目录
informer特点
1.一次输出你所有想得到的值。什么意思呢?就比如你想用1000个数据预测后面3天的数据,transformer是一天一天的输出,但是informer是一次性给你输出。所以不需要多次预测。
2.再经过我们的稀疏注意力的时候,会进行维度压缩。减少参数量。
informer原理
attention计算
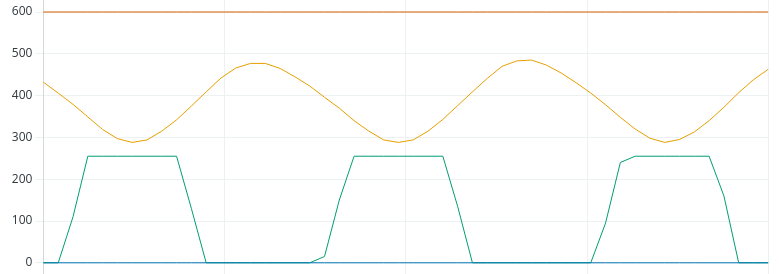
首先啊,我们要清楚qk矩阵想成功的含义,再transformer中有。链接: 不懂的看我的transformer原理。这里不多赘述,我就当你懂了。那么所谓我们序列与多序列之间的关系,打个比方就是我前一天的数据和后五天的数据的关系,得到第一天和后五天序列的关系。那么对于transformer来说,我们需要得到的不仅仅是第一天,还有第二天和其余五天,第三天和其余五天。。。那么就需要6x6的矩阵来记录我们的关系。但是当我们要计算很长的序列比如10000天,那么需要10000x10000的矩阵来存储答案,这样是不是有点大,参数会增加很多?我们可以得到下面的热力图。通过热力图我们可以发现,黑的很多红的很少。什么意思呢?黑色代表不相干,红的代表相干。所以我们这个矩阵大部分单词都不相干,所以这样的效果自然很差。在数据比较多的时候

该图上面红色线代表某一序列和其他序列的相关性的关系图。右边图的纵坐标代表着一个向量Q和其他向量的k乘积(也就是相关性),横坐标是不同的K,说明波动大代表相关性高,波动低代表相关性低。所以我们发现绿色的波动低,就代表我们的这个序列相关性低,就代表我们序列有没有他都一样。至于为什么波动大相关性高可以查看qk乘积那个公式,很明显可以看出

ok,那么我们如何解决这个问题?
这里就是我们informer的稀疏注意力probspare attention的核心所在------------部分特征代表整体,也就是我们用active的序列,去掉一些lazy的序列。也就是筛选active的序列。那么我们该怎么做呢?
很简单举个例子 我们Q和K各自是96个。
第1步:利用所有的Q和随机抽取1/4的K进行抽样,然后选出其中最活跃的25个特征序列Q
第2步:在让25个topQ和所有96个K相乘得到我们自注意力得到的结果
那么我们原来用自注意力需要96x96次计算。但是我们采取上述方法我们只需要计算
96x25x2(2是做两次),所以我们的效率是远远胜于我们的transformer
但是相乘以后我们变成的96x25之后我们还是需要和我们的v相乘,还是要将维度转换成原来的96x96,所以我们的informer就会进行expand,由于我们只有96x25,我们其它的部分该怎么办,很简单,把v矩阵(96x64)均值填上即可,因为我们只记录相关的,由于不相关,所以qk关系不是很大,所以用k的均值填上在和v相乘就行。
KL散度
什么是KL散度?即描述两个分布间差异的方法。就是这些红的竖线之间的差相加。

我们的informer的计算可以简化成如下。 意思就是。我们可以之间用红线最大值减去均值,得到我们的qk计算结果。


可能大家听不懂,这么说,一开始是我们要得到96x96的矩阵对吧,然后informer改成了概率相乘,就是随机抽取96里面的25个和其他96做乘积选出我们的top25个q后再用全部的K和Q相乘然后得到我们最后的结果时候,我们再用KL散度简化计算方式用最大的相关性值减去均值得到我们的结果,也就是化简为一个元素和一个元素的计算。
也就是96x96 ->96x25x2->1v1 (打个比方)
backbone网络部分

1部分的大梯形是用于处理比较长的序列,2部分是小梯形,处理比较短的序列
二者的结构都是一样的,3是用于减小参数(你看是梯形,从下到上宽度在变短,对应参数减小。)
原文翻译如下

encoder
输入输出部分
一般来说时序输入是[batch,sq_len,feature],informer原文是32x96x7对应着矩阵维度
96就代表着,一次输入96个数据,每个数据有7个特征,一共有32个批次。
那么对应的encoder输出是32x51x512
**为什么是512?**那是因为我们的encoder一般都会经过embading层进行嵌入后得到512维度和transformer一样。
embadding这里就不讲了 和transfomer一样
EncoderStack
其实就是多个encoder组合结合后得到的encoder层,看下图 encoder1和2输入第一输入是96,第二个encoder输入的是一半。并并且第二个encoder扔掉一层自我注意蒸馏层的数量,使这两个encoder的输出维度使对齐的;

最后得到的[32,51=(26+25),512]是拼接的来的 也就是下面两个拼接


可以参照原文图,红色线条代表第一个encoder,绿色代表第二个

decoder部分
输入: 32 × 51 × 512(encoder)和32 × 72 × 512 (decoder的输入)
输出: 32 × 72 × 512
decoder的输入和transformer一样 有从encoder的输入和decoder的输入
但是decoder 的输入有个特点就是后面的24个seq_len被0盖住,充当mask,这是出于transformer也就是箭头所指的部分。

我们把中间的放成一维画图表示。

接下来就是最关键的结构 关于如何将输入经过注意力得到结果

注意了 在最后一部进行qkv操作的时候也是用dl散值的操作 但是和与encoder中说的不一样,这里的lazy元素的填充值是用每个q时间点的v向量累加得到的值,因为是mask操作保证了不会看到后面的值。利用 ProbAttention 的结果计算得到 输出后经过全连接层一次性得到输出。
也就是encodr梯控kv矩阵,而我们的decoder输入的矩阵提供q,然后最后计算 ProbAttention 的时候不用mean(v)操作了,用的是累加方式,每个q用的当前时间点之前所有的v向量相加的值作为mask,从而不用和transformer一样,一步一步进行计算了