类样本的位置。
以上实例展示了KNN算法在未优化和优化后的性能差异,通过适当的参数调优,可以显著提升模型的预测效果。