目录
有id,a,b,c四个字段,都是int,a和b上分别有索引 问:update table set a = a + 1 where c =2这个语句怎么执行,越详细越好
用count(*)哪个存储引擎会更快? (MyIsam 只有表锁 因此可以进行计数 没有并发)
假如说一个字段是varchar(10),但它其实只有6个字节,那他在内存中占的存储空间是多少?在文件中占的存储空间是多少?
如果硬件内存特别大,MySQL缓存能否替代redis? (MySQL:减少IO、搜索效率、加锁、持久性(redolog和binlog))
存储引擎
执行一条 select 查询SQL语句的全过程
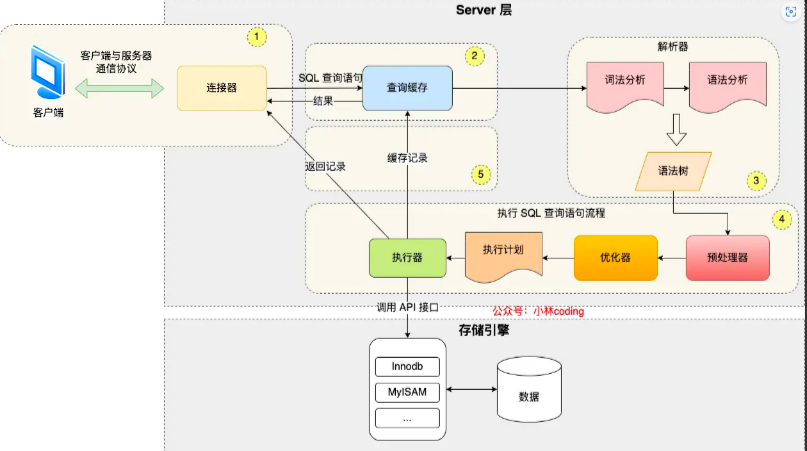
MySQL执行一条查询 SQL 语句的时候,会经过连接器、查询缓存、解析器、优化器、执行器、存储引擎这些模块。
- 首先 MySQL的连接器会负责建立连接、校验用户身份、接收客户端的 SQL 语句;
- 第二步 MySQL会在查询缓存中查找数据,如果命中直接返回数据给客户端,否则就需要继续往下查询
不过查询缓存功能在MySQL8.0 版本被删除了,原因是只要对这张表进行了写操作,这张表的查询缓存就会失效,所以在实际场景中,查询缓存的命中率其实不高;
- 第三步 MySQL的解析器会对 SQL 语句进行词法分析和语法分析,然后构建语法树,方便后续模块读取表名、字段语句类型;
- 第四步 预处理阶段:检查表或字段是否存在;将 select * 中的 * 符号扩展为表上的所有列。
- 第五步 MySQL的优化器会基于查询成本的考虑,会判断每个索引的执行成本,从中选择查询成本最小的执行计划;
- 第六步 MySQL的执行器会根据执行计划来执行查询语句从存储引擎读取记录,返回给客户端;
update语句的具体执行过程是怎样的?
更新语句的执行是 Server 层(binlog)和引擎层(undolog redolog)配合完成,数据除了要写入表中,还要记录相应的日志。
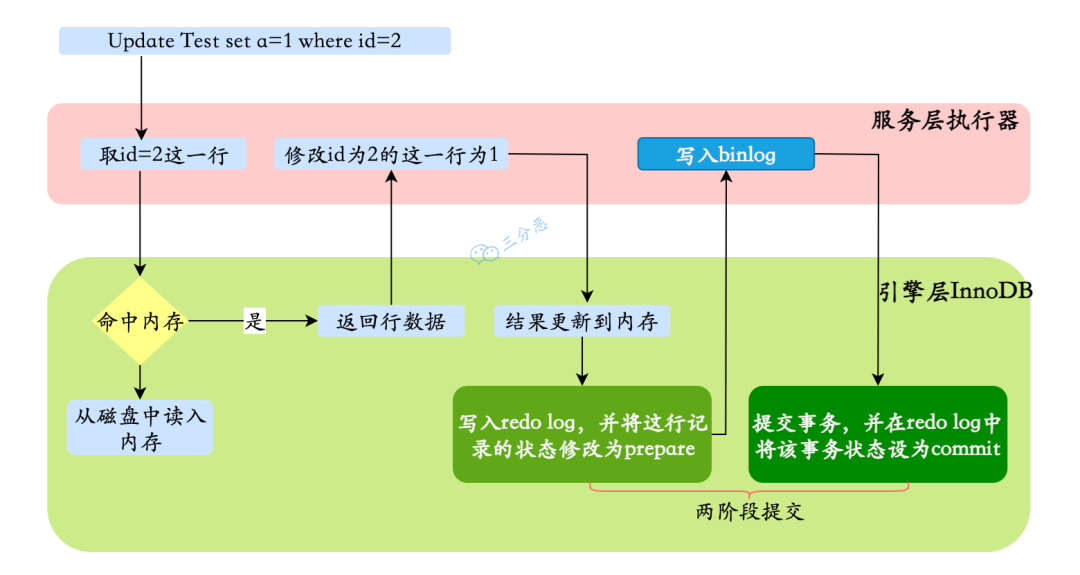
具体更新一条记录 UPDATE t_user SET name = 'xiaolin' WHERE id = 1; 的流程如下:
- 执行器负责具体执行,会调用存储引擎的接口,通过主键索引树搜索获取 id = 1 这一行记录(过滤条件):
-
- 如果 id=1 这一行所在的数据页本来就在 buffer pool 中,就直接返回给执行器更新;
- 如果记录不在 buffer pool,将数据页从磁盘读入到 buffer pool,返回记录给执行器。
- 执行器得到聚簇索引记录后,会看一下更新前的记录和更新后的记录是否一样:
-
- 如果一样的话就不进行后续更新流程;
- 如果不一样的话就把更新前的记录和更新后的记录都当作参数传给 InnoDB 层,让 InnoDB 真正的执行更新记录的操作;
- 开启事务, InnoDB 在更新记录前,首先要记录相应的 undo log,因为这是更新操作,需要把被更新的列的旧值记下来,也就是要生成一条 undo log,undo log 会写入 Buffer Pool 中的 Undo 页面,不过在内存修改该 Undo 页面后,需要记录对应的 redo log。
- InnoDB 层开始更新记录,会先更新内存(同时标记为脏页),然后将记录写到 redo log 里面,这个时候更新就算完成了。为了减少磁盘I/O,不会立即将脏页写入磁盘,后续由后台线程选择一个合适的时机将脏页写入到磁盘。这就是 WAL 技术,MySQL 的写操作并不是立刻写到磁盘上,而是先写 redo 日志,然后在合适的时间再将修改的行数据写到磁盘上。
- 至此,一条记录更新完了。
- 在一条更新语句执行完成后,然后开始记录该语句对应的 binlog,此时记录的 binlog 会被保存到 binlog cache,并没有刷新到硬盘上的 binlog 文件,在事务提交时才会统一将该事务运行过程中的所有 binlog 刷新到硬盘。
- 事务提交 包括两阶段提交:
-
- prepare 阶段:将 redo log 对应的事务状态设置为 prepare,然后将 redo log 刷新到硬盘;
- commit 阶段:将 binlog 刷新到磁盘,接着调用引擎的提交事务接口,将 redo log 状态设置为 commit(将事务设置为 commit 状态后,刷入到磁盘 redo log 文件);
- 至此,一条更新语句执行完成。
有id,a,b,c四个字段,都是int,a和b上分别有索引 问:update table set a = a + 1 where c =2这个语句怎么执行,越详细越好
加了查询条件但是没走索引 会进行加锁 进行全表扫描
同时 a的索引发生改变 先删除再重建
MySQL存储引擎有哪些?
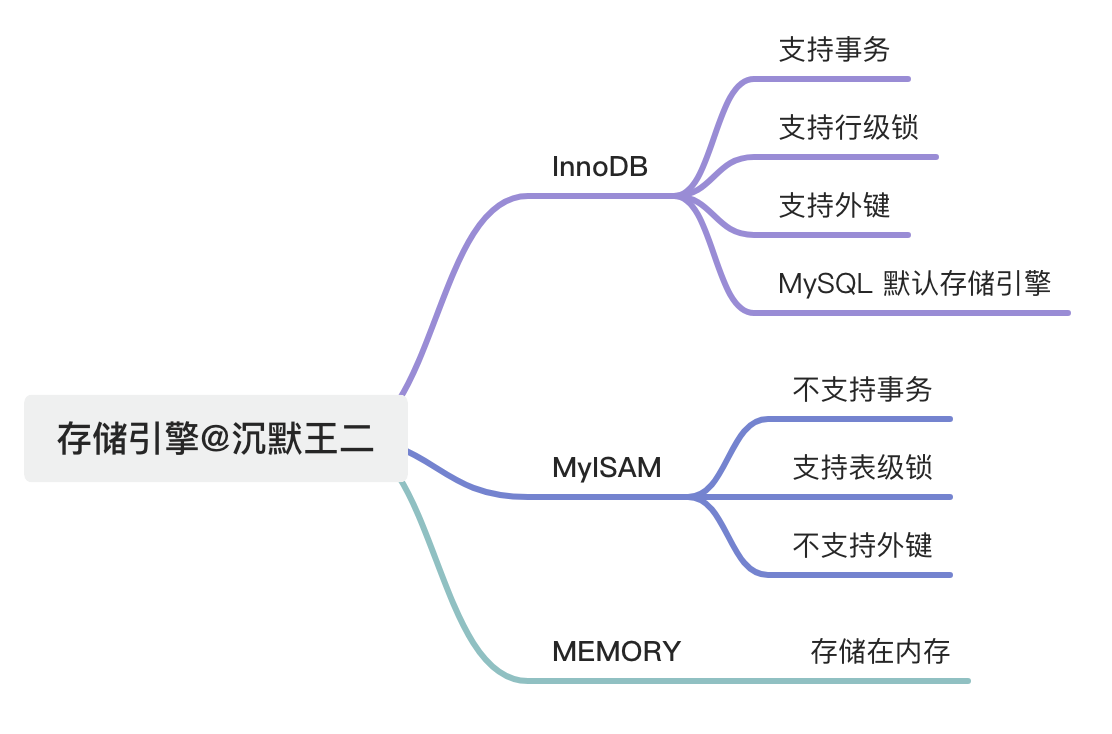
MySQL常见的存储引擎有 InnoDB、 MyISAM、Memory。
- 我比较熟悉的是InnoDB引擎,它是MySQL默认的存储引擎,支持事务、外键和行级锁,具有事务提交、回滚和崩溃恢复功能。
- MyISAM引擎是不支持事务和行级锁的,而且由于只支持表锁,锁的粒度比较大,更新性能比较差,我认为它比较适合读多写少的场景。
- Memory引擎是将数据存储在内存中,所以数据的读写还是比较快的,但是数据不具备持久性,我觉得适用于临时存储数据的场景。
MyISAM和InnoDB存储引擎有什么区别?
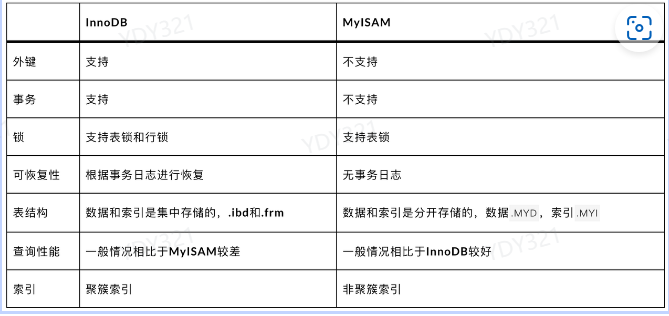
InnoDB引擎和MyISAM引擎在数据存储上有很大区别:
- InnoDB引擎,数据存储的方式采用的是索引组织表(.ibd),将表数据和索引数据存放在同一个文件的,而MyISAM引擎数据存储的方式采用的是堆表,将表数据和索引数据分开存储的。
-
- MyISAM:用三种格式的文件来存储,.frm 文件存储表的定义;.MYD 存储数据;.MYI 存储索引。
- InnoDB:用两种格式的文件来存储,.frm 文件存储表的定义;.ibd 存储数据和索引。
- MyISAM 为非聚簇索引,索引和数据分开存储,索引保存的是数据文件的指针。InnoDB 为聚簇索引,索引和数据不分开。
-
- 因此:InnoDB引擎B+树索引中的叶子节点存储的是索引和数据,MyISAM引擎B+树索引中的叶子节点存储的是索引和数据地址。
- InnoDB 引擎支持行级锁和事务,而 MyISAM引擎都不支持,只支持表锁。
- 表的具体行数:MyISAM 表的具体行数存储在表的属性中,查询时直接返回;InnoDB 表的具体行数需要扫描整个表才能返回。
用count(*)哪个存储引擎会更快? (MyIsam 只有表锁 因此可以进行计数 没有并发)
如果查询语句没有 where 查询条件的话,用MyISAM引擎会比较快,因为 MyISAM 引擎的每张表会用一个变量存储表的总记录个数,执行 count 函数的时候,直接读这个变量就行了。
而InnoDB引擎执行count 函数的时候,需要通过遍历的方式来统计记录个数。
如果查询语句有 where 查询条件的话,MyISAM 和InnoDB引擎执行 count 函数的时候,性能都差不多,都需要根据查询条件一行行的进行统计。
NULL值是如何存储的?
MySQL行格式中会用[NULL值列表]来标记值为 NULL 的列,每个列对应一个二进制位,如果列的值为 NULL,就会标记二进制位为1,否则为0,所以NULL 值并不会存储在行格式中的真实数据部分;
NULL 值列表最少会占用1字节空间,当表中所有列都定义成NOT NULL,行格式中就不会有 NULL值列表,这样可以至少节省1字节的空间;
char和varchar有什么区别?
char 是固定长度的字符串类型,在数据库中占用固定的存储空间,无论实际存储的数据长度是多少,都会占用定义时指定的固定长度,如果实际存储的字符串长度小于定义的长度,系统会自动用空格填充。
比如如果定义一个char(10)类型的字段,即使实际数据只使用 5字节,会自动填充 5字节的空格,使得存储空间固定占用10字节;
Varchar 是可变长度的字符串类型。实际存储时只占用实际字符串长度的空间,不会进行空格填充。
比如如果定义一个varchar(10)类型的字段,并存储了一个长度为5的字符串那么它只会占用5个字节的存储空间,并且还会额外用 1-2字节存储[可变长字符串长度]的空间(总空间6-7字节)
---------------------------------------------------------------------------------------
在设计数据库表的时候,大多数的时候我都是用 varchar 可变长度的字符串类型,因为 char 会填充空格可能导致浪费存储空间,进而导致性能下降。因为 char 多存储一些空格,意味着需要从磁盘读写更多的数据,会耗费更多内存,还有查找数据时需要删除空格可能也会耗费一些CPU性能。
假如说一个字段是varchar(10),但它其实只有6个字节,那他在内存中占的存储空间是多少?在文件中占的存储空间是多少?
内存会占用 10 字节,文件存储空间会占用 6字节,并且还会额外用 1-2 字节存储[可变长字符串长度]的空间
内存存储:(RAM)
- 当数据库在运行时,数据会被加载到内存中以提高访问速度。内存中的数据结构设计注重快速读写和操作的效率,因此可能会占用更多的空间来存储额外的元数据、指针和对齐信息。
文件存储:
- 数据库会将数据持久化存储在磁盘上。磁盘上的存储格式更紧凑,以节省存储空间,并且需要考虑数据的持久性和恢复能力。
如果硬件内存特别大,MySQL缓存能否替代redis? (MySQL:减少IO、搜索效率、加锁、持久性(redolog和binlog))
假设buffer pool无限大,能装下所有数据,是否可以代替redis
我觉得还是不能替代
- MySQL所有模块,比如 buffer pool、日志技术、事务,都是面向磁盘页而设计的,因此其首要目标不是减少内存访问的代价,而是I/O代价,所以内存访问代价却并不是最优选择,而 Redis 是面向内存而设计的数据库;
- MySQL在内存查询一个数据页的时候,都需要先查页表,也是需要走 b+ 树的搜索过程,时间复杂度是 O(logdN) ,而Redis 提供了很多种的数据类型,比如用Hash 数据对象的时候,可以在 O(1)时间复杂度查到数据;
- MySQL在更新数据的时候,MySQL为了保证事务的隔离性是需要加锁的,而Redis 更新操作都是不需要加锁的;
- MySQL为了保证事务的持久性,还需要刷盘 redolog 日志和binlog 日志,Redis 可以选择不持久化数据;
因此,即使 buffer pool 无限大,MySQL缓存的性能还是没有 Redis 好的
自己整理,借鉴很多博主,感谢他们