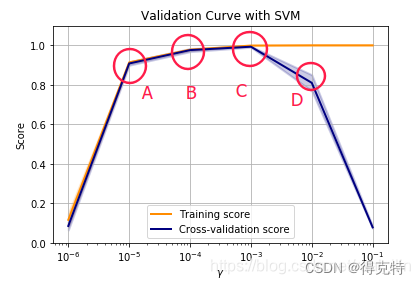
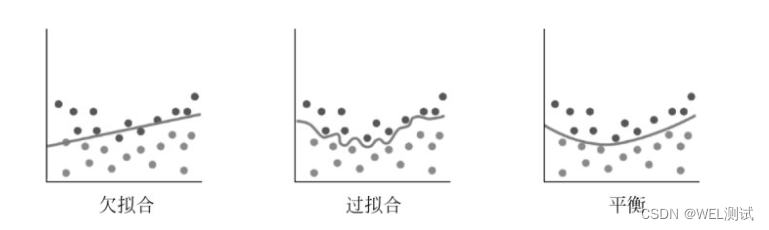
1、欠拟合:对训练集准确率很低。对测试集准确率很低,但与训练集准确率相差不大。
2、过拟合:对训练集准率相当高。对测试集准确率很低。此时学习了训练集中的一些非泛化的独有特征。
3、既欠拟合,又过拟合:对训练集准确率很低,对测试集准确率很低,并且测试集准确率与训练集准确率相差也较大。
示例:
- 训练集准确率85%,验证集准确率84%:欠拟合
- 训练集准确率99%,验证集准确率89%:过拟合
- 训练集准确率85%,验证集准确率70%:既过拟合,又欠拟合
如何解决?
1、解决欠拟合
训练过程中会表现出来,比较好发现与解决
- 网络加强(层数、神经元个数)
- 增加训练次数
- 优化算法
- 更换神经网络架构
2、解决过拟合
难发现也难解决
- 增加训练数据
- 正则化
- 更换神经网络架构
- 提前终止迭代
- 权值共享
- 增加噪声,输入数据增加可以增大数据的多样性,权值上增加类似于正则化
解决思路:增大数据、降低复杂度
3、同时解决欠拟合与过拟合
往往解决了欠拟合,过拟合问题又出来了,解决了过拟合问题,欠拟合问题又出来了。
- 找到合适的架构可以同时解决
- 再使用合适的正则化后,使用更大的网络增加更多的数据即可同时解决。