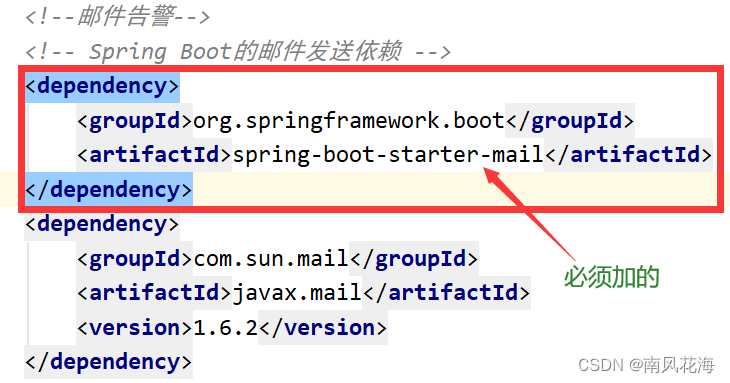
在Spring Cloud中,可以使用一些工具和框架来实现服务监控与告警的业务指标监控。本文将介绍一种常用的方案,使用Prometheus和Grafana来实现监控指标的采集和展示,并结合Alertmanager实现告警功能。
Prometheus简介 Prometheus是一款开源的监控系统,由SoundCloud开发,用于记录实时的指标数据。它采用pull模型,通过HTTP协议定期从目标系统拉取指标数据,并存储在本地数据库中。
Grafana简介 Grafana是一款开源的数据可视化工具,用于展示监控指标的图表和仪表盘。它支持多种数据源,包括Prometheus。Grafana提供了丰富的图表类型和配置选项,可以帮助我们快速构建漂亮的监控仪表盘。
集成Prometheus和Grafana 首先需要在Spring Cloud微服务项目中添加Prometheus客户端库,以便将应用程序的指标数据暴露给Prometheus。
在Spring Boot项目中,可以通过添加以下依赖来使用Prometheus客户端库:
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
在服务的启动类上增加注解@EnablePrometheusEndpoint,以启用Prometheus的指标暴露端点。
然后,需要在Prometheus的配置文件中添加要监控的微服务地址和端口号:
scrape_configs:
- job_name: 'spring-cloud'
metrics_path: '/actuator/prometheus'
static_configs:
- targets: ['localhost:8080']
在Grafana中配置Prometheus数据源,并创建仪表盘来展示指标数据。
- 业务指标监控 除了系统级别的指标,如CPU使用率、内存使用率等,我们还需要监控业务指标,如请求响应时间、接口调用次数等。
在Spring Cloud微服务项目中,可以使用Spring Boot Actuator来暴露这些业务指标。Actuator提供了一系列的HTTP端点,用于监控和管理应用程序。通过配置文件,可以启用和自定义这些端点。
配置文件中,通过设置management.endpoints.web.exposure.include属性来启用要暴露的端点,例如:
management:
endpoints:
web:
exposure:
include: health,info,metrics
默认情况下,Actuator会暴露/health、/info和/metrics端点,分别用于健康检查、应用程序信息和指标数据。/metrics端点可以提供详细的应用程序指标数据,包括请求响应时间、接口调用次数等。
- 提供自定义指标 除了默认的指标,我们还可以提供自定义的指标。在Spring Boot项目中,可以使用Micrometer来创建和发布自定义指标。
首先,添加Micrometer的依赖:
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-core</artifactId>
</dependency>
然后,在代码中创建并发布自定义指标:
import io.micrometer.core.instrument.Counter;
import io.micrometer.core.instrument.Metrics;
Counter myCounter = Metrics.counter("my_counter");
myCounter.increment();
这样,我们就创建了一个名为my_counter的自定义计数器,并通过increment()方法增加计数。
- 告警功能 在Prometheus中,可以使用PromQL查询语言来定义告警规则,并通过Alertmanager发送告警通知。
首先,需要在Prometheus的配置文件中定义告警规则,例如:
groups:
- name: my_alerts
rules:
- alert: HighErrorRate
expr: sum(rate(http_server_requests_seconds_count{status="500"}[5m])) by (job) / sum(rate(http_server_requests_seconds_count[5m])) by (job) > 0.5
for: 5m
labels:
severity: critical
annotations:
summary: High error rate
这个例子定义了一个名为HighErrorRate的告警规则,如果5分钟内服务器返回500错误的请求比例超过50%,则触发告警。
然后,在Alertmanager的配置文件中配置告警通知方式,例如发送邮件通知:
receivers:
- name: email-alert
email_configs:
- to: 'admin@example.com'
smarthost: 'smtp.example.com:587'
from: 'alertmanager@example.com'
auth_username: 'alertmanager'
auth_password: 'password'
auth_identity: 'alertmanager'
在Grafana中,可以使用Alertmanager插件来配置告警规则和通知方式。
- 总结 通过上述步骤,我们可以使用Prometheus和Grafana来实现Spring Cloud微服务的监控与告警功能。首先,需要在微服务项目中添加Prometheus客户端库,并配置Prometheus的指标采集地址。然后,通过Actuator来暴露业务指标,并使用Micrometer发布自定义指标。最后,可以使用Prometheus和Grafana来展示监控指标的图表和仪表盘,并通过Alertmanager来配置告警规则和通知方式。这样,我们就可以对微服务的关键指标进行实时监控,并及时发现和解决问题。