这一篇文章我们就开始数据结构知识的学习!
数据结构前言
数据结构
我们学习计算机相关内容的时候,都听说过数据结构,那么什么是数据结构呢?
数据结构(Data Structure)是 计算机存储、组织数据的⽅式 ,指 相互之间存在⼀种或多种特定关系的数据元素的集合 。
没有⼀种单⼀的数据结构对所有⽤途都有⽤,所以我们要学各式各样的数据结构, 如:线性表、树、图、哈希等。
算法
算法(Algorithm):定义 良好的计算过程 ,他 取⼀个或⼀组的值为输⼊ ,并 产⽣出⼀个或⼀组值作为输出 。简单来说 算法就是⼀系列的计算步骤,⽤来将输⼊数据转化成输出结果 。
算法效率
既然是一系列的计算步骤,那么如何衡量⼀个算法的好坏呢?
算法在编写成可执⾏程序后,运⾏时需要 耗费时间资源和空间(内存)资源 。因此衡量⼀个算法的好 坏,⼀般是从 时间 和 空间 两个维度来衡量的,即 时间复杂度 和 空间复杂度 。
那么这两个维度来衡量算法有什么区别呢?
时间复杂度 主要衡量⼀个算法的 运⾏快慢空间复杂度 主要衡量⼀个算法 运⾏所需要的额外空间
在计算机发展的早期,计算机的存储容量很⼩,所以对空间复杂度很是在乎。但是经过计算机⾏业的 迅速发展,计算机的存储容量已经达到了很⾼的程度。所以我们如今已经不需要再特别关注⼀个算法 的空间复杂度。
时间复杂度
定义:在计算机科学中, 算法的时间复杂度是⼀个函数式T(N) ,它 定量描述了该算法的运⾏时间。
T(N)函数式计算的是程序的执⾏次数。通过c语⾔编译链接的学习,算法程序被编译后⽣成⼆进制指令,程序运⾏,就是cpu执⾏这 些编译好的指令。那么我们通过程序代码或者理论思想计算出程序的执⾏次数的函数T(N),假设每 句指令执⾏时间基本⼀样(实际中有差别,但是微乎其微),那么 执⾏次数和运⾏时间就是等⽐正相关 , 这样也脱离了具体的编译运⾏环境。执⾏次数就可以代表程序时间效率的优劣。 ⽐如解决⼀个问题的 算法a程序T(N) = N,算法b程序T(N) = N^2,那么算法a的效率⼀定优于算法b 时 间
复杂度是衡量程序的时间效率,那么为什么不去计算程序的运⾏时间呢?
1. 因为程序运⾏时间和编译环境和运⾏机器的配置都有关系,⽐如同⼀个算法程序,⽤⼀个⽼编译 器进⾏编译和新编译器编译,在同样机器下运⾏时间不同。2. 同⼀个算法程序,⽤⼀个⽼低配置机器和新⾼配置机器,运⾏时间也不同。3. 并且时间只能程序写好后测试,不能写程序前通过理论思想计算评估。
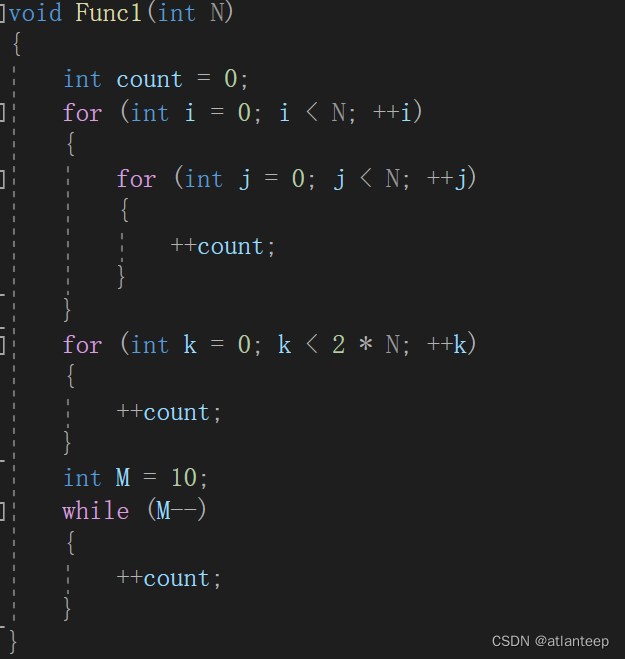
那么下面这一段代码中,++count语句一共执行了多少次呢?
void Func1(int N)
{
int count = 0;
for (int i = 0; i < N ; ++ i)
{
for (int j = 0; j < N ; ++ j)
{
++count;
}
}
//外层循环:i——> 0 1 2 3 4 5 6 7 ……………… N-1 N
//内存循环: N N N N N N N N …………………N 0(++count每次外层循环进来执行N次)
//++count执行了N*N次
for (int k = 0; k < 2 * N ; ++ k)
{
++count;
}
//++count执行了2N次
int M = 10;
while (M--)
{
++count;
}
//++count执行了M(10)次
}通过分析,我们可以知道++count语句执行了N*N+2*N+10次
T ( N ) = N * N + 2 ∗ N + 10
• N = 10 T(N) = 130
• N = 100 T(N) = 10210
• N = 1000 T(N) = 1002010
通过对N取值分析,对结果影响最⼤的⼀项是N*N
在实际中我们 计算时间复杂度 时,计算的 不是程序的精确的执⾏次数 ,精确执⾏次数计算起来比较 ⿇烦(不同的⼀句程序代码,编译出的指令条数都是不⼀样的),计算出精确的执⾏次数意义也不⼤, 因为我们计算时间复杂度只是想⽐较算法程序的增⻓量级,也就是当N不断变⼤时T(N)的差别。
通过上面的分析,我 们看到当N不断变⼤(趋向于无穷大时)时, 常数和低阶项对结果的影响很⼩ ,所以我们只需要计算程序能代表增⻓量 级的⼤概执⾏次数。
大O的渐进表示法
复杂度的表示通常使⽤⼤O的渐进表示法。
⼤O符号(Big O notation):是⽤于描述函数渐进⾏为的数学符号
我们接下来一起来看看 推导⼤O阶规则:
1. 时间复杂度函数式 T(N) 中, 只保留最⾼阶项 ,去掉那些低阶项,因为当 N 不断变⼤时, 低阶项对结果影响越来越⼩,当 N ⽆穷⼤时,就可以忽略不计低阶项。2. 如果最 ⾼阶项存在且不是1 ,则 去除这个项⽬的常数系数 ,因为当 N 不断变⼤,这个系数对结果影响越来越⼩,当 N ⽆穷⼤时,就可以忽略不计了。3. T(N) 中如果没有 N 相关的项⽬, 只有常数项 ,⽤ 常数1取代所有加法常数(在我们看来一个很大的常数,比如100000000000,在计算机看来也是影响很小的,与常数1的效果差不多)
示例1
// 计算Func2的时间复杂度?
void Func2(int N)
{
int count = 0;
for (int k = 0; k < 2 * N ; ++ k)
{
++count;
}
int M = 10;
while (M--)
{
++count;
}
printf("%d\n", count);
}
Func2执⾏的基本操作次数:T ( N ) = 2 N + 10
根据推导规则得出Func2的时间复杂度为: O ( N )
(保留高阶项2N, 2作为常数系数可以省略,所以时间复杂度为O(N)
示例2
// 计算Func3的时间复杂度?
void Func3(int N, int M)
{
int count = 0;
for (int k = 0; k < M; ++ k)
{
++count;
}
for (int k = 0; k < N ; ++k)
{
++count;
}
printf("%d\n", count);
}
Func3执⾏的基本操作次数:T ( N ) = M+N
根据推导规则得出:
如果M>>N(M远远大于N) ,Func3的时间复杂度为:O(M)
如果M<<N(M远远小于N) ,Func3的时间复杂度为:O(N)
如果M==N(M近似等于N) ,Func3的时间复杂度为:O(M+N )
示例3
// 计算Func4的时间复杂度?
void Func4(int N)
{
int count = 0;
for (int k = 0; k < 100; ++ k)
{
++count;
}
printf("%d\n", count);
}Func4执⾏的基本操作次数:T (N) = 100
根据推导规则得出:Func3的时间复杂度为:O(1)
(100为常数项,用常数1来取代常数)
示例4
// 计算strchr的时间复杂度?
const char * strchr ( const char* str, int character)
{
const char* p_begin = str;
while (*p_begin != character)
{
if (*p_begin == '\0')
return NULL;
p_begin++;
}
return p_begin;
}这一段代码是在一个字符串中找到我们想要的字符
strchr执⾏的基本操作次数:
(1)若要查找的字符在字符串第⼀个位置,则: T ( N ) = 1
(2)若要查找的字符在字符串最后的⼀个位置, 则: T ( N ) = N
(3)若要查找的字符在字符串中间位置,则: T ( N ) = N / 2
strchr的时间复杂度分为:
最好情况: O (1)
最坏情况: O ( N )
平均情况: O ( N ) (1/2高阶项系数可以忽略不计)
通过上⾯我们会发现,有些算法的时间复杂度存在最好、平均和最坏情况。最坏情况:任意输⼊规模的 最⼤运⾏次数(上界)平均情况:任意输⼊规模的 期望运⾏次数最好情况:任意输⼊规模的 最⼩运⾏次数(下界)⼤O的渐进表⽰法 在实际中⼀般情况 关注的是算法的上界 ,也就是 最坏运⾏情况 。
示例5
// 计算BubbleSort的时间复杂度?
void BubbleSort(int* a, int n)
{
assert(a);
for (size_t j = 0; j < n - 1; j++)
{
int exchange = 0;
for (size_t i = 0; i < n - 1 - j; i++)
{
if (a[i + 1] < a[i])
{
Swap(&a[i + 1], &a[i]);
exchange = 1;
}
}
if (exchange == 0)
break;
}
}
外层循环:j——> 0 1 2 3…………n-3 n-2 n-1
内层循环次数: n-1 n-2 n-3 n-4……… 2 1 0
1)若数组有序,则:T ( N ) = N - 1
2)若数组有序且为降序,则:T ( N ) = N ∗ ( N - 1) /2
3)若要查找的字符在字符串中间位置,则:
因此:BubbleSort的时间复杂度取最差情况为: O ( N^ 2 )==O(N*N)