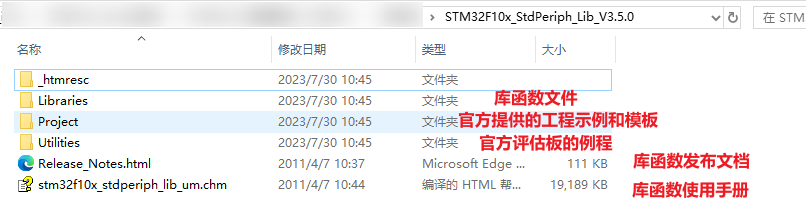
1. 使用 std::string::find
std::string::find 是由标准库实现的,经过了优化,性能较好。实测效率高,推荐使用。
int findSubstringpos(const std::string& str, const std::string& substring) {
size_t pos = str.find(substring);
if (pos != std::string::npos) {
return static_cast<int>(pos);
}
return -1;
}
2. 使用 std::search
std::search 是 C++ 标准库中的一个算法,属于泛型编程的范畴。它能够在容器的任意范围内查找子序列。泛型编程的核心思想是编写代码,使其能够处理不同类型的容器和迭代器,而不依赖于具体的容器实现。
int findSubstringpos(const std::string& str, const std::string& substring) {
auto iter = std::search(str.begin(), str.end(), substring.begin(), substring.end());
if (iter != str.end()) {
return static_cast<int>(iter - str.begin());
}
return -1;
}
3. 使用双指针暴力搜索
int findSubstringpos(const std::string& str, const std::string& substring) {
for (int i = 0; i <= static_cast<int>(str.size()) - static_cast<int>(substring.size()); ++i) {
int j = 0;
for (; j < substring.size(); ++j) {
if (str[i + j] != substring[j]) {
break;
}
}
if (j == substring.size()) {
return i;
}
}
return -1;
}
4、KMP算法实现
效率高,实现复杂。
// 函数:计算子串的前缀表(部分匹配表)
std::vector<int> computePrefixFunction(const std::string& pattern) {
int m = pattern.size();
std::vector<int> lps(m, 0); // Longest Prefix Suffix
int length = 0; // Length of the previous longest prefix suffix
int i = 1;
while (i < m) {
if (pattern[i] == pattern[length]) {
length++;
lps[i] = length;
i++;
} else {
if (length != 0) {
length = lps[length - 1];
} else {
lps[i] = 0;
i++;
}
}
}
return lps;
}
// 函数:使用 KMP 算法查找子串在主字符串中的位置
int findSubstringpos(const std::string& str, const std::string& substring) {
int n = str.size();
int m = substring.size();
if (m == 0) return 0; // 空子串情况
std::vector<int> lps = computePrefixFunction(substring);
int i = 0; // 索引 for str
int j = 0; // 索引 for substring
while (i < n) {
if (substring[j] == str[i]) {
i++;
j++;
}
if (j == m) {
return i - j; // 返回子串的起始位置
}
if (i < n && substring[j] != str[i]) {
if (j != 0) {
j = lps[j - 1];
} else {
i++;
}
}
}
return -1; // 如果未找到子串
}



























![[Unity]碰撞器的接触捕获层详解](https://i-blog.csdnimg.cn/direct/df2b72e1c4474a708ea16228a8c491dd.png)