新书速览|PyTorch深度学习与企业级项目实战-CSDN博客
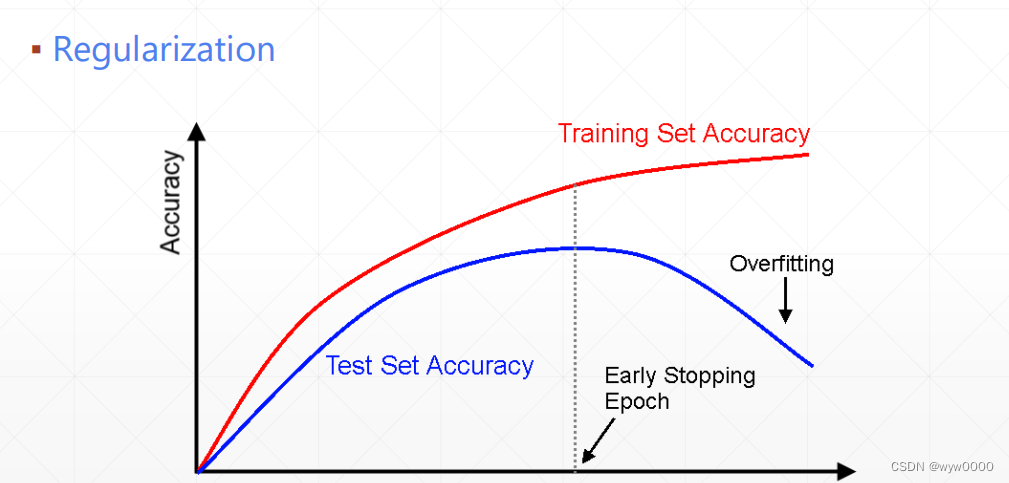
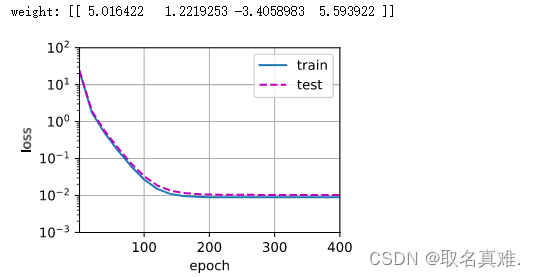
随着迭代次数的增加,我们可以发现测试数据的loss值和训练数据的loss值存在着巨大的差距, 如图4-8所示,随着迭代次数的增加,training loss越来越好,但test loss却越来越差,test loss 和 training loss的差距越来越大,模型开始过拟合。过拟合会导致模型在训练集上的表现很好,但针对验证集或测试集,表现却大打折扣。

图4-8
如图4-9所示,Dropout是指在深度学习网络的训练过程中,按照一定的概率将一部分神经网络单元暂时从网络中丢弃,相当于从原始的网络中找到一个更瘦的网络,从而解决过拟合问题。

图4-9
做个类比,无性繁殖可以保留大段的优秀基因,而有性繁殖则将基因随机拆了又拆,破坏了大段基因的联合适应性,但是自然选择中选择了有性繁殖,“物竞天择,适者生存”,可见有性繁殖的强大。Dropout 也能达到同样的效果,它强迫一个神经元和随机挑选出来的其他神经元共同工作,消除并减弱了神经元节点间的联合适应性,增强了泛化能力。
如果一个公司的员工每天早上都是扔硬币决定今天去不去上班,那么这个公司会运作良好吗?这并非没有可能,这意味着任何重要的工作都会有替代者,不会只依赖于某一个人。同样员工也会学会和公司内各种不同的人合作,而不是每天面对固定的人,每个员工的能力也会得到提升。这个想法虽然不见得适用于企业管理,但却绝对适用于神经网络。
在进行Dropout后,一个神经元不得不与随机挑选出来的其他神经元共同工作,而不是原先一些固定的周边神经元。这样经过几轮训练,这些神经元的个体表现力大大增强,同时也减弱了神经元节点间的联合适应性,增强了泛化能力。我们知道通常是在训练神经网络的时候使用Dropout,这样会降低神经网络的拟合能力,而在预测的时候则关闭Dropout。这就好像在练轻功的时候在脚上绑着很多重物,但是在真正和别人打的时候会把重物全拿走,这样一下子就感觉变强了很多。