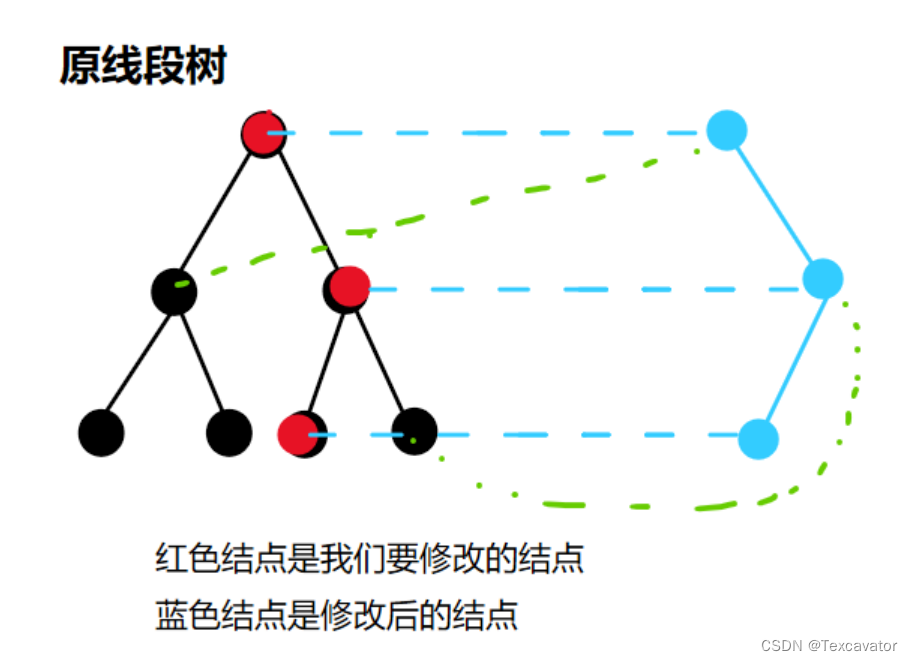
可持久化数据结构
定义
可持久化数据结构(Persistent Data Structure)是一种在修改时不会改变原有状态的数据结构。每次对数据结构的更新都会产生一个新的版本,而旧版本仍然可用。这种特性使得可持久化数据结构非常适合处理历史版本控制、回滚操作、多线程环境和函数式编程语言。
运用情况
- 版本控制系统:例如Git,在提交新版本时,只保存改动的部分,而非整个文件系统。
- 数据库事务管理:事务的回滚或恢复需要数据结构保持不变性。
- 并行计算与分布式系统:在多线程或分布式环境中,避免数据竞争和一致性问题。
- 游戏开发:用于快速回放或保存游戏状态。
- 算法竞赛:解决一些动态规划或区间查询问题,如树状数组的可持久化版本。
注意事项
- 内存消耗:由于每次修改都创建新的副本,可能会导致较高的内存使用。
- 性能影响:创建新版本的操作可能比直接修改现有结构要慢,特别是在大规模数据集上。
- 垃圾回收:在不使用旧版本后,及时清理不再需要的旧数据结构以释放内存。
- 设计复杂性:实现可持久化数据结构通常比普通数据结构更复杂。
解题思路
- 识别需求:确定问题是否需要历史记录、回滚或并发访问。
- 选择合适的数据结构:考虑使用哪些基本数据结构(如数组、链表、树等)作为基础,并研究如何使其可持久化。
- 实现策略:
- 使用路径复制(Path Copying):仅复制需要修改的节点及其后代。
- 实现共享结构:新版本尽可能重用旧版本中的未改动部分。
- 优化性能:
- 考虑使用懒惰更新(Lazy Propagation),即延迟实际的更新操作直到真正需要时才进行。
- 采用差分压缩(Delta Encoding),存储新旧版本之间的差异。
- 测试与调试:确保新旧版本正确无误,且在修改后所有必要的数据都被正确更新。
AcWing 255. 第K小数
题目描述

运行代码
#include <bits/stdc++.h>
using namespace std;
const int N = 100010, M = 10010;
int n, m;
int a[N];
int root[N], idx;
vector<int> nums;
struct Node
{
int l, r;
int cnt;
}tr[N * 4 + N *17];
int find(int x)
{
return lower_bound(nums.begin(), nums.end(), x) - nums.begin();
}
int build(int l, int r)
{
int p = ++ idx;
if(l == r) return p;
int mid = l + r >> 1;
tr[p].l = build(l, mid), tr[p].r = build(mid + 1, r);
return p;
}
int insert(int p, int l, int r, int x)
{
int q = ++ idx;
tr[q] = tr[p];
if(l == r)
{
tr[q].cnt ++;
return q;
}
int mid = l + r >> 1;
if(x <= mid) tr[q].l = insert(tr[p].l, l, mid, x);
else tr[q].r = insert(tr[p].r, mid + 1, r, x);
tr[q].cnt = tr[tr[q].l].cnt + tr[tr[q].r].cnt;
return q;
}
int query(int p, int q, int l, int r, int k)
{
if(l == r) return l;
int cnt = tr[tr[q].l].cnt - tr[tr[p].l].cnt;
int mid = l + r >> 1;
if(k <= cnt) return query(tr[p].l, tr[q].l, l, mid, k);
else return query(tr[p].r, tr[q].r, mid + 1, r, k - cnt);
}
int main()
{
cin >> n >> m;
for(int i = 1; i <= n; i ++ )
{
cin >> a[i];
nums.push_back(a[i]);
}
sort(nums.begin(), nums.end());
nums.erase(unique(nums.begin(), nums.end()), nums.end());
root[0] = build(0, nums.size() - 1);
for(int i = 1; i <= n; i ++ )
root[i] = insert(root[i - 1], 0, nums.size() - 1, find(a[i]));
int l, r, k;
while(m -- )
{
cin >> l >> r >> k;
cout << nums[query(root[l - 1], root[r], 0, nums.size() - 1, k)] << endl;
}
return 0;
}代码思路
初始化:
N和M定义了数组和查询的最大尺寸。a[]存储原始数组。root[]存储每个时间点的线段树根节点。idx是一个全局变量,用于分配新的节点ID。nums是一个向量,用于存储原始数组中出现的所有唯一值。
辅助函数:
find()函数用于查找某个值在nums向量中的位置,这里使用了二分查找(lower_bound)。build()函数用于构建初始的线段树,递归地构建左子树和右子树。insert()函数用于插入新元素并创建线段树的新版本,它会从给定的节点复制信息并修改指定位置的计数。query()函数用于查找区间内的第k小元素,它通过比较左右子树的元素数量来递归定位。
主函数流程:
- 输入数组大小
n和查询次数m。 - 读取数组
a[]并将元素添加到nums向量中。 - 对
nums向量进行排序并去除重复元素,这一步是为了将数组元素映射为连续的整数,简化后续处理。 - 构建初始线段树,其覆盖范围是
nums向量的索引范围。 - 遍历输入数组,每次调用
insert()更新线段树,形成新的版本,并将其根节点存储在root[]中。 - 处理查询,读入查询参数
l,r,k,然后调用query()函数找到区间[l, r]内的第k小元素的位置,并输出对应的值。
- 输入数组大小
关键概念:
- 可持久化:每次修改线段树时,都生成一个新的树版本,而不破坏旧版本。
- 线段树:用于高效地查询和更新区间信息,这里用于统计区间内的元素数量。
- 离散化:通过排序和去重,将原数组元素映射为连续的整数,便于在线段树中处理。
改进思路
1. 压缩空间的可持久化
目前的实现中,每个节点都有完整的左子树和右子树,这可能导致较大的内存消耗。可以采用路径压缩的策略,只复制被修改的节点及其祖先,这样可以显著减少内存使用。
2. 懒惰传播优化
如果线段树支持范围更新操作,可以引入懒惰传播技术,避免不必要的节点更新,从而提高更新效率。
3. 更高效的排序与离散化
目前使用 sort 和 unique 进行离散化,可以考虑更高效的排序算法(如基数排序或桶排序)来处理整数值,或者使用线性时间的计数排序(如果值域不是特别大)。此外,可以尝试使用哈希表来加速离散化过程,尽管这可能增加额外的时间复杂度。
4. 查询优化
在 query 函数中,可以通过一些预处理或缓存机制来加速特定类型的查询。例如,如果某些查询模式是已知的,可以预先计算一些统计数据来加速这些查询。
5. 并行处理
如果处理的数据集非常大,可以考虑利用多核处理器的并行处理能力。例如,在构建线段树或处理多个查询时,可以使用多线程技术。
6. 异常处理与健壮性
增加对输入错误的检查和处理,比如确保输入的边界条件正确,以及处理可能的溢出情况。
7. 动态更新
当前实现假设数组不会改变,但如果需要动态更新数组,可以扩展算法以支持在查询之间插入或删除元素。
8. 代码清晰性与可维护性
虽然代码效率很重要,但保持代码的清晰性和可维护性同样关键。可以考虑重构代码,使其更易于理解,例如通过添加更多的注释、使用更具描述性的变量名和函数名等。
9. 模板化
可以将可持久化线段树封装成一个模板类,以便于在不同的项目中重用,同时允许用户指定特定的数据类型和操作。
10. 测试与调试
实现单元测试和压力测试,确保在各种边界条件下算法的正确性和性能。