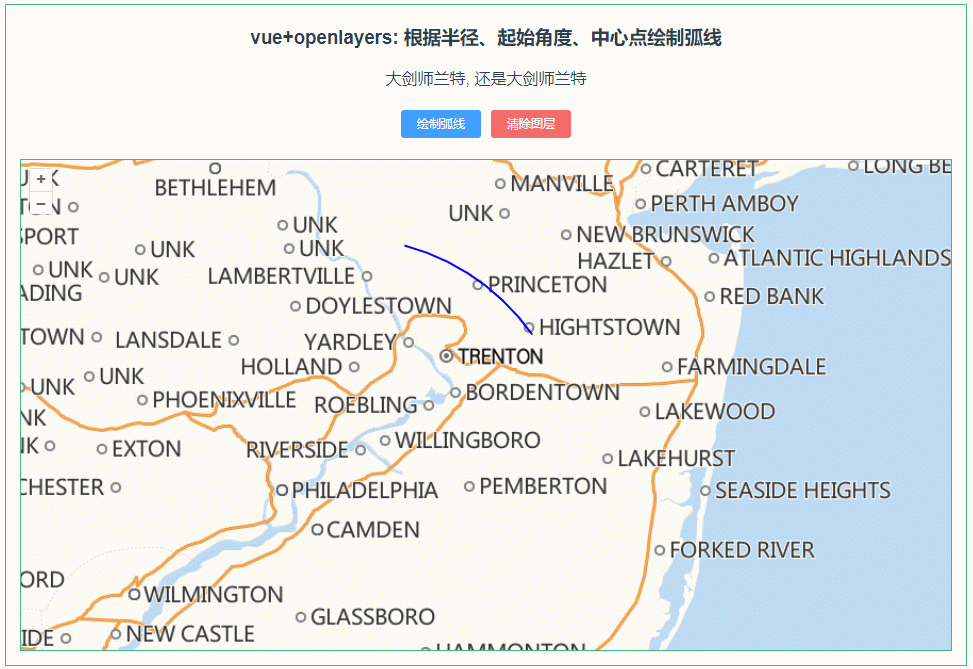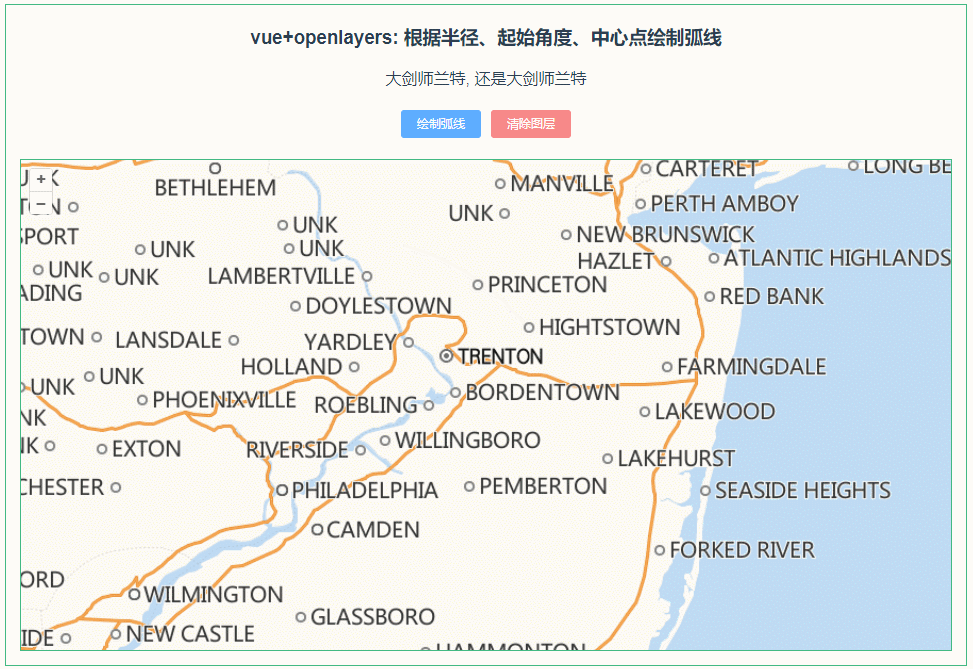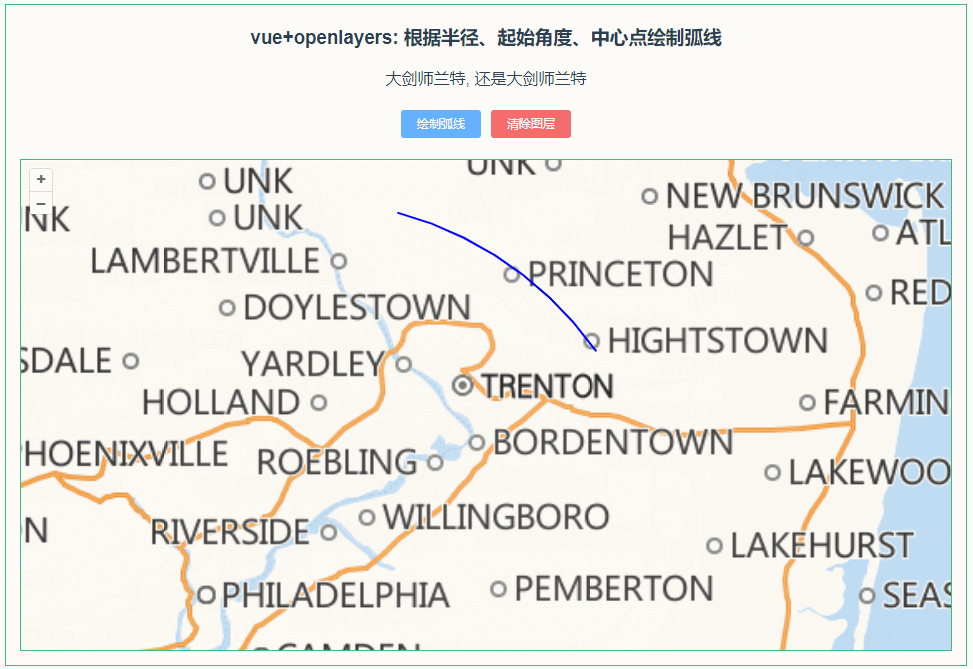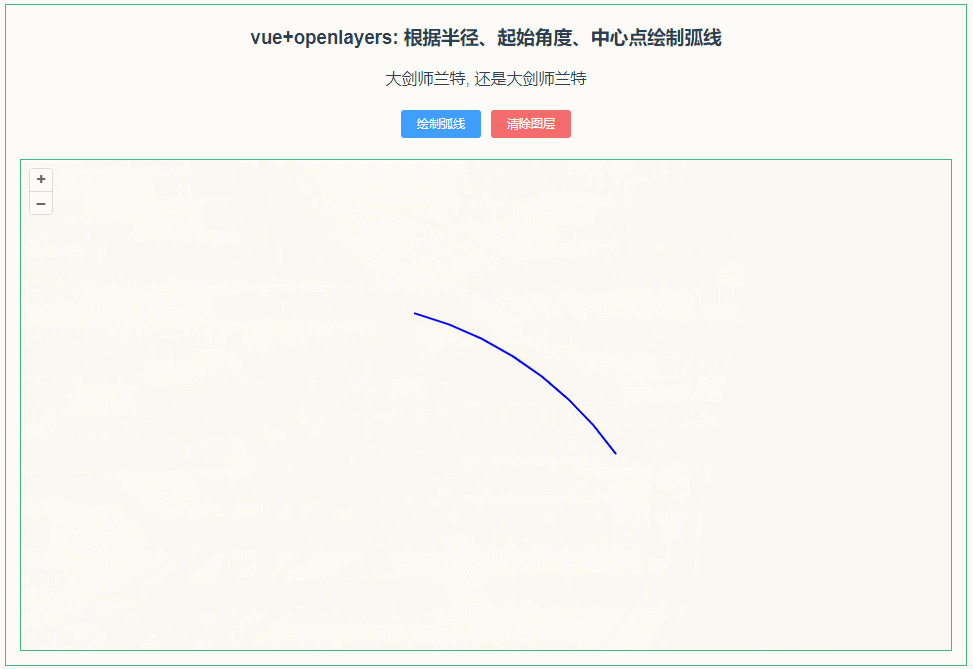
稀疏化一词来源于条件计算理念。在稠密模型中,所有参数都发挥作用,而稀疏化可以只运行整个系统的某些部分。
前文提到 Shazeer 对机器翻译中的 MoE 进行了探索。条件计算(网络中只有某些部分处于活动状态)使得在不增加计算量的情况下能够扩大模型的规模,因此,每层 MoE 都可以包含成千上万的专家网络。
但是这种设计带来了一些挑战。例如,虽然扩大 batch size 通常更有利于提高模型性能,但 MOE 中的 batch size 会随着数据在激活状态的专家网络中的流动而缩小。例如,如果 batch size 为 10 个 token,其中 5 个 token 可能在一个专家网络中结束,而另外 5 个 token 可能在 5 个不同的专家网络中结束,从而导致 batch size 大小不均和利用率不足的情况。


















![Linux入门指令(2)[暑假提升]](https://i-blog.csdnimg.cn/direct/bfaf68144d394d10b73431522cf11cc4.png)