本次文章更新内容,图片以及扫描的PDF也可以支持批量提取指定区域内容了,主要是通过截图指定区域,然后使用OCR来识别该区域的文字来实现的,所以精度可能会有点不够,但是如果是数字的话,问题不大; 所以最好还是纯电子版本的PDF文件提取效果最好。
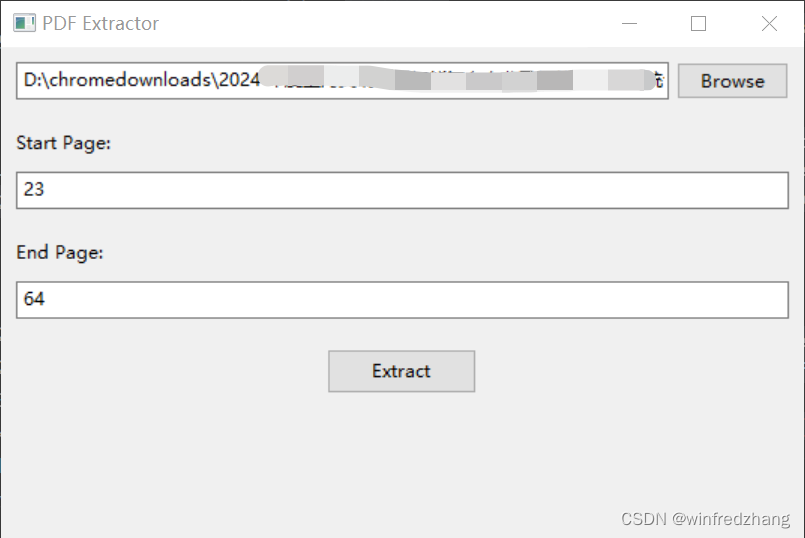
需求1:假如我有一批数量比较多的同样格式的PDF电子文档,需要把特定多个区域的数字或者文字提取出来
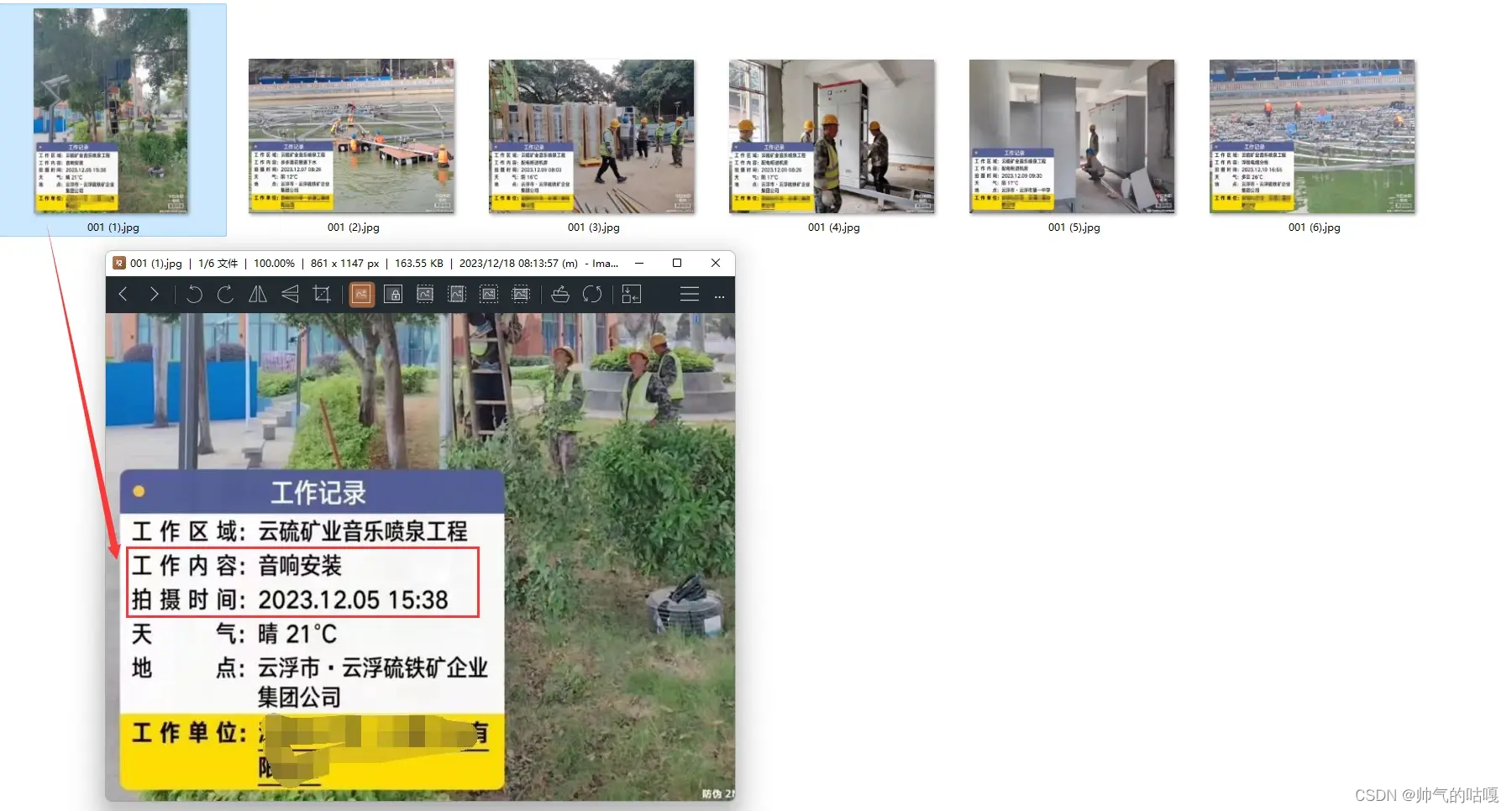
需求2:我有一批PDF文档,但是文件的名称都是一些乱码,我需要根据PDF文件里面第一页内容的第一行的标题文字来批量重命名这些文件
说明:不适应场景:如果多个PDF文件的需要提取内容的区域的位置不一样,比如我要提取的数字在第一个PDF文件在(30,30)的坐标,结果在第二个文件变成了(35,35)这个坐标,那么软件就会无法很好的提取这个内容文本,所以这个代码的适用范围是多个PDF文档格式一致,并且需要提取的文本信息所在的PDF位置都基本一样的情况下适用。
思路1:我们任意选一个PDF文件作为样本,然后用代码把要提取的区域用方框标注出来,再然后把这些区域的坐标保存下来,后续批量处理每个PDF的时候,就根据保存的这些区域坐标来提取对应位置的文字或者数字
思路示意图:

最后的结果示意图:

这种思路的缺陷和需要注意的点:
1 需要每个批量处理的文件要提取的数据的位置都是一样的,比如第一个PDF文件需要提取的数字位于【100,100】这个坐标,那么后续每个文件需要提取的数字都要位于这个位置,如有变动,就会导致提取不到需要的数据,可以通过扩大区域的坐标范围来一定程度上的解决这个问题
2 如果提取的文字不齐全,说明可能框选的方框略微小了一点,我代码里面设置了一个单独增大某个区域的功能
需求2思路:一批PDF文档的名称都是一些乱码,我需要根据PDF文件里面第一页内容的标题来批量重命名这些文件,实际上很简单,就是解析PDF文件,然后获取第一行的内容,然后重命名该文件即可,这个代码不复杂,就没放在本页了。
代码:
from typing import Optional, Dict, List
from solapi.magic_eden.site_api.utils.consts import MEAPIUrls
from solapi.magic_eden.site_api.utils.data import collection_stats_cleaner, collection_info_cleaner, \
collection_list_stats_cleaner
from solapi.magic_eden.site_api.utils.types import MECollectionStats, MECollectionInfo, MECollectionMetrics
from solapi.utils.api import BaseApi
class MagicEdenCollectionApi(BaseApi):
def get_collection_stats_dirty(self, symbol: str) -> Optional[Dict]:
url = f'{MEAPIUrls.COLLECTION_STATS}{symbol}'
res = self._get_request(url)
return res.get('results') if isinstance(res, dict) else None
def get_collection_info_dirty(self, symbol: str) -> Optional[Dict]:
url = f'{MEAPIUrls.COLLECTION_INFO}{symbol}'
res = self._get_request(url)
return res if bool(res) else None
def get_collection_stats(self, symbol: str) -> Optional[MECollectionStats]:
data = self.get_collection_stats_dirty(symbol)
if data:
return collection_stats_cleaner(data)
def get_collection_info(self, symbol: str) -> Optional[MECollectionInfo]:
data = self.get_collection_info_dirty(symbol)
if data:
return collection_info_cleaner(data)
def get_collection_list_stats_dirty(self):
url = MEAPIUrls.COLLECTION_LIST_STATS
res = self._get_request(url)
return res.get('results') if isinstance(res, dict) else None
def get_collection_list_stats(self) -> Optional[List[MECollectionMetrics]]:
data = self.get_collection_list_stats_dirty()
if data:
return list(map(lambda x: collection_list_stats_cleaner(x), data))
def get_collection_list_dirty(self):
url = MEAPIUrls.COLLECTION_LIST
res = self._get_request(url)
return res.get('collections') if isinstance(res, dict) else None
def get_collection_list(self) -> Optional[List[MECollectionInfo]]:
data = self.get_collection_list_dirty()
if data:
return list(map(lambda x: collection_info_cleaner(x), data))代码下载链接:
链接:https://pan.baidu.com/s/1WQQ8kaDilaagjoK5IrYZzA
提取码:1111