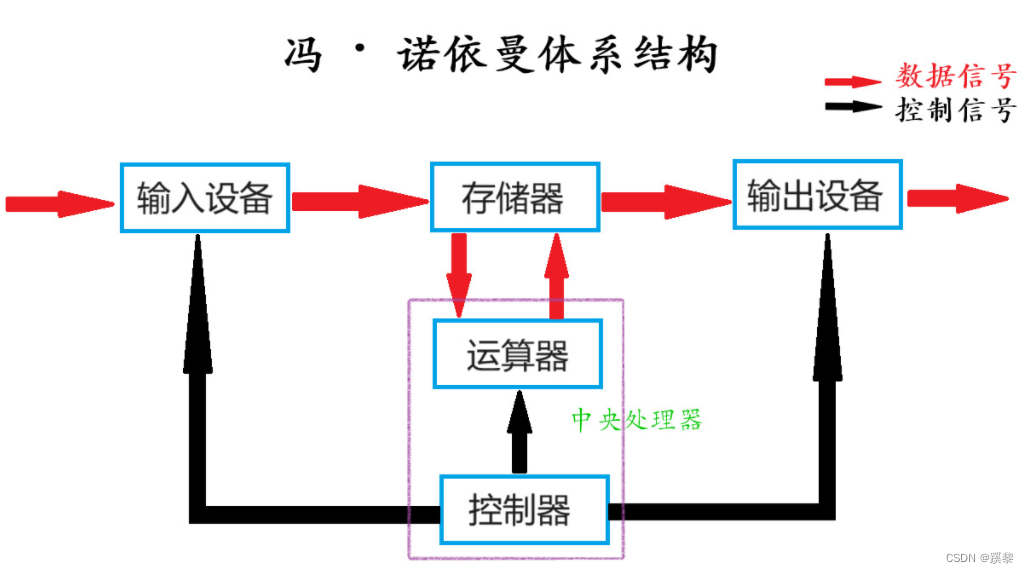
文章目录
SOTA
(指标 3D mAP, NDS,分割 mIOU)
可以查看nscenes 官网
https://www.nuscenes.org/object-detection?externalData=all&mapData=all&modalities=Camera
2D 检测
Anchor-based方案
Two-stage Detectors
RCNN
Fast RCNN
Faster RCNN
One-stage Detectors
SSD
YOLO
Anchor-free方案
FCOS
CenterNet
Transformer方案:DETR
单目3d检测
先验几何信息
自动标注: 基于sam,点云投影到图像获取点云分割 label,生成3Dboxes
单目bev,一般是多目,小鹅通
3d bev cam范式
核心:视角转换
流派:
MLP: VPN,PON
LSS:BEVDET,BEVDET4D,bevdepth
Transformer: (DETR2d延伸)DETR3D, BEVFORMER, PETR, PETRV2
Transformer attention is all you need 2017
Transformer中selfatt和muitlhead-att
ViT vision transformer ICLR 2021google
TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
非局部 network
https://blog.csdn.net/shanglianlm/article/details/104371212
DETR 2020
facebook
https://github.com/facebookresearch/detr
https://blog.csdn.net/weixin_43959709/article/details/115708159

BEIT: BERT Pre-Training of Image Transformer
https://blog.csdn.net/HX_Image/article/details/119177742
viT 2021
https://arxiv.org/pdf/2010.11929
DETR3D 2021
https://arxiv.org/pdf/2110.06922
https://github1s.com/WangYueFt/detr3d/tree/main
2D feat --> Decoder --> 3Dpred
ref-p query
https://github.com/WangYueFt/detr3d
transformer=dict(
type='Detr3DTransformer',
decoder=dict(
type='Detr3DTransformerDecoder',
num_layers=6,
return_intermediate=True,
transformerlayers=dict(
type='DetrTransformerDecoderLayer',
attn_cfgs=[
dict(
type='MultiheadAttention',
embed_dims=256,
num_heads=8,
dropout=0.1),
dict(
type='Detr3DCrossAtten',
pc_range=point_cloud_range,
num_points=1,
embed_dims=256)
],
feedforward_channels=512,
ffn_dropout=0.1,
operation_order=('self_attn', 'norm', 'cross_attn', 'norm',
'ffn', 'norm')))),
)
transformer 的层 一般6层,工业的话用3层,bevformer tiny 3层
PETR 2022
global attention 显存占用大
通过position embedding 利用 attention多视角图像特征关联
transformer=dict(
type='PETRTransformer',
decoder=dict(
type='PETRTransformerDecoder',
return_intermediate=True,
num_layers=6,
transformerlayers=dict(
type='PETRTransformerDecoderLayer',
attn_cfgs=[
dict(
type='MultiheadAttention',
embed_dims=256,
num_heads=8,
dropout=0.1),
dict(
type='PETRMultiheadAttention',
embed_dims=256,
num_heads=8,
dropout=0.1),
],
feedforward_channels=2048,
ffn_dropout=0.1,
with_cp=True,
operation_order=('self_attn', 'norm', 'cross_attn', 'norm',
'ffn', 'norm')),
)),
bevformer
比PETR的 全局注意力计算少,
(一般是多路聚合)
Deformable attention ——> 内外参bev空间索引 图像特征
git clone https://github.com/megvii-research/PETR.git
LSS
bevdet
LSS + centerPoint
IDA+BDA + scale NMS
input data augmentation, bev data augmentation
caddn
LSS + 深度监督
imvoxelNet