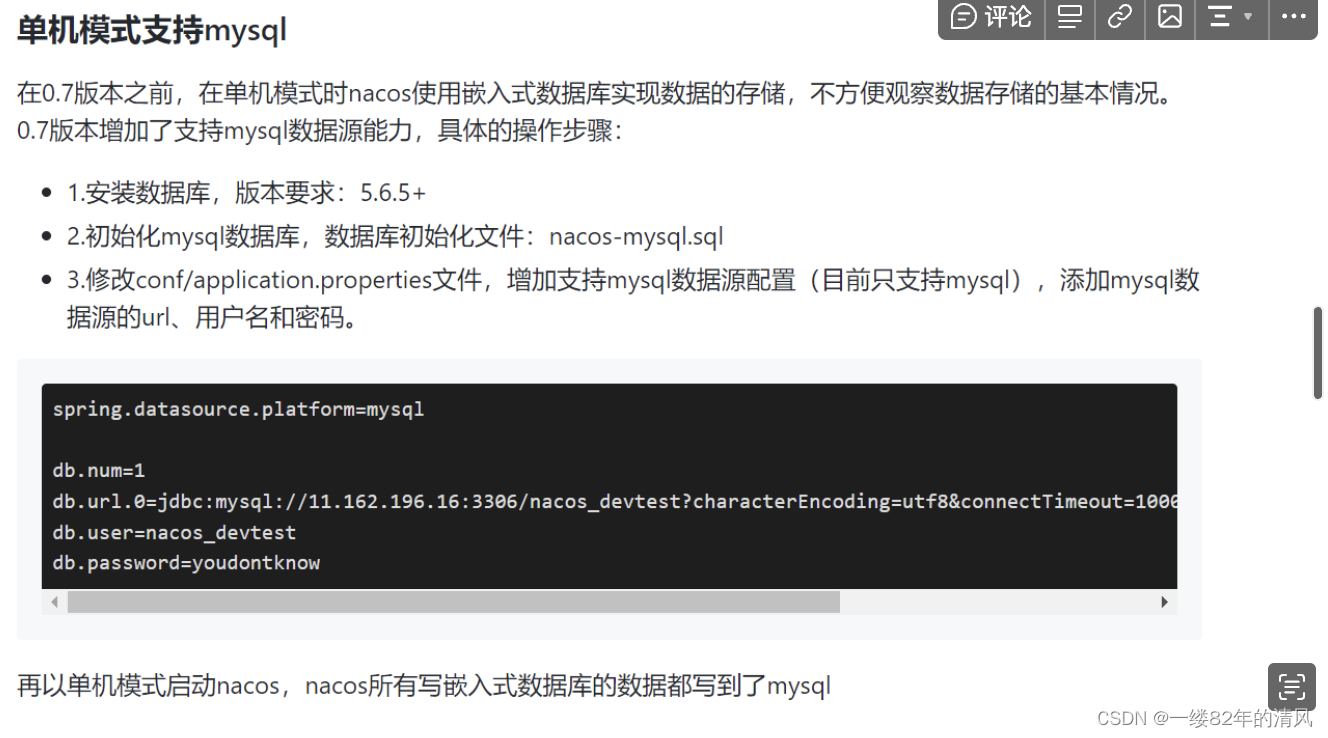
pandas数据处理
头哥实践教学平台: python 数据分析之 4 —— pandas 预处理https://pgedu.educoder.net/shixuns/q3xljogu/challenges
数据文件可下载:https://share.weiyun.com/1vsLbJwt
相关知识
DataFrame合并
DataFrame合并有四种方法: concat 、append、merge和 join
1. pandas.concat()
def concat(
objs: Iterable[NDFrame] | Mapping[Hashable, NDFrame],
axis: Axis = 0,
join: str = "outer",
ignore_index: bool = False,
keys=None,
levels=None,
names=None,
verify_integrity: bool = False,
sort: bool = False,
copy: bool = True,
)
'''
objs参数:Series或DataFrame对象的序列或字典。如果传递了字典dict,则dict的键将会被用作keys参数(成为最外层索引)。
axis参数: 连接的轴,{0 or 'index'纵向拼接行, 1 or 'columns'横向拼接列}, default 0。
join参数:合并方式,{'inner', 'outer'},默认为outer并集。inner为交集,只合并相同的部分,axis=0时合并结果为具有相同列名的数据,axis=1时为具有相同索引的数据。
ignore_index参数:是否重置索引,默认为False保留原来df的索引。如果为True,则重置索引为0,...,n-1。
keys参数:创建分层索引。使用传递的值作为最外层的一级索引。
levels参数:序列列表,用于构建MultiIndex的特定级别(唯一值)。否则,它们将从keys推断。注:没搞懂这个参数唉
names参数:列表,生成的分层索引中的索引名称。
verify_integrity参数:检测索引是否重复,如果为True则有重复索引会报错。
sort参数:默认为False不排序。如果为True则进行排序:join='outer'并集合并方式下,若axis=0或'index',则对列索引排序;若axis=1或'columns',则对行索引进行排序。join='inner'交集合并方式下无效果。
'''
>>> df1 = pd.DataFrame([['a', 1], ['b', 2]], columns=['letter', 'number'], index=[3, 4])
>>> df2 = pd.DataFrame([['c', 3, 'cat'], ['d', 4, 'dog']], columns=['letter', 'number', 'animal'], index=[1, 2])
>>> pd.concat([df1, df2],keys=['d1','d2'],names=['df_name','row_id'])
>>> df1 = pd.DataFrame({
'B': ['B0', 'B1', 'B2', 'B3'],
'A': ['A0', 'A1', 'A2', 'A3']
}, index=pd.MultiIndex.from_tuples([('x', 1), ('x', 2), ('y', 1), ('y', 2)]))
>>> df2 = pd.DataFrame({
'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7']
}, index=pd.MultiIndex.from_tuples([('x', 3), ('x', 4), ('y', 3), ('y', 4)]))
>>> df1
B A
x 1 B0 A0
2 B1 A1
y 1 B2 A2
2 B3 A3
>>> df2
A B
x 3 A4 B4
4 A5 B5
y 3 A6 B6
4 A7 B7
>>> pd.concat([df1, df2], sort=True)
A B
x 1 A0 B0
2 A1 B1
y 1 A2 B2
2 A3 B3
x 3 A4 B4
4 A5 B5
y 3 A6 B6
4 A7 B7
>>> pd.concat([df1, df2], sort=False)
B A
x 1 B0 A0
2 B1 A1
y 1 B2 A2
2 B3 A3
x 3 B4 A4
4 B5 A5
y 3 B6 A6
4 B7 A7
>>> pd.concat([df1, df2], axis=1, sort=True)
B A A B
x 1 B0 A0 NaN NaN
2 B1 A1 NaN NaN
3 NaN NaN A4 B4
4 NaN NaN A5 B5
y 1 B2 A2 NaN NaN
2 B3 A3 NaN NaN
3 NaN NaN A6 B6
4 NaN NaN A7 B7
>>> pd.concat([df1, df2], axis=1, sort=False)
B A A B
x 1 B0 A0 NaN NaN
2 B1 A1 NaN NaN
y 1 B2 A2 NaN NaN
2 B3 A3 NaN NaN
x 3 NaN NaN A4 B4
4 NaN NaN A5 B5
y 3 NaN NaN A6 B6
4 NaN NaN A7 B7
2. DataFrame.append()
FutureWarning:frame.append()方法已弃用,并将在未来版本中从pandas中删除。请改用pandas.concat()。
df1.append(df2) # 将 df2 中的⾏添加到 df1 的尾部
def append(
other,
ignore_index: bool = False,
verify_integrity: bool = False,
sort: bool = False,
)
'''
other参数:要追加的DataFrame、Series或者类似字典的对象,或者是这些类型数据的列表。
ignore_index参数:是否重置索引,默认为False保留原来df的索引。如果为True,则重置索引为0,...,n-1。
verify_integrity参数:检测索引是否重复,如果为True则有重复索引会报错。
sort参数:默认为False不排序。如果为True则对列索引进行排序。
'''
3. DataFrame.merge()或者pd.merge()
def merge(
right: DataFrame | Series,
how: str = "inner",
on: IndexLabel | None = None,
left_on: IndexLabel | None = None,
right_on: IndexLabel | None = None,
left_index: bool = False,
right_index: bool = False,
sort: bool = False,
suffixes: Suffixes = ("_x", "_y"),
copy: bool = True,
indicator: bool = False,
validate: str | None = None,
)
'''
right参数:DataFrame或命名的Series(该Series需要设置name参数),它是一个与DataFrame合并的对象。
how参数: 合并类型,{'left', 'right', 'outer', 'inner', 'cross'}, 默认'inner'交集。
on参数:要连接的列或者索引级别名称。指定两个dataframe按某一列或某几列进行连接,该列必须同时出现在两个dataframe中。默认值是两个DataFrame中列的交集。
left_on参数:要连接的左DataFrame中的列名或者索引级别名称,也可以是左DataFrame长度的数组或数组列表。
right_on参数:要连接的右DataFrame中的列名或者索引级别名称,,也可以是右DataFrame长度的数组或数组列表。
left_index参数:当DataFrame中的连接键位于其索引中时,可以将其设置为True,表示使用左DataFrame中的索引作为连接键。如果是多级索引MultiIndex,另一个DataFrame中的连接键数(索引或者多个列)必须与MultiIndex级别数相等。
right_index参数:是否使用右DataFrame中的索引作为连接键。同left_index参数。left_index与right_index 不能与 on 同时指定。
sort参数:如果为True则在结果DataFrame中按字典顺序对连接键进行排序。如果为False,连接键的顺序取决于连接类型(how参数)。
suffixes参数:元组,指定附加到左右两个DataFrame对象的重叠列名上的字符串。(即给左右两个DataFrame相同的列名添加一个后缀)。
copy参数:指在合并操作中是否复制数据到新的 DataFrame 中。默认情况下,copy 参数设置为 True,表示会创建一个新的 DataFrame 来存储合并后的数据。当您设置 copy=False 时,pandas 会在原地修改输入的 DataFrame,而不是创建一个新的 DataFrame。这意味着合并操作会直接在原始的 DataFrame 上进行,这样就可以节省内存,因为不需要复制数据。(但我将copy参数设置为False时,它的效果和True时一样,没懂这个参数)
indicator参数: bool or str, default False。如果为True,则向结果DataFrame添加一个名为"_merge"的列,指示每行数据的来源,来自左DataFrame还是右DataFrame或者左右DataFrame。如果为str字符串,则是对该列指定其它的名称。"left_only"表示该行数据只来自左DataFrame,"right_only"表示该行数据只来自右DataFrame,"both"表示该行数据来自左右DataFrame。
validate参数:在执行合并操作之前,对合并的数据进行验证的一个选项。这个参数允许你检查合并操作是否符合特定的条件或规则,从而确保合并操作的有效性。validate参数的可选值有以下几种: "one_to_one" or "1:1":检查合并键在左右两个DataFrame中是否唯一。"one_to_many" or "1:m":检查合并键在左侧DataFrame中是否唯一,但在右侧DataFrame中可以重复出现。"many_to_one" or "m:1":检查合并键在右侧DataFrame中是否唯一,但在左侧DataFrame中可以重复出现。"many_to_many" or "m:m":不执行任何检查,允许合并键在左右两个DataFrame中都可以重复出现。
'''
def merge(
left: DataFrame | Series,
right: DataFrame | Series,
how: str = "inner",
on: IndexLabel | None = None,
left_on: IndexLabel | None = None,
right_on: IndexLabel | None = None,
left_index: bool = False,
right_index: bool = False,
sort: bool = False,
suffixes: Suffixes = ("_x", "_y"),
copy: bool = True,
indicator: bool = False,
validate: str | None = None,
)
>>> df1 = pd.DataFrame({
'lkey': ['foo', 'baz', 'foo', 'bar','sob'],'value': [1, 2, 3, 5,7]})
>>> df2 = pd.DataFrame({
'rkey': ['foo', 'bar', 'otv','foo', 'baz'],'value': [5, 6,1, 7, 8]})
>>> df1
lkey value
0 foo 1
1 baz 2
2 foo 3
3 bar 5
4 sob 7
>>> df2
rkey value
0 foo 5
1 bar 6
2 otv 1
3 foo 7
4 baz 8
>>> df3=pd.merge(df1,df2, left_on='lkey', right_on='rkey',suffixes=("_l","_r"),sort=True,indicator="from",how='outer')
# df4=df1.merge(df2, left_on='lkey', right_on='rkey',suffixes=("_l","_r"),sort=False)
>>> df3
lkey value_l rkey value_r from
0 bar 5.0 bar 6.0 both
1 baz 2.0 baz 8.0 both
2 foo 1.0 foo 5.0 both
3 foo 1.0 foo 7.0 both
4 foo 3.0 foo 5.0 both
5 foo 3.0 foo 7.0 both
6 NaN NaN otv 1.0 right_only
7 sob 7.0 NaN NaN left_only
4. DataFrame.join()
df1.join(df2.set_index(col1),on=col1,how=‘inner’)
#对 df1 的列和 df2 的列执⾏SQL 形式的 join,默认按照索引来进⾏合并,如果 df1 和 df2 有共同字段时,会报错,可通过设置 lsuffix,rsuffix 来进⾏解决,如果需要按照共同列进⾏合并,就要⽤到 set_index(col1)
def join(
other: DataFrame | Series,
on: IndexLabel | None = None,
how: str = "left",
lsuffix: str = "",
rsuffix: str = "",
sort: bool = False,
)
'''
other参数:待连接的另一个DataFrame、带有名字(name属性)的Series或DataFrame列表。如果传递了Series,则必须设置其name属性,并将其用作结果DataFrame中的列名称。
on参数:str、 list of str、 or array-like。调用者DataFrame中要加入索引的列或索引级别名称,以便和other中的索引做连接。如果不传递值给on,则调用者DataFrame中的索引与other中的索引进行连接(默认使用索引连接)。如果给出多个值,则other必须具有MultiIndex。如果数组尚未包含在调用者DataFrame中,则可以将其作为连接键传递。就像Excel的VLOOKUP操作一样。
how参数: 连接方式,可选值包括 {'left', 'right', 'outer', 'inner'}, default 'left'。
lsuffix参数:左Dataframe中重复列的后缀。
rsuffix参数:右DataFrame中重复列的后缀。
sort参数:如果为True则在结果DataFrame中按字典顺序对连接键进行排序。如果为False,连接键的顺序取决于连接类型(how参数)。
'''
>>> df1 = pd.DataFrame({
'key': ['foo', 'baz', 'foo', 'bar','sob'],'value': [1, 2, 3, 5,7]})
>>> df2 = pd.DataFrame({
'key': ['foo', 'bar', 'otv','foo', 'baz'],'value': [5, 6,1, 7, 8]})
>>> df1
key value
0 foo 1
1 baz 2
2 foo 3
3 bar 5
4 sob 7
>>> df2
key value
0 foo 5
1 bar 6
2 otv 1
3 foo 7
4 baz 8
>>> df3=df1.join(df2,lsuffix='_caller',rsuffix='_other')
>>> df3
key_caller value_caller key_other value_other
0 foo 1 foo 5
1 baz 2 bar 6
2 foo 3 otv 1
3 bar 5 foo 7
4 sob 7 baz 8
>>> df4=df1.set_index('key').join(df2.set_index('key'),lsuffix='_caller',rsuffix='_other',sort=True)
>>> df4
value_caller value_other
key
bar 5 6.0
baz 2 8.0
foo 1 5.0
foo 1 7.0
foo 3 5.0
foo 3 7.0
sob 7 NaN
>>> df5=df1.join(df2.set_index('key'),on='key',lsuffix='_caller',rsuffix='_other',sort=True)
>>> df5
key value_caller value_other
3 bar 5 6.0
1 baz 2 8.0
0 foo 1 5.0
0 foo 1 7.0
2 foo 3 5.0
2 foo 3 7.0
4 sob 7 NaN
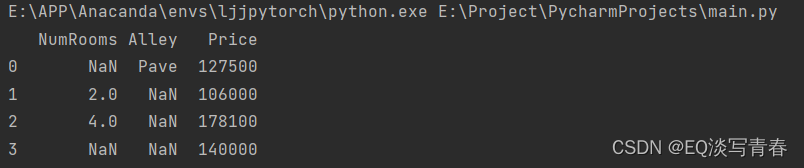
第1关:数据读取与合并
任务描述
本关任务:加载 csv 数据集,实现 DataFrame 合并。
本关代码
# -*- coding: utf-8 -*-
import pandas as pd
'''
第1关 数据读取与合并
现有源自世界银行的四个数据集:
1)economy-60-78.csv,
2)economy-79-19.csv,
3)population-60-78.csv,
4)population-79-19.csv,
其中分别存放了不同时间段(1960-1978和1979-2019)的
中国经济相关数据和中国人口及教育相关数据。
'''
#请将上述数据集内容读取至DataFrame结构中,
#年份为列索引,Indicator Name为行索引,
#观察其结构和内容,把它们合并为一个DataFrame,命名为ChinaData。
#输出ChinaData的形状
# index_col 是 read_csv 方法的常用参数,常用作读取文件的指定列为行索引
economy_df1=pd.read_csv("D:\VS\Python数据处理与编程\Python数据分析4\economy-60-78.csv",index_col=0)
economy_df2=pd.read_csv("D:\VS\Python数据处理与编程\Python数据分析4\economy-79-19.csv",index_col='Indicator Name')
population_df1=pd.read_csv("D:\VS\Python数据处理与编程\Python数据分析4\population-60-78.csv",index_col='Indicator Name')
population_df2=pd.read_csv("D:\VS\Python数据处理与编程\Python数据分析4\population-79-19.csv",index_col='Indicator Name')
# axis=1 or 'columns'横向拼接列,sort=True对行索引进行排序
#join参数:合并方式,{'inner', 'outer'},默认为outer并集。
economy_data=pd.concat([economy_df1,economy_df2],axis=1,sort=True)
population_data=pd.concat([population_df1,population_df2],axis=1,sort=True)
# axis=0 or 'index'纵向拼接行,sort=True对列索引进行排序
ChinaData=pd.concat([economy_data,population_data],axis=0,sort=True)
print(ChinaData.shape)
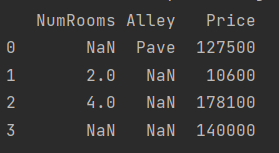
第2关:数据清洗
任务描述
本关任务:数据清洗
包括:空白行删除、数据完整性检验、数据填充、插值等内容。
相关知识
删除缺失值: dropna()
# 用于删除含有缺失值的行或列
def dropna(
axis: Axis = 0,
how: str = "any",
thresh=None,
subset: IndexLabel = None,
inplace: bool = False,
)
'''
axis参数:轴向,{0或“index”,1或“columns”},默认为0。0或“index”:删除包含缺失值的行。1或“columns”:删除包含缺失值的列。
how参数:删除形式,{‘any’,‘all’},默认为‘any’。'any'表示只要含有缺失值(至少一个)就删除该行或列;'all'表示如果全为缺失值就删除该行或列。
thresh参数:thresh=n表示保留至少含有n个非NaN值的行或列。如果行或列中的非缺失值数量小于等于thresh,则会被删除。
subset参数:可选参数,用于指定要检查缺失值的特定列名或行索引。
inplace参数:是否在原来的dataframe上进行就地修改,默认为False,将修改后的DataFrame作为新的对象返回。
'''
检测缺失值 isnull()和notnull()
DataFrame.isnull() 识别缺失值,返回包含True和False的 DataFrame。
DataFrame.notnull() 识别非缺失值,返回包含True和False的 DataFrame。
上述两方法结合 sum 函数可用于检测数据序列中缺失值的分布情况。
填充缺失值 fillna()
# 用指定值替换缺失值。关键参数:value、method和axis。
def fillna(
value: object | ArrayLike | None = None,
method: FillnaOptions | None = None,
axis: Axis | None = None,
inplace: bool = False,
limit=None,
downcast=None,
)
'''
value参数:表示指定的填充值。可以是数值、字典、Series 对象 或 DataFrame 对象。
method参数: {'backfill', 'bfill', 'pad', 'ffill'},'pad'/'ffill'表示前向填充,'backfill'/'bfill'表示后向填充。method = 'bfill'后向填充,用后面的非缺失值填充该缺失值;method = 'ffill'前向填充,用前面的非缺失值填充。如果用户没有传递任何值给value,则使用该属性。
axis参数:表示操作轴向,{0或“index”,1或“columns”},默认为1(列)。
inplace参数:是否在原来的dataframe上进行就地修改,默认为False,将修改后的DataFrame作为新的对象返回。
limit参数:整数值,限制轴的填充个数。如果指定了method,则是用于指定连续前向/后向填充的最大数量。如果没有指定 method,则是要填充的轴的最大 NaN 值数。
downcast参数: dict字典,用于将填充结果数据类型降低为更小的类型,以减少内存占用。比如Float64转换为int64。
'''
拉格朗日插值 lagrange()
scipy 库的 interpolate 模块提供了 lagrange 函数来进行 Lagrange 插值计算
scipy.interpolate.lagrange(x,w)
# x:一维array,表示插值节点的x坐标。
# w:一维array,表示插值节点的y坐标,数目需要与x对应。
本关代码
# -*- coding: utf-8 -*-
import pandas as pd
'''
第2关 数据清洗
'''
d1 = pd.read_csv('D:\VS\Python数据处理与编程\Python数据分析4\economy-60-78.csv',index_col = 0)
d2 = pd.read_csv('D:\VS\Python数据处理与编程\Python数据分析4\economy-79-19.csv',index_col = 0)
d3 = pd.read_csv('D:\VS\Python数据处理与编程\Python数据分析4\population-60-78.csv',index_col = 0)
d4 = pd.read_csv('D:\VS\Python数据处理与编程\Python数据分析4\population-79-19.csv',index_col = 0)
d12 = pd.concat([d1,d2],axis = 1,sort=True)
d34 = pd.concat([d3,d4],axis = 1,sort=True)
ChinaData = pd.concat([d34,d12],sort=True)
print("原DataFrame的shape:"+str(ChinaData.shape))
linenum=ChinaData.shape[0]
'''
请针对ChinaData完成如下操作。
'''
# 2.1 删除空白行
ChinaData.dropna(how='all',inplace=True)
linenum-=ChinaData.shape[0]
print("新DataFrame的shape:"+str(ChinaData.shape))
print("%d个空白行被删除!"%linenum)
# 2.2 查找数据最完整(空值最少)的年份并输出
# 提示:notnull(),根据值找索引
null_summary=ChinaData.isnull().sum()
#print(null_sum)
min_year=null_summary.loc[null_summary==null_summary.min()].index[0]
print(min_year)
# 2.3 前向填充"男性吸烟率(吸烟男性占所有成年人比例)",输出2000年至2019年的数据
# fillna,ffill
data=ChinaData.loc['男性吸烟率(吸烟男性占所有成年人比例)',:]
data.fillna(method='ffill',inplace=True)
print(data.loc['2000':'2019'])
# 2.4 用2015年到2018年 4年的gdp数据对2019年GDP数值进行拉格朗日插值预测,输出预测结果
# lagrange
# 注意:x的取值从0开始,即x = np.array([0,1,2,3]),代表2015至2018 4年,2019年的x取值为4。
from scipy.interpolate import lagrange
import numpy as np
gdp=ChinaData.loc['GDP',:]
x=np.array([0,1,2,3])
y=gdp.loc['2015':'2018'].values
#返回一个拉格朗日插值多项式。x和y为数据序列
lagf=lagrange(x,y)
# 4为缺失值所在的位置,ins_y为插值结果
ins_y=lagf(4)
print(ins_y)
# 2.5 用线性插值法填充“入学率,高等院校,男生(占总人数的百分比)”1995年到2002年数据,并输出插值后的94年至03年的数据
# interp1d
from scipy.interpolate import interp1d
student=ChinaData.loc['入学率,高等院校,男生(占总人数的百分比)',:]
print(student)
linevalue=interp1d(x=[0,9],y=[student.loc['1994'],student.loc['2003']],kind='linear')
student.loc['1995':'2002']=linevalue(range(1,9))
print(student.loc['1994':'2003'])
第3关:数据转换
任务描述
本关任务:数据转换。包括数据标准化和数据离散化。
相关知识
离差标准化
离差标准化就是对原始数据进行线性变换并映射至 [0,1] 区间的方法。该方法需要自行编写实现函数。
等宽离散化
等宽离散化将数据的值域分成宽度相同区间,根据数据所在区间取值,实现连续变量的离散化。pandas.cut()函数可以实现这种操作,关键参数:x和bins。
x :待离散化的数据。
bins :离散化类别数。
注意:
获得离散化结果后,常用value_counts()方法对离散化结果进行频数统计,以观察离散化数据的分布情况。
pandas.cut()
# 把一组数据分割成离散的区间
def cut(
x,
bins,
right: bool = True,
labels=None,
retbins: bool = False,
precision: int = 3,
include_lowest: bool = False,
duplicates: str = "raise",
ordered: bool = True,
)
'''
x参数:一维数组、列表、DataFrame的一列等。(必须是一维的)
bins参数:被切割后的区间(标量、数组、pandas)
•int型的标量:将x平分成bins份,会对x的范围进行扩展0.1%,以包括x的最大值和最小值。
•标量序列:被分割后每一个bin的区间边缘,没有对'x'的范围进行扩展。
•pandas.IntervalIndex:间隔索引,定义要使用的精确区间。
right参数:是否包含区间右部。默认为True,包含区间右部,左开右闭(]。如果为False,则是不包含右部,左闭右开[)。
labels参数:给分割后的bins打标签,长度必须和区间相等。
retbins参数:是否返回划分后的区间,默认为False。当bins为int型标量时使用非常有用,默认为False。
precision参数:保留区间小数点的位数,默认为3。
include_lowest参数:划分后的区间是否包含最低值,默认为False。
duplicates参数:当bins列表里有重复的数据时的处理方式,默认为'raise',表示抛出异常。可选参数为'raise'和'drop','drop'表示直接删除至保留一个。
ordered参数:默认为True,表示标签是否有序。如果为 True,则将对生成的分类进行排序。如果为 False,则生成的分类将是无序的(必须提供标签labels)。
'''
bins = pd.IntervalIndex.from_tuples([(0, 2), (3, 6), (7, 8)]) # 创建IntervalIndex
print(pd.cut(np.array([2,6,4,8,1,5,9]),bins))
# 输出结果如下
[(0.0, 2.0], (3.0, 6.0], (3.0, 6.0], (7.0, 8.0], (0.0, 2.0], (3.0, 6.0], NaN]
Categories (3, interval[int64, right]): [(0, 2] < (3, 6] < (7, 8]]
import pandas as pd
# 创建一个DataFrame对象
data=pd.DataFrame({
'score':[67,55,78,1,80,95,100]})
# 使用cut函数对score列进行分组划分
data['grade_1']=pd.cut(data['score'],bins=[1,60,70,80,90,100],right=True,include_lowest=False)
data['grade_2']=pd.cut(data['score'],bins=[1,60,70,80,90,100],right=False,include_lowest=True)
'''将bins设置为[1,60,70,80,90,100],right=True时,此时的区间为(1,60],(60,70],(70,80],(80,90],(90,100]。
第一个数字1是不包括在内的,若是遇到小于等于1的数据将会得到NaN的结果。此时我们可以将include_lowest设置为True,划分后的区间包含最低值。
'''
data['grade_3']=pd.cut(data['score'],bins=[1,60,70,80,90,100],right=True,include_lowest=True)
print(data)
score grade_1 grade_2 grade_3
0 67 (60.0, 70.0] [60.0, 70.0) (60.0, 70.0]
1 55 (1.0, 60.0] [1.0, 60.0) (0.999, 60.0]
2 78 (70.0, 80.0] [70.0, 80.0) (70.0, 80.0]
3 1 NaN [1.0, 60.0) (0.999, 60.0]
4 80 (70.0, 80.0] [80.0, 90.0) (70.0, 80.0]
5 95 (90.0, 100.0] [90.0, 100.0) (90.0, 100.0]
6 100 (90.0, 100.0] NaN (90.0, 100.0]
pd.value_counts()
# 用来统计数据表中,指定列里有多少个不同的数据值,并计算每个不同值有在该列中的个数
def value_counts(
values,
sort: bool = True,
ascending: bool = False,
normalize: bool = False,
bins=None,
dropna: bool = True,
)
'''
values参数:ndarray (1-d),需要进行频数统计的数据。
sort参数:是否要进行排序;默认True:按值排序。
ascending参数: 默认False降序排列;True升序排列。
normalize参数: 是否要对计算结果进行标准化并显示标准化后的结果,默认是False。
bins参数: 可以自定义分组区间
dropna参数:是否删除缺失值NaN,默认True删除,也是不将NaN值统计在内。
'''
def value_counts(
subset: Sequence[Hashable] | None = None,
normalize: bool = False,
sort: bool = True,
ascending: bool = False,
dropna: bool = True,
)
'''
subset参数:可选参数,标签或者标签列表 ,计算时要用的列。如果你想要对特定列的数据进行计数,就需要提供这一参数;默认会对所有列进行计数。
'''
本关代码
# -*- coding: utf-8 -*-
import pandas as pd
'''
第3关 数据转换
'''
d1 = pd.read_csv('D:\VS\Python数据处理与编程\Python数据分析4\economy-60-78.csv',index_col = 0)
d2 = pd.read_csv('D:\VS\Python数据处理与编程\Python数据分析4\economy-79-19.csv',index_col = 0)
d3 = pd.read_csv('D:\VS\Python数据处理与编程\Python数据分析4\population-60-78.csv',index_col = 0)
d4 = pd.read_csv('D:\VS\Python数据处理与编程\Python数据分析4\population-79-19.csv',index_col = 0)
d12 = pd.concat([d1,d2],axis = 1,sort=True)
d34 = pd.concat([d3,d4],axis = 1,sort=True)
ChinaData = pd.concat([d34,d12],sort=True)
'''
请针对ChinaData实现下列操作
'''
# 3.1 对“人口,总数”数据(1960-2018)进行离差标准化,并输出。
# 提示:自定义离差标准化函数,注意统计年份区间
def MinMaxScale(data):
return (data-data.min())/(data.max()-data.min())
population=ChinaData.loc['人口,总数','1960':'2018']
# print(population)
npopu=MinMaxScale(population)
print(npopu)
# 3.2 对“GDP 增长率(年百分比)”(1961-2018)数据进行等宽离散化为7类,输出分布情况
# 提示:cut,注意统计年份区间
gdp_ratio=ChinaData.loc['GDP 增长率(年百分比)','1961':'2018']
result=pd.cut(x=gdp_ratio,bins=7)
print(result.value_counts())