前置知识:
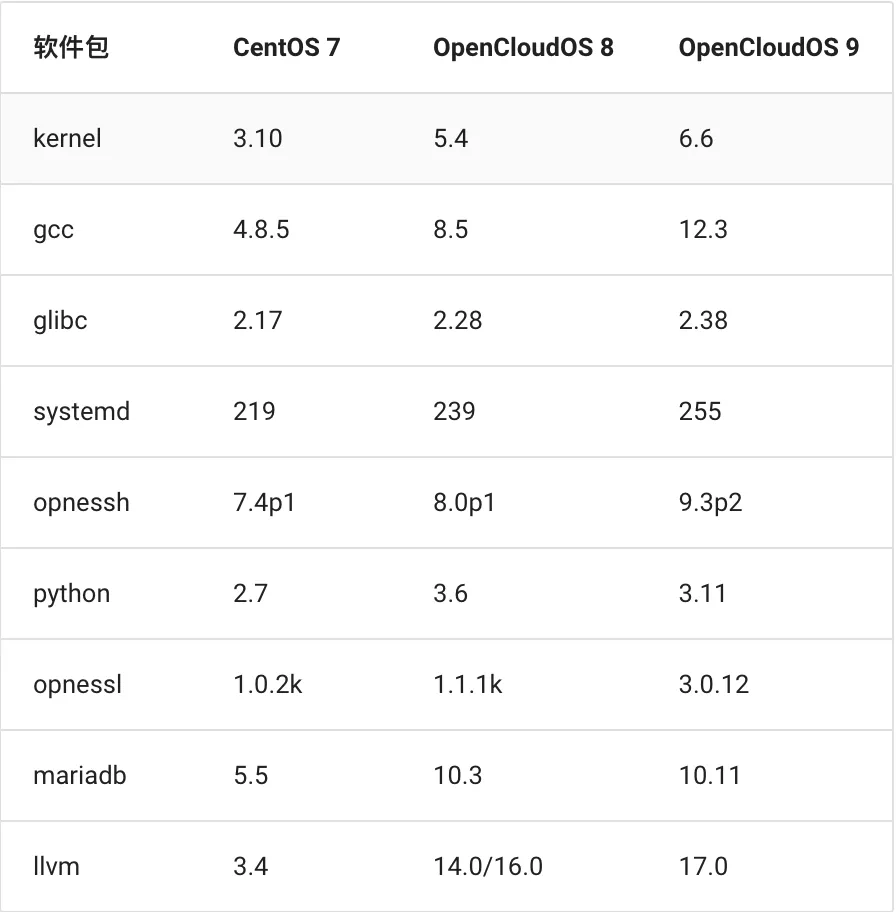
1.self-attention的计算过程
公式:attention(q,k,v)=(softmax(q^T k) / 根号下d_k )v
我们计算的注意力得分是softmax(q^T k),现在针对这个展开
q和k是一个矩阵,维度都是[batch_size, seq_len, num_head, head_dim]。
然后q的某一个token地与k的每个token计算注意力分数,并且累加,得到q的该token与整个k的注意力分数,可以记作qi;这样对于q的所有token都这样做,得到了q的所有token关于k的注意力分数。
2.位置编码
注意力机制是不具备rnn那样的位置敏感性的,没有先后顺序,所以要设置一个位置编码,告诉模型哪个token在哪个token前后。
绝对位置编码就是和词向量层一样大小的位置嵌入,著名的三角函数编码,bert虽然也是用的tranformers,但是其位置编码是可学习的,没有用三角函数编码。
以上的位置信息是在词向量阶段添加的,但是rope是在注意力计算时添加的。
3.复数的不同表达
参见:https://blog.csdn.net/weixin_44604887/article/details/104313666
rope的计算过程

1.对q和k的每个token的语义向量进行复数化,理论上是两两一组,实际操作是前半部分是实数,后半部分是虚数(据说是不影响神经网络)。还有取出其序列上的位置。
2.设置一个对应的角度,采用的是三角函数位置编码的角度(10000^(2i/d),d是语义向量的维度,这里是2.
3.使用位置m和旋转角度对token的复数形式做旋转,得到新的带有位置信息的复数形式的向量,再转为正常形式。使用这个带有位置信息的向量参与q和k的注意力分数计算。
rope的推导
我们的目标是让输入有位置相关性,所以假定m和n位置上的token的语义向量是xm,xn,那么我们要证明的就是m和n是可以用一个函数变换的。

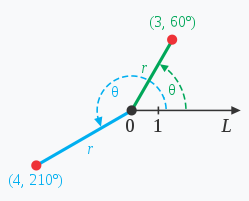
对于语义向量,也就是输入的某一个token的词向量,记作x=[x1,x2,…xn],两两为一个组,转换为复数形式,这样在二维空间上(假定词向量维度是二维)就是一个角a,再执行一个角度(角b)的旋转,就得到了角c,满足角c=角a+角b。
x’=[(x1,ix2), (x3.ix4)…,(x2i-1, x2i)]
就有: