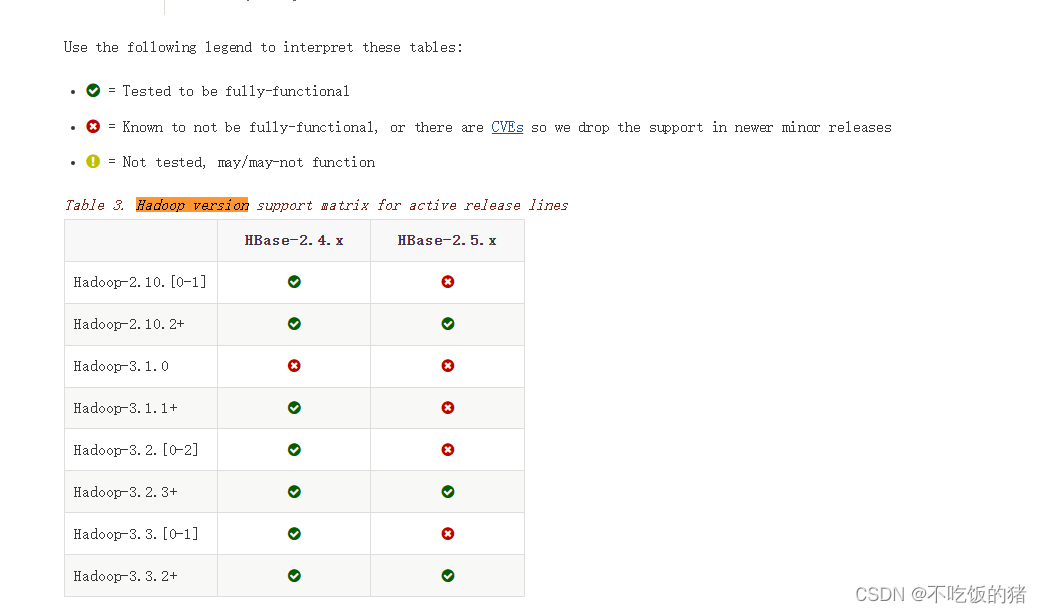
HDFS(Hadoop Distributed File System)、Hive 和 HBase 是 Hadoop 生态系统中三个重要的组件,它们各自解决了大数据存储和处理的不同层面的问题。我们用大白话来解释这三个组件之间的关系:
HDFS - 数据的仓库: HDFS 是一个分布式文件系统,就像是一个巨大的仓库,专门用来存储海量的数据。它把数据分成很多小块,分布在集群中的许多服务器上,这样即使数据量非常大,也能快速访问和处理。HDFS 提供了高容错性和数据冗余,保证数据的可靠性和持久性。
Hive - 数据的管家: Hive 类似于一个数据仓库,它建立在 HDFS 之上,提供了 SQL-like 的查询语言(HiveQL),让数据分析师和开发者可以用类似 SQL 的方式来查询和管理 HDFS 上的大数据。Hive 把复杂的 MapReduce 编程抽象掉了,让用户更专注于数据的业务逻辑,而不是底层的技术细节。它在内部将 SQL 查询转化为 MapReduce 任务执行,使大数据的处理变得更简单。
HBase - 数据的快餐店: HBase 是一个基于 HDFS 的 NoSQL 数据库,它提供了实时读写和随机访问的能力。想象一下,如果你需要快速获取某个特定的数据点,而不用等待整个文件读取完毕,HBase 就是为你准备的。它非常适合于需要低延迟数据读写的场景,比如实时数据流处理或在线服务。HBase 使用列族存储数据,可以水平扩展,支持非常大的数据集。
总结起来,HDFS 是存储数据的基础设施,Hive 是让数据查询变得更简单的工具,而 HBase 是提供快速随机访问和实时数据处理的数据库。它们三者共同构成了 Hadoop 生态系统中存储和处理大数据的核心组件。你可以根据具体的应用场景选择使用其中一个或多个组件,以构建高效的数据处理解决方案。