The machine learning documents provided offer an extensive exploration into the principles and applications of machine learning models, focusing on the structured elements of input, model, and output. This approach helps in understanding how data is processed, how decisions on model selection are made based on scenario requirements, and what outcomes are expected from these models.
iuww520 iuww520 iuww520 iuww520 iuww520 iuww520 iuww520 iuww520
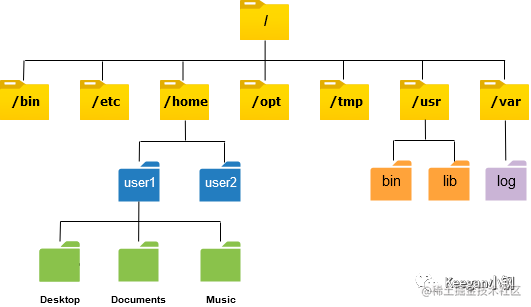
Inputs
The documents begin by detailing the types of data used as input in machine learning models. Two primary data types are explored: structured and unstructured. Structured data, highly organized and easily searchable, typically appears in formats like databases and spreadsheets, making it ideal for models requiring direct queries and quick access to specific variables. Unstructured data includes images, videos, and texts, which necessitate significant preprocessing to extract useful features for training. The choice of data impacts the preprocessing required, such as normalization to scale data appropriately or encoding to convert categorical data into a numerical format suitable for various algorithms.
Model
The selection of a machine learning model depends on the nature of the input data and the specific needs of the application scenario. Various machine learning paradigms are detailed:
1. Supervised Learning: Used with labeled data to predict an output based on input features, suitable for classification and regression tasks.
2. Unsupervised Learning: Fits scenarios without labels, where the model identifies patterns within the data, used for clustering and association tasks.
3. Reinforcement Learning: Employed in environments where an agent learns from actions through rewards, applicable in gaming, navigation, and realtime decision making.
The type of model selected is influenced by the problem's complexity, the clarity of desired outcomes, and available computational resources.
Output
Outputs from machine learning models vary depending on the algorithm and application, ranging from predictions of future events and classifications into categories, to the discovery of patterns. For instance, in healthcare, outputs might include disease classification based on imaging, while in finance, predictions could involve stock movements or credit scoring. The practical application of these outputs demonstrates the models' accuracy and reliability.
The documents also address challenges like data sparsity and high-dimensional data, which can significantly affect model performance. Techniques such as data imputation for handling missing values and dimensionality reduction to simplify high-dimensional input spaces are discussed, enhancing model effectiveness by ensuring they are trained on relevant and comprehensive datasets.

























![Pytest单元测试系列[v1.0.0][Pytest基础]](https://img-blog.csdnimg.cn/20200414100531977.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2Rhd2VpX3lhbmcwMDAwMDA=,size_16,color_FFFFFF,t_70)





![[吃瓜教程]南瓜书第6章支持向量机](https://i-blog.csdnimg.cn/direct/fd9e6f80d10e42d0b3465334dd9bd5f7.png)