理解KMP算法的核心思想:
- KMP算法的核心思想是利用已经部分匹配的信息,避免在主字符串中进行不必要的回溯。
- 在匹配过程中,如果当前字符匹配失败,利用已经匹配的部分,尽量减少比较的次数。
理解部分匹配值(Partial Match Table):
- 部分匹配值是模式字符串的一个重要概念,表示在模式字符串中,前缀和后缀相等的最长长度。
- 计算部分匹配值的过程是KMP算法的关键之一。
编写计算部分匹配值的方法:
- 实现一个方法,输入模式字符串,输出部分匹配值数组(也称为最长相等前缀后缀数组)。
- 可以使用一个循环来计算每个位置的部分匹配值,根据当前字符是否与前一个字符匹配来更新部分匹配值。
编写indexOf方法:
- 在indexOf方法中,利用计算得到的部分匹配值数组来辅助匹配过程。
- 使用两个指针i和j分别指向主字符串和模式字符串的当前位置,根据当前字符是否匹配来移动指针。
- 如果匹配失败,则根据部分匹配值数组来决定j应该回溯到哪个位置。
- 当j移动到模式字符串的末尾时,表示找到了匹配的位置。
测试:
- 编写测试用例,包括匹配成功和失败的情况,确保实现的indexOf方法能够正确地找到模式字符串在主字符串中的位置。
优化:
- 对于计算部分匹配值的方法和indexOf方法进行性能优化,尽量减少不必要的比较和计算,提高算法效率。
通过以上步骤,你可以逐步理解和实现KMP算法,实现一个高效的字符串查找方法。
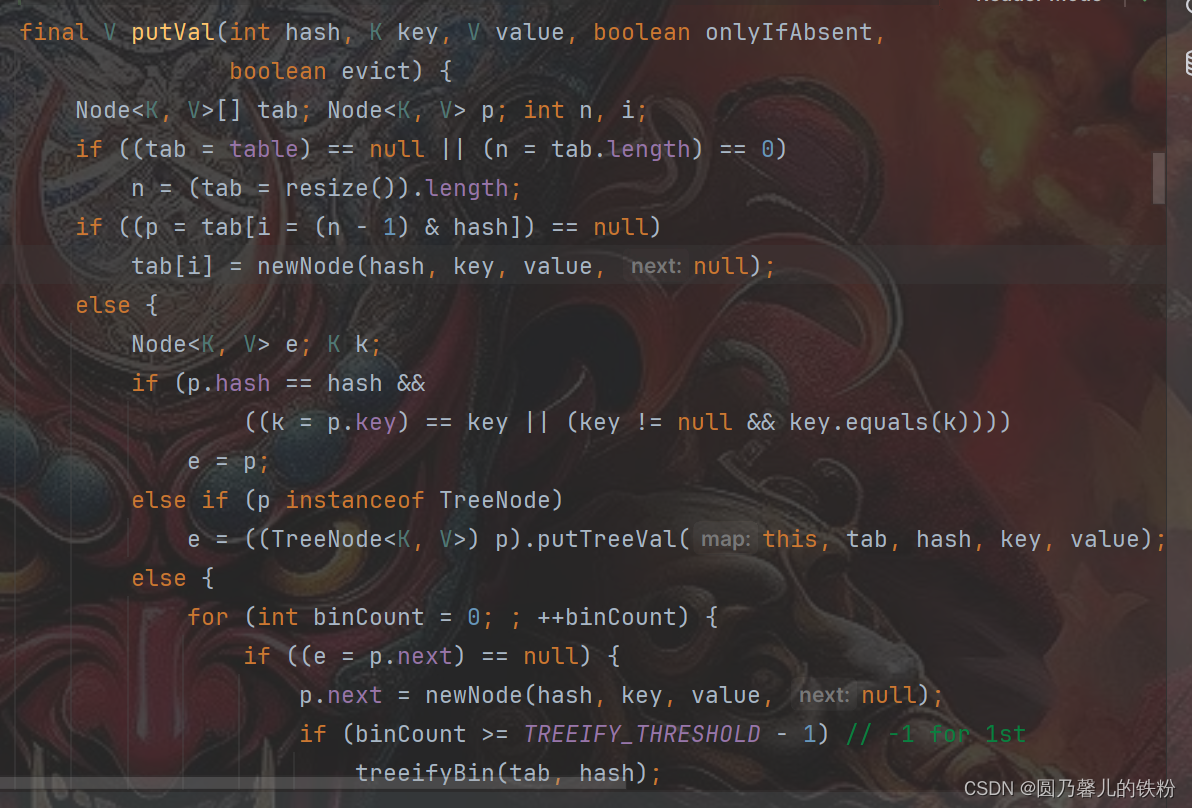
public int[] getNext(String needle) {
int[] next = new int[needle.length()];
int j = 0;
for (int i = 1; i < next.length;) {
if (needle.charAt(i) == needle.charAt(j)) {
next[i] = j + 1;
i++;
j++;
} else if (j == 0) {
next[i] = 0;
i++;
} else {
j = next[j - 1];
}
}
return next;
}
public int strStr(String haystack, String needle) {
if (needle.isEmpty()) return 0; // 处理特殊情况
char[] haystacks = haystack.toCharArray();
char[] needles = needle.toCharArray();
int[] next = getNext(needle);
int j = 0;
for (int i = 0; i < haystacks.length; ) {
if (haystacks[i] == needles[j]) {
i++;
j++;
} else if (j == 0) {
i++;
} else {
j = next[j - 1];
}
if (j == needles.length) {
return i - needles.length;
}
}
return -1;
}![[<span style='color:red;'>算法</span><span style='color:red;'>每日</span><span style='color:red;'>一</span><span style='color:red;'>练</span>]-双指针 (保姆级教程篇 1) #A-B数<span style='color:red;'>对</span> #求和 #元音字母 #最短连续<span style='color:red;'>子</span>数组 #无重复字符的最长子<span style='color:red;'>串</span> #最小子<span style='color:red;'>串</span>覆盖 #方块桶](https://img-blog.csdnimg.cn/direct/0f587523dead4d158a3c637428eddd91.png)


![字符串匹配/<span style='color:red;'>查找</span>字符串中子<span style='color:red;'>串</span>存在次数/出现<span style='color:red;'>位置</span>下标 问题----- {1.[find] 2.[substr] 3.[<span style='color:red;'>kmp</span>]}](https://img-blog.csdnimg.cn/direct/63ff4f196f1d44ba9505047d78e3a20f.png)