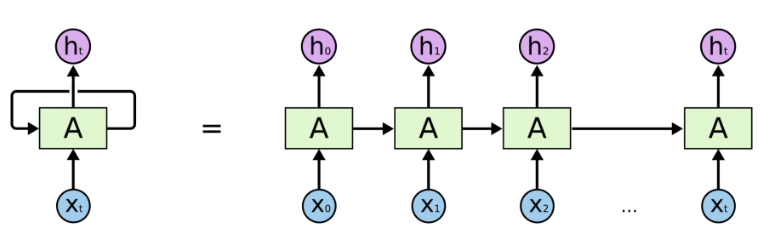
内容介绍:
情感分类是自然语言处理中的经典任务,是典型的分类问题。本节使用MindSpore实现一个基于RNN网络的情感分类模型,实现如下的效果:
输入: This film is terrible
正确标签: Negative
预测标签: Negative
输入: This film is great
正确标签: Positive
预测标签: Positive具体内容:
1. 导包
import os
import shutil
import requests
import tempfile
from tqdm import tqdm
from typing import IO
from pathlib import Path
import re
import six
import string
import tarfile
import mindspore.dataset as ds
import zipfile
import numpy as np
import mindspore as ms
import math
import mindspore as ms
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore.common.initializer import Uniform, HeUniform
2. 数据下载
# 指定保存路径为 `home_path/.mindspore_examples`
cache_dir = Path.home() / '.mindspore_examples'
def http_get(url: str, temp_file: IO):
"""使用requests库下载数据,并使用tqdm库进行流程可视化"""
req = requests.get(url, stream=True)
content_length = req.headers.get('Content-Length')
total = int(content_length) if content_length is not None else None
progress = tqdm(unit='B', total=total)
for chunk in req.iter_content(chunk_size=1024):
if chunk:
progress.update(len(chunk))
temp_file.write(chunk)
progress.close()
def download(file_name: str, url: str):
"""下载数据并存为指定名称"""
if not os.path.exists(cache_dir):
os.makedirs(cache_dir)
cache_path = os.path.join(cache_dir, file_name)
cache_exist = os.path.exists(cache_path)
if not cache_exist:
with tempfile.NamedTemporaryFile() as temp_file:
http_get(url, temp_file)
temp_file.flush()
temp_file.seek(0)
with open(cache_path, 'wb') as cache_file:
shutil.copyfileobj(temp_file, cache_file)
return cache_pathimdb_path = download('aclImdb_v1.tar.gz', 'https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/aclImdb_v1.tar.gz')
imdb_path3. 数据集加载
class IMDBData():
"""IMDB数据集加载器
加载IMDB数据集并处理为一个Python迭代对象。
"""
label_map = {
"pos": 1,
"neg": 0
}
def __init__(self, path, mode="train"):
self.mode = mode
self.path = path
self.docs, self.labels = [], []
self._load("pos")
self._load("neg")
def _load(self, label):
pattern = re.compile(r"aclImdb/{}/{}/.*\.txt$".format(self.mode, label))
# 将数据加载至内存
with tarfile.open(self.path) as tarf:
tf = tarf.next()
while tf is not None:
if bool(pattern.match(tf.name)):
# 对文本进行分词、去除标点和特殊字符、小写处理
self.docs.append(str(tarf.extractfile(tf).read().rstrip(six.b("\n\r"))
.translate(None, six.b(string.punctuation)).lower()).split())
self.labels.append([self.label_map[label]])
tf = tarf.next()
def __getitem__(self, idx):
return self.docs[idx], self.labels[idx]
def __len__(self):
return len(self.docs)imdb_train = IMDBData(imdb_path, 'train')
len(imdb_train)def load_imdb(imdb_path):
imdb_train = ds.GeneratorDataset(IMDBData(imdb_path, "train"), column_names=["text", "label"], shuffle=True, num_samples=10000)
imdb_test = ds.GeneratorDataset(IMDBData(imdb_path, "test"), column_names=["text", "label"], shuffle=False)
return imdb_train, imdb_testimdb_train, imdb_test = load_imdb(imdb_path)
imdb_train4. 加载预训练词向量
def load_glove(glove_path):
glove_100d_path = os.path.join(cache_dir, 'glove.6B.100d.txt')
if not os.path.exists(glove_100d_path):
glove_zip = zipfile.ZipFile(glove_path)
glove_zip.extractall(cache_dir)
embeddings = []
tokens = []
with open(glove_100d_path, encoding='utf-8') as gf:
for glove in gf:
word, embedding = glove.split(maxsplit=1)
tokens.append(word)
embeddings.append(np.fromstring(embedding, dtype=np.float32, sep=' '))
# 添加 <unk>, <pad> 两个特殊占位符对应的embedding
embeddings.append(np.random.rand(100))
embeddings.append(np.zeros((100,), np.float32))
vocab = ds.text.Vocab.from_list(tokens, special_tokens=["<unk>", "<pad>"], special_first=False)
embeddings = np.array(embeddings).astype(np.float32)
return vocab, embeddings5. 下载Glove
glove_path = download('glove.6B.zip', 'https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/glove.6B.zip')
vocab, embeddings = load_glove(glove_path)
len(vocab.vocab())idx = vocab.tokens_to_ids('the')
embedding = embeddings[idx]
idx, embedding6. 数据预处理
lookup_op = ds.text.Lookup(vocab, unknown_token='<unk>')
pad_op = ds.transforms.PadEnd([500], pad_value=vocab.tokens_to_ids('<pad>'))
type_cast_op = ds.transforms.TypeCast(ms.float32)imdb_train = imdb_train.map(operations=[lookup_op, pad_op], input_columns=['text'])
imdb_train = imdb_train.map(operations=[type_cast_op], input_columns=['label'])
imdb_test = imdb_test.map(operations=[lookup_op, pad_op], input_columns=['text'])
imdb_test = imdb_test.map(operations=[type_cast_op], input_columns=['label'])imdb_train, imdb_valid = imdb_train.split([0.7, 0.3])imdb_train = imdb_train.batch(64, drop_remainder=True)
imdb_valid = imdb_valid.batch(64, drop_remainder=True)6. 模型构建
class RNN(nn.Cell):
def __init__(self, embeddings, hidden_dim, output_dim, n_layers,
bidirectional, pad_idx):
super().__init__()
vocab_size, embedding_dim = embeddings.shape
self.embedding = nn.Embedding(vocab_size, embedding_dim, embedding_table=ms.Tensor(embeddings), padding_idx=pad_idx)
self.rnn = nn.LSTM(embedding_dim,
hidden_dim,
num_layers=n_layers,
bidirectional=bidirectional,
batch_first=True)
weight_init = HeUniform(math.sqrt(5))
bias_init = Uniform(1 / math.sqrt(hidden_dim * 2))
self.fc = nn.Dense(hidden_dim * 2, output_dim, weight_init=weight_init, bias_init=bias_init)
def construct(self, inputs):
embedded = self.embedding(inputs)
_, (hidden, _) = self.rnn(embedded)
hidden = ops.concat((hidden[-2, :, :], hidden[-1, :, :]), axis=1)
output = self.fc(hidden)
return output7. 损失函数和优化器
hidden_size = 256
output_size = 1
num_layers = 2
bidirectional = True
lr = 0.001
pad_idx = vocab.tokens_to_ids('<pad>')
model = RNN(embeddings, hidden_size, output_size, num_layers, bidirectional, pad_idx)
loss_fn = nn.BCEWithLogitsLoss(reduction='mean')
optimizer = nn.Adam(model.trainable_params(), learning_rate=lr)8. 训练过程
def forward_fn(data, label):
logits = model(data)
loss = loss_fn(logits, label)
return loss
grad_fn = ms.value_and_grad(forward_fn, None, optimizer.parameters)
def train_step(data, label):
loss, grads = grad_fn(data, label)
optimizer(grads)
return loss
def train_one_epoch(model, train_dataset, epoch=0):
model.set_train()
total = train_dataset.get_dataset_size()
loss_total = 0
step_total = 0
with tqdm(total=total) as t:
t.set_description('Epoch %i' % epoch)
for i in train_dataset.create_tuple_iterator():
loss = train_step(*i)
loss_total += loss.asnumpy()
step_total += 1
t.set_postfix(loss=loss_total/step_total)
t.update(1)9. 评估指标
def binary_accuracy(preds, y):
"""
计算每个batch的准确率
"""
# 对预测值进行四舍五入
rounded_preds = np.around(ops.sigmoid(preds).asnumpy())
correct = (rounded_preds == y).astype(np.float32)
acc = correct.sum() / len(correct)
return accdef evaluate(model, test_dataset, criterion, epoch=0):
total = test_dataset.get_dataset_size()
epoch_loss = 0
epoch_acc = 0
step_total = 0
model.set_train(False)
with tqdm(total=total) as t:
t.set_description('Epoch %i' % epoch)
for i in test_dataset.create_tuple_iterator():
predictions = model(i[0])
loss = criterion(predictions, i[1])
epoch_loss += loss.asnumpy()
acc = binary_accuracy(predictions, i[1])
epoch_acc += acc
step_total += 1
t.set_postfix(loss=epoch_loss/step_total, acc=epoch_acc/step_total)
t.update(1)
return epoch_loss / total10. 模型训练与保存
num_epochs = 2
best_valid_loss = float('inf')
ckpt_file_name = os.path.join(cache_dir, 'sentiment-analysis.ckpt')
for epoch in range(num_epochs):
train_one_epoch(model, imdb_train, epoch)
valid_loss = evaluate(model, imdb_valid, loss_fn, epoch)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
ms.save_checkpoint(model, ckpt_file_name)我对RNN的基本原理,如时间步的展开、状态传递、梯度消失与爆炸等问题有了更加深入的理解,还掌握了如何通过门控机制(如LSTM、GRU)来优化这些问题。MindSpore的API设计清晰直观,使得从理论到实践的转换变得顺畅无比,我能够迅速地将理论知识应用于构建具体的模型,如文本生成、情感分析或时间序列预测等任务中。、