目录
1. 引言
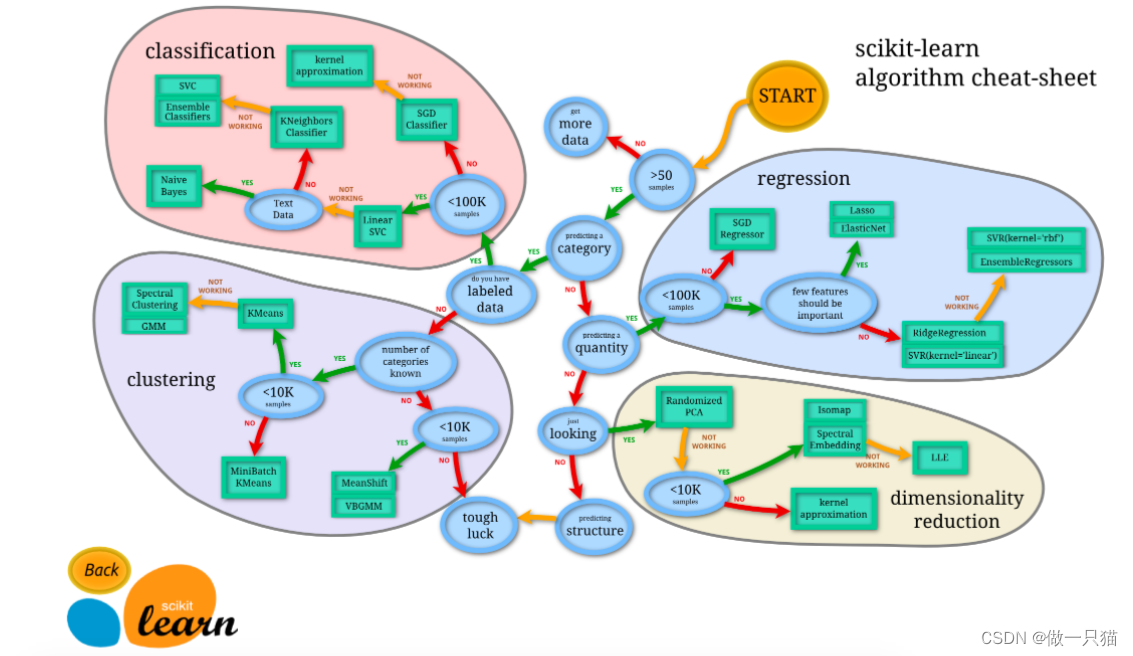
Scikit-learn(简称sklearn)是Python中一个非常流行的机器学习库,它提供了各种机器学习算法的实现,包括分类、回归、聚类、降维等。sklearn建立在NumPy、SciPy和Matplotlib等库之上,为数据科学家和机器学习爱好者提供了简单、高效的数据挖掘和数据分析工具。
2. 安装sklearn
安装sklearn的前提是已经安装了Python、NumPy和SciPy。你可以使用pip来安装sklearn:
pip install -U scikit-learn3. 导入sklearn
在Python脚本中,你可以根据需要导入sklearn中的不同模块。以下是一些常见的导入方式:
from sklearn.datasets import load_iris, make_regression
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LinearRegression
from sklearn.metrics import confusion_matrix, classification_report
from sklearn.preprocessing import StandardScaler4. 加载数据集
sklearn自带了一些标准数据集,如鸢尾花数据集(iris)和手写数字数据集(digits)。你也可以使用make_regression等函数来生成模拟数据。
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征变量
y = iris.target # 目标值
# 生成模拟回归数据
X_reg, y_reg = make_regression(n_samples=100, n_features=1, noise=0.1)5. 数据预处理
在训练模型之前,通常需要对数据进行预处理,如数据清洗、特征缩放等。sklearn提供了丰富的数据预处理工具。
# 数据分割为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 特征缩放(标准化)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)6. 训练模型
选择适当的机器学习算法,并使用训练数据来训练模型。
# 使用K近邻算法进行分类
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train_scaled, y_train)
# 使用线性回归算法进行回归
reg = LinearRegression()
reg.fit(X_reg[:, np.newaxis], y_reg)7. 评估模型
使用测试集来评估模型的性能。
# 预测测试集结果
y_pred_class = knn.predict(X_test_scaled)
y_pred_reg = reg.predict(X_reg[:, np.newaxis])
# 评估分类模型
print(confusion_matrix(y_test, y_pred_class))
print(classification_report(y_test, y_pred_class))
# 评估回归模型(使用R^2分数或其他指标)
score = reg.score(X_reg[:, np.newaxis], y_reg)
print("R^2 Score:", score)8. 保存和加载模型
你可以使用joblib库来保存和加载训练好的模型。
from joblib import dump, load
# 保存模型
dump(knn, 'knn_model.joblib')
# 加载模型
loaded_knn = load('knn_model.joblib')9. 自定义数据
除了使用sklearn自带的数据集,你还可以使用自己的数据集。确保数据集的格式正确,并进行适当的预处理。
10. 更多
sklearn还提供了许多高级功能,如流水线(Pipeline)、集成方法(Ensemble Methods)、网格搜索(GridSearchCV)等,用于优化模型和提高性能。你可以参考官方文档和教程来深入了解这些功能。
11. 注意事项
- 确保理解所选机器学习算法的原理和适用场景。
- 适当调整模型的参数以优化性能。
- 注意数据的预处理和特征选择对模型性能的影响。
- 使用交叉验证等技术来评估模型的泛化能力。
- 不断探索和尝试新的算法和技术,以找到最适合你问题的解决方案。