前言
之前文章介绍了基本的分词方式中,很依赖词库,但是对于文章中出现了新词,但又不在词库的时候,机器应该怎么识别他呢?
内部凝固度
对于一个词,其实相当于一种固定搭配,他一整个词出现的频率是比较高的,而对于词里面的单个字出现的频率应该相对来说是比较低的,所以我们可以用下面的方式来,表达这个意思 1 n log P ( W ) P ( n 1 ) . . . P ( n n ) \frac{1}{n}\log{\frac{P(W)}{P(n_1)...P(n_n)}} n1logP(n1)...P(nn)P(W)
这个公式就被称为内部凝固度, P ( W ) P(W) P(W)代表的是这个词在语料中出现的频率,而分子代表的是每个字出现的频率。如果一个词的内部凝固度越大,这个词成词的概率就越大。
左右熵
对于一个词,在他左边出现的字,如果他是一个固定搭配,左边出现的字应该是经常不同的,对于右边的出现的字也是一个同样的道理,我们可以用熵来表达这个含义:$ H ( x ) = − ∑ 1 n p ( x ) l o g ( p ( x ) ) H(x)=-\sum_1^n p(x)log(p(x)) H(x)=−1∑np(x)log(p(x))
p ( x ) p(x) p(x)可以是一个词左边字出现的频率,可以是右边。所以说有左熵和又熵两个值。与内部凝固度相同,他的左右熵越大,成词的概率越高。
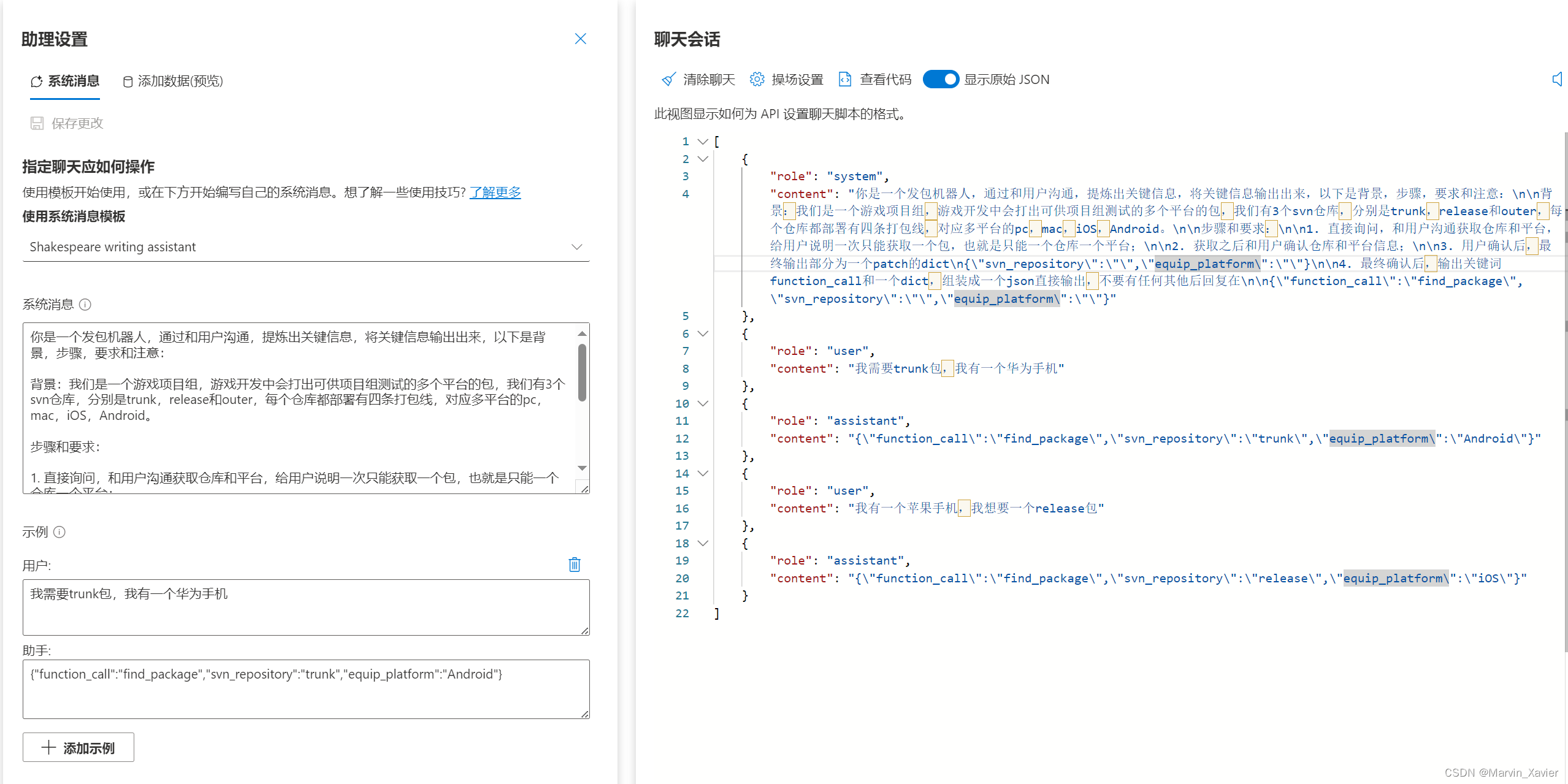
对于这新词的识别,我们可以结合内部凝固度和左右熵来判断他是不是一个新词,用内部凝固度乘 m i n = min= min={左熵,右熵},这里取最小值是因为,我们想保证一个词左右熵都比较大。
实现代码
import math
from collections import defaultdict
class NewWordDetect:
def __init__(self, corpus_path):
self.max_word_length = 5
self.word_count = defaultdict(int)
self.left_neighbor = defaultdict(dict)
self.right_neighbor = defaultdict(dict)
self.load_corpus(corpus_path)
self.calc_pmi()
self.calc_entropy()
self.calc_word_values()
#加载语料数据,并进行统计
def load_corpus(self, path):
with open(path, encoding="utf8") as f:
for line in f:
sentence = line.strip()
for word_length in range(1, self.max_word_length):
self.ngram_count(sentence, word_length)
return
#按照窗口长度取词,并记录左邻右邻
def ngram_count(self, sentence, word_length):
for i in range(len(sentence) - word_length + 1):
word = sentence[i:i + word_length]
self.word_count[word] += 1
if i - 1 >= 0:
char = sentence[i - 1]
self.left_neighbor[word][char] = self.left_neighbor[word].get(char, 0) + 1
if i + word_length < len(sentence):
char = sentence[i +word_length]
self.right_neighbor[word][char] = self.right_neighbor[word].get(char, 0) + 1
return
#计算熵
def calc_entropy_by_word_count_dict(self, word_count_dict):
total = sum(word_count_dict.values())
entropy = sum([-(c / total) * math.log((c / total), 10) for c in word_count_dict.values()])
return entropy
#计算左右熵
def calc_entropy(self):
self.word_left_entropy = {}
self.word_right_entropy = {}
for word, count_dict in self.left_neighbor.items():
self.word_left_entropy[word] = self.calc_entropy_by_word_count_dict(count_dict)
for word, count_dict in self.right_neighbor.items():
self.word_right_entropy[word] = self.calc_entropy_by_word_count_dict(count_dict)
#统计每种词长下的词总数
def calc_total_count_by_length(self):
self.word_count_by_length = defaultdict(int)
for word, count in self.word_count.items():
self.word_count_by_length[len(word)] += count
return
#计算互信息(pointwise mutual information)
def calc_pmi(self):
self.calc_total_count_by_length()
self.pmi = {}
for word, count in self.word_count.items():
p_word = count / self.word_count_by_length[len(word)]
p_chars = 1
for char in word:
p_chars *= self.word_count[char] / self.word_count_by_length[1]
self.pmi[word] = math.log(p_word / p_chars, 10) / len(word)
return
def calc_word_values(self):
self.word_values = {}
for word in self.pmi:
if len(word) < 2 or "," in word:
continue
pmi = self.pmi.get(word, 1e-3)
le = self.word_left_entropy.get(word, 1e-3)
re = self.word_right_entropy.get(word, 1e-3)
self.word_values[word] = pmi * min(le, re)
if __name__ == "__main__":
nwd = NewWordDetect("zeon3paang.txt")
value_sort = sorted([(word, count) for word, count in nwd.word_values.items()], key=lambda x:x[1], reverse=True)
print([x for x, c in value_sort if len(x) == 2][:10])
print([x for x, c in value_sort if len(x) == 3][:10])
print([x for x, c in value_sort if len(x) == 4][:10])