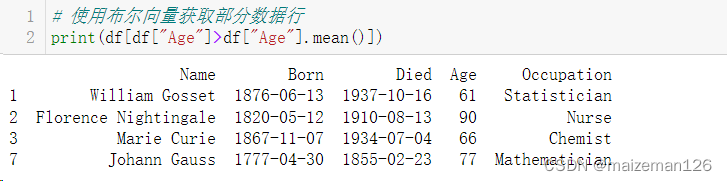
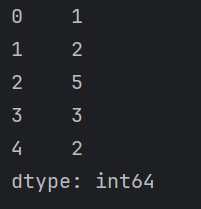
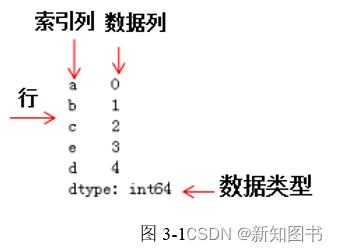
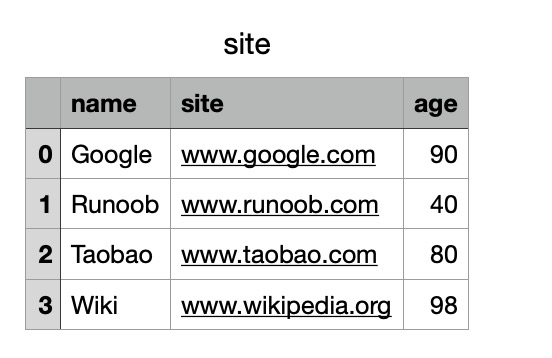
Pandas是基于强大的NumPy库开发的,它继承了NumPy中的一些数据结构,也继承了NumPy的高效计算特性。
1.Python的数据类型
Python 提供了多种数据类型,用于存储和操作不同类型的数据。以下是一些主要的数据类型:
数值类型(Numeric Types):
- 整数(int):用于表示整数。例如,
x = 5 - 浮点数(float):用于表示带有小数点的数字。例如,
y = 3.14 - 复数(complex):用于表示复数,例如,
z = 1 + 2j
- 整数(int):用于表示整数。例如,
序列类型(Sequence Types):
- 字符串(str):用于表示文本数据。例如,
name = "Alice" - 列表(list):用于表示有序的可变集合。例如,
fruits = ["apple", "banana", "cherry"] - 元组(tuple):用于表示有序的不可变集合。例如,
coordinates = (10, 20)
- 字符串(str):用于表示文本数据。例如,
集合类型(Set Types):
- 集合(set):用于表示无序的唯一元素集合。例如,
unique_numbers = {1, 2, 3} - 冰冻集合(frozenset):用于表示不可变的集合。例如,
immutable_set = frozenset([1, 2, 3])
- 集合(set):用于表示无序的唯一元素集合。例如,
映射类型(Mapping Types):
- 字典(dict):用于表示键值对集合。例如,
person = {"name": "Alice", "age": 25}
- 字典(dict):用于表示键值对集合。例如,
布尔类型(Boolean Type):
- 布尔(bool):用于表示真或假。例如,
is_active = True
- 布尔(bool):用于表示真或假。例如,
二进制类型(Binary Types):
- 字节(bytes):用于表示二进制数据。例如,
data = b"hello" - 字节数组(bytearray):用于表示可变的二进制数据。例如,
mutable_data = bytearray(b"hello") - 内存视图(memoryview):用于在不复制数据的情况下操作二进制数据。例如,
mview = memoryview(b"hello")
- 字节(bytes):用于表示二进制数据。例如,
Python 还提供了一些内置函数来检查数据类型和转换数据类型,例如:
type():用于返回变量的数据类型。isinstance():用于检查变量是否是特定类型的实例。int()、float()、str()等:用于类型转换。
以下是一些常见的 Python 数据类型的代码示例:
1.1.数值类型
# 整数
x = 5
print(f"x: {x}, type: {type(x)}")
# 浮点数
y = 3.14
print(f"y: {y}, type: {type(y)}")
# 复数
z = 1 + 2j
print(f"z: {z}, type: {type(z)}")
1.2.序列类型
# 字符串
name = "Alice"
print(f"name: {name}, type: {type(name)}")
# 列表
fruits = ["apple", "banana", "cherry"]
print(f"fruits: {fruits}, type: {type(fruits)}")
# 元组
coordinates = (10, 20)
print(f"coordinates: {coordinates}, type: {type(coordinates)}")
1.3.集合类型
# 集合
unique_numbers = {1, 2, 3}
print(f"unique_numbers: {unique_numbers}, type: {type(unique_numbers)}")
# 冰冻集合
immutable_set = frozenset([1, 2, 3])
print(f"immutable_set: {immutable_set}, type: {type(immutable_set)}")
1.4.映射类型
# 字典
person = {"name": "Alice", "age": 25}
print(f"person: {person}, type: {type(person)}")
1.5.布尔类型
# 布尔
is_active = True
print(f"is_active: {is_active}, type: {type(is_active)}")
1.6.二进制类型
# 字节
data = b"hello"
print(f"data: {data}, type: {type(data)}")
# 字节数组
mutable_data = bytearray(b"hello")
print(f"mutable_data: {mutable_data}, type: {type(mutable_data)}")
# 内存视图
mview = memoryview(b"hello")
print(f"mview: {mview}, type: {type(mview)}")
1.7.类型检查和转换
# 类型检查
print(f"is x an int? {isinstance(x, int)}")
print(f"is name a str? {isinstance(name, str)}")
# 类型转换
num_str = "123"
num = int(num_str)
print(f"num: {num}, type: {type(num)}")
float_num = float(num_str)
print(f"float_num: {float_num}, type: {type(float_num)}")
2.Numpy
NumPy 是 Python 中一个强大的科学计算库,提供了支持大量维数组和矩阵运算的功能,还包括了大量的数学函数库。以下是一些使用 NumPy 进行操作的代码示例。
2.1. 导入 NumPy
import numpy as np
2.2.创建数组
# 创建一维数组
arr1 = np.array([1, 2, 3, 4, 5])
print(f"arr1: {arr1}, type: {type(arr1)}")
# 创建二维数组
arr2 = np.array([[1, 2, 3], [4, 5, 6]])
print(f"arr2: {arr2}, type: {type(arr2)}")
# 使用 arange 和 reshape 创建数组
arr3 = np.arange(10).reshape(2, 5)
print(f"arr3:\n{arr3}")
2.3.基本操作
# 数组元素加减乘除
arr4 = arr1 + 10
print(f"arr1 + 10: {arr4}")
arr5 = arr1 * 2
print(f"arr1 * 2: {arr5}")
# 数组相加
arr6 = arr1 + arr1
print(f"arr1 + arr1: {arr6}")
# 数组元素逐个相乘
arr7 = arr1 * arr1
print(f"arr1 * arr1: {arr7}")
2.4.数组索引和切片
# 一维数组索引
print(f"arr1[0]: {arr1[0]}")
print(f"arr1[-1]: {arr1[-1]}")
# 二维数组索引
print(f"arr2[0, 1]: {arr2[0, 1]}")
print(f"arr2[1, -1]: {arr2[1, -1]}")
# 切片
print(f"arr1[1:4]: {arr1[1:4]}")
print(f"arr2[:, 1]: {arr2[:, 1]}")
2.5.数学函数
# 求和
print(f"np.sum(arr1): {np.sum(arr1)}")
print(f"np.sum(arr2, axis=0): {np.sum(arr2, axis=0)}")
print(f"np.sum(arr2, axis=1): {np.sum(arr2, axis=1)}")
# 平均值
print(f"np.mean(arr1): {np.mean(arr1)}")
print(f"np.mean(arr2, axis=0): {np.mean(arr2, axis=0)}")
print(f"np.mean(arr2, axis=1): {np.mean(arr2, axis=1)}")
# 标准差
print(f"np.std(arr1): {np.std(arr1)}")
print(f"np.std(arr2, axis=0): {np.std(arr2, axis=0)}")
print(f"np.std(arr2, axis=1): {np.std(arr2, axis=1)}")
2.6.线性代数
# 矩阵乘法
arr8 = np.array([[1, 2], [3, 4]])
arr9 = np.array([[5, 6], [7, 8]])
result = np.dot(arr8, arr9)
print(f"np.dot(arr8, arr9):\n{result}")
# 计算行列式
det = np.linalg.det(arr8)
print(f"np.linalg.det(arr8): {det}")
# 逆矩阵
inv = np.linalg.inv(arr8)
print(f"np.linalg.inv(arr8):\n{inv}")
2.7.随机数生成
# 生成随机数
rand_arr = np.random.random((3, 3))
print(f"rand_arr:\n{rand_arr}")
# 生成正态分布的随机数
normal_arr = np.random.normal(0, 1, (3, 3))
print(f"normal_arr:\n{normal_arr}")
# 生成随机整数
randint_arr = np.random.randint(0, 10, (3, 3))
print(f"randint_arr:\n{randint_arr}")
通过这些示例,你可以看到如何使用 NumPy 进行数组创建、基本操作、索引和切片、数学函数、线性代数以及随机数生成。NumPy 提供了丰富的功能,可以大大简化科学计算和数据处理的工作。
3.Pandas的数据结构
Pandas 是一个强大的数据分析和操作库,提供了两种主要的数据结构:Series 和 DataFrame。以下是对这两种数据结构的详细介绍和代码示例。
3.1.Series
Series 是一种类似于一维数组的对象,它由一组数据和与之相关的索引组成。它可以包含任何数据类型。
3.1.1.创建 Series
import pandas as pd
# 从列表创建 Series
s1 = pd.Series([1, 2, 3, 4, 5])
print(f"s1:\n{s1}")
# 指定索引创建 Series
s2 = pd.Series([10, 20, 30], index=['a', 'b', 'c'])
print(f"s2:\n{s2}")
# 从字典创建 Series
s3 = pd.Series({'x': 100, 'y': 200, 'z': 300})
print(f"s3:\n{s3}")
3.1.2.访问 Series 元素
# 按位置访问
print(f"s1[0]: {s1[0]}")
print(f"s2[1]: {s2[1]}")
# 按索引访问
print(f"s2['a']: {s2['a']}")
print(f"s3['y']: {s3['y']}")
3.2.DataFrame
DataFrame 是一种二维的表格数据结构,类似于电子表格或 SQL 表格。它由多列数据组成,每列可以是不同的数据类型。
3.2.1.创建 DataFrame
# 从字典创建 DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['New York', 'Los Angeles', 'Chicago']
}
df1 = pd.DataFrame(data)
print(f"df1:\n{df1}")
# 从二维数组创建 DataFrame
data2 = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
]
df2 = pd.DataFrame(data2, columns=['A', 'B', 'C'])
print(f"df2:\n{df2}")
# 从字典的列表创建 DataFrame
data3 = [
{'Name': 'David', 'Age': 40},
{'Name': 'Eve', 'Age': 45}
]
df3 = pd.DataFrame(data3)
print(f"df3:\n{df3}")
3.2.2.访问 DataFrame 元素
# 按列访问
print(f"df1['Name']:\n{df1['Name']}")
print(f"df1[['Name', 'Age']]:\n{df1[['Name', 'Age']]}")
# 按行访问(使用索引)
print(f"df1.loc[0]:\n{df1.loc[0]}")
print(f"df1.loc[0:1]:\n{df1.loc[0:1]}")
# 按行访问(使用位置)
print(f"df1.iloc[0]:\n{df1.iloc[0]}")
print(f"df1.iloc[0:2]:\n{df1.iloc[0:2]}")
3.2.3.数据筛选与操作
# 筛选数据
adults = df1[df1['Age'] > 25]
print(f"adults:\n{adults}")
# 添加新列
df1['Salary'] = [50000, 60000, 70000]
print(f"df1 with Salary:\n{df1}")
# 删除列
df1.drop('City', axis=1, inplace=True)
print(f"df1 without City:\n{df1}")
# 更新列值
df1['Age'] = df1['Age'] + 1
print(f"df1 with updated Age:\n{df1}")
3.2.4.数据统计与聚合
# 计算平均值
print(f"Average Age: {df1['Age'].mean()}")
# 计算总和
print(f"Total Salary: {df1['Salary'].sum()}")
# 分组统计
grouped = df1.groupby('Name').sum()
print(f"grouped:\n{grouped}")
通过这些示例,你可以看到如何使用 Pandas 进行数据的创建、访问、筛选、操作以及统计与聚合分析。Pandas 提供了丰富的功能,使得数据分析和操作变得更加方便和高效。