前言
个人介绍
博主介绍:✌目前全网粉丝3W+,csdn博客专家、Java领域优质创作者,博客之星、阿里云平台优质作者、专注于Java后端技术领域。
涵盖技术内容:Java后端、大数据、算法、分布式微服务、中间件、前端、运维等。
博主所有博客文件目录索引:博客目录索引(持续更新)
视频平台:b站-Coder长路
当前博客相关内容介绍
学习kerberos主要原因是目前部门里会有测试kerberos连通性的问题bug,所以以此来系统学习下kerberos安全认证,主要是学习在kerberos安全配置下如何去访问各个大数据组件。
Kerberos安全认证系列学习教程(B站):https://www.bilibili.com/video/BV1rr421t7Zt【马士兵的系列课程】
学习配套源码(Gitee):https://gitee.com/changluJava/demo-exer/tree/master/bigdata/kerberos/kerberosAuth
一、安装Zookeeper3.6.4集群
1.1、节点划分
| 节点IP | 节点名称 | Zookeeper |
|---|---|---|
| 192.168.10.130 | node1 | |
| 192.168.10.131 | node2 | |
| 192.168.10.132 | node3 | * |
| 192.168.10.133 | node4 | * |
| 192.168.10.134 | node5 | * |
1.2、详细搭建Zookeeper集群
1、安装及解压Zookeeper并配置环境变量
下载地址:https://zookeeper.apache.org/releases.html
将zookeeper安装包上传到node3节点/opt/tools目录下并解压:
cd /opt/tools
# 解压到/opt/server目录
tar -zxvf ./apache-zookeeper-3.6.4-bin.tar.gz -C /opt/server/
配置环境变量:
#进入vim /etc/profile
vim /etc/profile
# 在最后加入:
export ZOOKEEPER_HOME=/opt/server/apache-zookeeper-3.6.4-bin
export PATH=$PATH:$ZOOKEEPER_HOME/bin
#使配置生效
source /etc/profile
2、在node3节点配置Zookeeper
# /opt/server/apache-zookeeper-3.6.4-bin/conf
cd $ZOOKEEPER_HOME/conf
# 修改文件名称
mv zoo_sample.cfg zoo.cfg
# 修改配置文件
vim zoo.cfg
配置zoo.cfg中内容如下:
- 修改其中的dataDir存放data数据目录
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/opt/server/apache-zookeeper-3.6.4-bin/data
clientPort=2181
server.1=node3:2888:3888
server.2=node4:2888:3888
server.3=node5:2888:3888
3、配置zookeeper的日志文件
修改日志文件输出路径:
vim /opt/server/apache-zookeeper-3.6.4-bin/conf/log4j.properties
# 配置项如下,修改指定的日志文件目录
zookeeper.log.dir=/opt/server/apache-zookeeper-3.6.4-bin/logs
创建日志文件目录:
mkdir /opt/server/apache-zookeeper-3.6.4-bin/logs
4、将配置好的zookeeper 发送到 node4,node5节点
scp -r /opt/server/apache-zookeeper-3.6.4-bin node4:/opt/server/
scp -r /opt/server/apache-zookeeper-3.6.4-bin node5:/opt/server/
5、各个节点上创建数据目录,并配置zookeeper环境变量
在node3,node4,node5各个节点上创建zoo.cfg中指定的数据目录"/opt/server/apache-zookeeper-3.6.4-bin/data",也就是data目录。
mkdir /opt/server/apache-zookeeper-3.6.4-bin/data
在node4,node5节点配置zookeeper环境变量:
#进入vim /etc/profile
vim /etc/profile
# 在最后加入:
# zookeeper 3.6.4
export ZOOKEEPER_HOME=/opt/server/apache-zookeeper-3.6.4-bin
export PATH=$PATH:$ZOOKEEPER_HOME/bin
#使配置生效
source /etc/profile
6、各个节点创建节点 ID
在node3,node4,node5各个节点路径"/opt/server/apache-zookeeper-3.6.4-bin/data"中添加myid文件分别写入1,2,3:
#在node3的/opt/server/apache-zookeeper-3.6.4-bin/data中创建myid文件写入1
echo "1" > /opt/server/apache-zookeeper-3.6.4-bin/data/myid
#在node4的/opt/server/apache-zookeeper-3.6.4-bin/data中创建myid文件写入2
echo "2" > /opt/server/apache-zookeeper-3.6.4-bin/data/myid
#在node5的/opt/server/apache-zookeeper-3.6.4-bin/data中创建myid文件写入3
echo "3" > /opt/server/apache-zookeeper-3.6.4-bin/data/myid
7、各个节点启动zookeeper, 并检查进程状态
#各个节点启动zookeeper命令
zkServer.sh start
#检查各个节点zookeeper进程状态
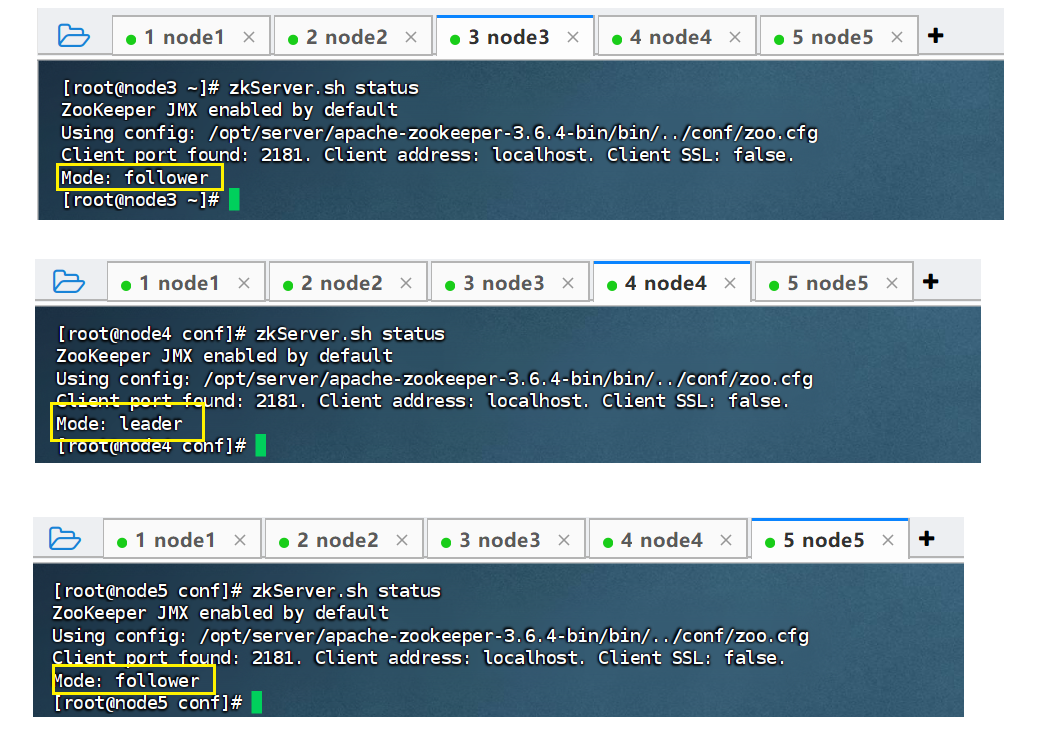
zkServer.sh status
我们检查下三个节点的状态:下面就是集群模式,leader是主,follower是从
二、搭建Hadoop3.3.4集群
2.1、节点划分
名词介绍:
- NN:NameNode
- DN:DataNode
- ZKFC:ZKFC即ZKFailoverController,是基于Zookeeper的故障转移控制器,它负责控制NameNode的主备切换,ZKFC会监测NameNode的健康状态,当发现Active NameNode出现异常时会通过Zookeeper进行一次新的选举,完成Active和Standby状态的切换
- JN:JN通常指的是JournalNode。JournalNode是Hadoop HDFS(Hadoop Distributed File System)高可用性(HA)模式下的一个组件,它用于记录NameNode(HDFS的元数据管理节点)的事务编辑日志(EditLog)。
- RM:ResourceManager
- NM:NodeManager
| 节点IP | 节点名称 | NN | DN | ZKFC | JN | RM | NM |
|---|---|---|---|---|---|---|---|
| 192.168.10.130 | node1 | * | * | * | |||
| 192.168.10.131 | node2 | * | * | * | |||
| 192.168.10.132 | node3 | * | * | * | |||
| 192.168.10.133 | node4 | * | * | * | |||
| 192.168.10.134 | node5 | * | * | * |
2.2、详细配置所有节点的Hadoop配置文件(hdfs、yarn)
1、各个节点安装HDFS HA自动切换必须的依赖
yum -y install psmisc
2、各个节点上传下载好的Hadoop 安装包到 node1节点上,并解压
下载地址:https://archive.apache.org/dist/hadoop/common/
cd /opt/tools
# 解压到/opt/server目录
tar -zxvf ./hadoop-3.3.4.tar.gz -C /opt/server/
3、在node1 - node5节点上配置 Hadoop的环境变量
vim /etc/profile
# 配置文件内容
export HADOOP_HOME=/opt/server/hadoop-3.3.4/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
#使配置生效
source /etc/profile
注意:由于为了效率我们是每个节点上都手动解压之后每次配置一个文件后都进行分发,这样速度会快些。
4、配置$HADOOP_HOME/etc/hadoop 下的 hadoop-env.sh文件
vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh
#配置内容
export JAVA_HOME=/opt/server/jdk1.8.0_221
分发文件:
xsync $HADOOP_HOME/etc/hadoop/hadoop-env.sh
5、配置$HADOOP_HOME/etc/hadoop 下的 hdfs-site.xml文件
编辑配置文件:
vim $HADOOP_HOME/etc/hadoop/hdfs-site.xml
配置内容如下:
<configuration>
<property>
<!--这里配置逻辑名称,可以随意写 -->
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<!-- 禁用权限 -->
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<!-- 配置namenode 的名称,多个用逗号分割 -->
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<!-- dfs.namenode.rpc-address.[nameservice ID].[name node ID] namenode 所在服务器名称和RPC监听端口号 -->
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node1:8020</value>
</property>
<property>
<!-- dfs.namenode.rpc-address.[nameservice ID].[name node ID] namenode 所在服务器名称和RPC监听端口号 -->
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node2:8020</value>
</property>
<property>
<!-- dfs.namenode.http-address.[nameservice ID].[name node ID] namenode 监听的HTTP协议端口 -->
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node1:50070</value>
</property>
<property>
<!-- dfs.namenode.http-address.[nameservice ID].[name node ID] namenode 监听的HTTP协议端口 -->
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node2:50070</value>
</property>
<property>
<!-- namenode 共享的编辑目录, journalnode 所在服务器名称和监听的端口 -->
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node3:8485;node4:8485;node5:8485/mycluster</value>
</property>
<property>
<!-- namenode高可用代理类 -->
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<!-- 使用ssh 免密码自动登录 -->
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<!-- journalnode 存储数据的地方 -->
<name>dfs.journalnode.edits.dir</name>
<value>/opt/server/hadoop-3.3.4/data/journal/node/local/data</value>
</property>
<property>
<!-- 配置namenode自动切换 -->
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
说明:配置了namenode为node1、node2,journalnode为node3、node4、node5。
分发文件:
xsync $HADOOP_HOME/etc/hadoop/hdfs-site.xml
6、配置$HADOOP_HOME/ect/hadoop/core-site.xml
vim $HADOOP_HOME/etc/hadoop/core-site.xml
配置文件内容如下:
<configuration>
<property>
<!-- 为Hadoop 客户端配置默认的高可用路径 -->
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<!-- Hadoop 数据存放的路径,namenode,datanode 数据存放路径都依赖本路径,不要使用 file:/ 开头,使用绝对路径即可
namenode 默认存放路径 :file://${hadoop.tmp.dir}/dfs/name
datanode 默认存放路径 :file://${hadoop.tmp.dir}/dfs/data
-->
<name>hadoop.tmp.dir</name>
<value>/opt/server/hadoop-3.3.4/data/</value>
</property>
<property>
<!-- 指定zookeeper所在的节点 -->
<name>ha.zookeeper.quorum</name>
<value>node3:2181,node4:2181,node5:2181</value>
</property>
</configuration>
说明:指定了zookeeper的节点为node3、node4、node5。
分发文件:
xsync $HADOOP_HOME/etc/hadoop/core-site.xml
7、配置$HADOOP_HOME/etc/hadoop/yarn-site.xml
vim $HADOOP_HOME/etc/hadoop/yarn-site.xml
配置内容如下:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<!-- 配置yarn为高可用 -->
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<!-- 集群的唯一标识 -->
<name>yarn.resourcemanager.cluster-id</name>
<value>mycluster</value>
</property>
<property>
<!-- ResourceManager ID -->
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<!-- 指定ResourceManager 所在的节点 -->
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node1</value>
</property>
<property>
<!-- 指定ResourceManager 所在的节点 -->
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node2</value>
</property>
<property>
<!-- 指定ResourceManager Http监听的节点 -->
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node1:8088</value>
</property>
<property>
<!-- 指定ResourceManager Http监听的节点 -->
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node2:8088</value>
</property>
<property>
<!-- 指定zookeeper所在的节点 -->
<name>yarn.resourcemanager.zk-address</name>
<value>node3:2181,node4:2181,node5:2181</value>
</property>
<property>
<!-- 关闭虚拟内存检查 -->
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 启用节点的内容和CPU自动检测,最小内存为1G -->
<!--<property>
<name>yarn.nodemanager.resource.detect-hardware-capabilities</name>
<value>true</value>
</property>-->
</configuration>
说明:设置了resourcesmanager的节点为node1、node2,对应注册服务中心为node3、node4、node5。
分发文件:
xsync $HADOOP_HOME/etc/hadoop/yarn-site.xml
8、配置$HADOOP_HOME/etc/hadoop/mapred-site.xml
vim $HADOOP_HOME/etc/hadoop/mapred-site.xml
配置内容如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
分发文件:
xsync $HADOOP_HOME/etc/hadoop/mapred-site.xml
9、配置$HADOOP_HOME/etc/hadoop/workers文件
vim $HADOOP_HOME/etc/hadoop/workers
配置内容:
node3
node4
node5
说明:设置了datanode为node3、node4、node5。
分发文件:
xsync $HADOOP_HOME/etc/hadoop/workers
10、配置$HADOOP_HOME/sbin/start-dfs.sh 和 stop-dfs.sh两个文件中顶部添加以下参数,防止启动错误
①配置start-dfs.sh
vim $HADOOP_HOME/sbin/start-dfs.sh
配置到顶部参数:
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root
分发文件:
xsync $HADOOP_HOME/sbin/start-dfs.sh
②配置stop-dfs.sh
vim $HADOOP_HOME/sbin/stop-dfs.sh
配置到顶部参数:
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root
分发文件:
xsync $HADOOP_HOME/sbin/stop-dfs.sh
11、配置 $HADOOP_HOME/sbin/start-yarn.sh 和stop-yarn.sh 两个文件顶部添加以下参数,防止启动错误
①配置start-yarn.sh
vim $HADOOP_HOME/sbin/start-yarn.sh
配置到顶部参数:
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
分发文件:
xsync $HADOOP_HOME/sbin/start-dfs.sh
②配置stop-yarn.sh
vim $HADOOP_HOME/sbin/stop-yarn.sh
配置到顶部参数:
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
分发文件:
xsync $HADOOP_HOME/sbin/stop-yarn.sh
2.3、初始化HDFS
【node3,node4,node5】节点上启动zookeeper:
zkServer.sh start
【node1】格式化zookeeper:
hdfs zkfc -formatZK
【node3,node4,node5】在每台journalnode中启动所有的journalnode:
hdfs --daemon start journalnode
【node1】格式化namenode:
hdfs namenode -format
【node1】中启动namenode,以便同步其他namenode:
hdfs --daemon start namenode
【node2】上执行,高可用模式配置namenode,使用下列命令来同步namenode(在需要同步的namenode中执行:
hdfs namenode -bootstrapStandby
2.4、启动、停止HDFS与yarn以及访问WEB界面
【node1】上启动HDFS,启动Yarn:
# 也可以使用start-all.sh命令启动Hadoop集群。
start-dfs.sh
start-yarn.sh
【node1】上停止集群:
# 也可以使用stop-all.sh命令停止Hadoop集群。
stop-dfs.sh
stop-yarn.sh
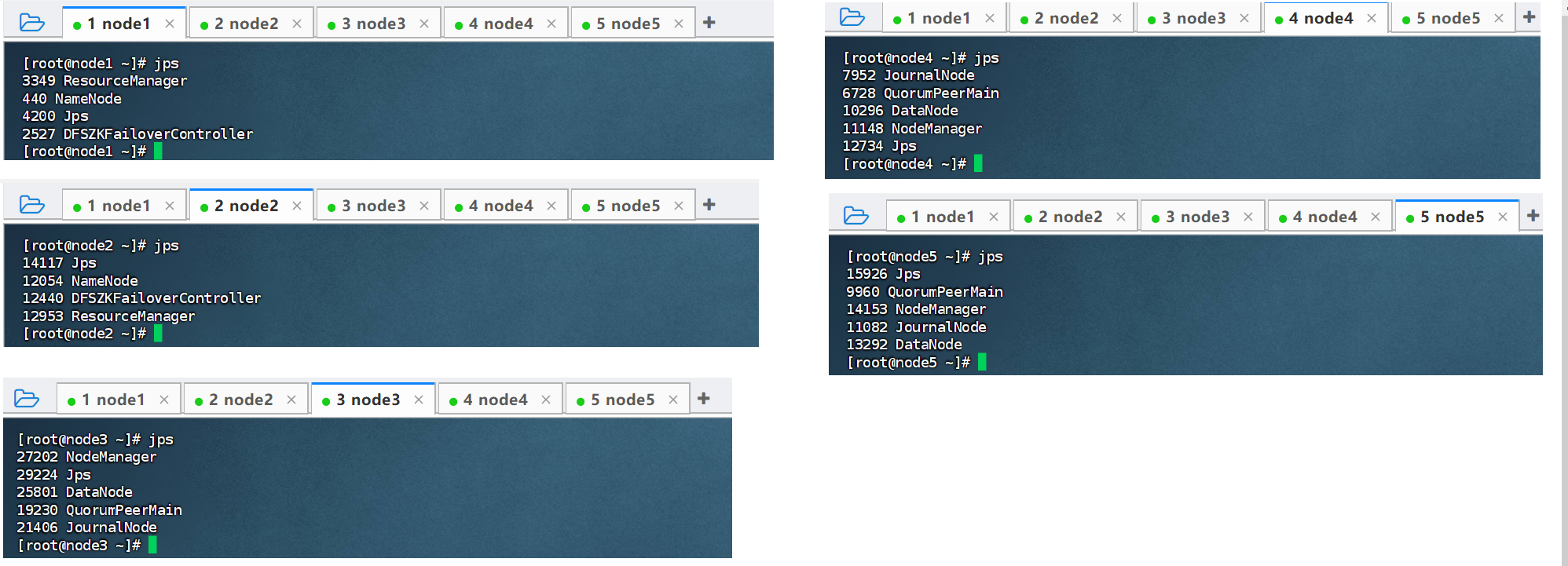
执行完成之后,可以看到五台节点当前的启动的服务分布:
在windows环境中配置下hosts域名映射:
- 路径位置:C:\Windows\System32\drivers\etc
192.168.10.130 node1
192.168.10.131 node2
192.168.10.132 node3
192.168.10.133 node4
192.168.10.134 node5
接着刷新DNS缓存:
# 刷新DNS解析缓存
ipconfig /flushdns
访问HDFS : http://node1:50070、http://node2:50070
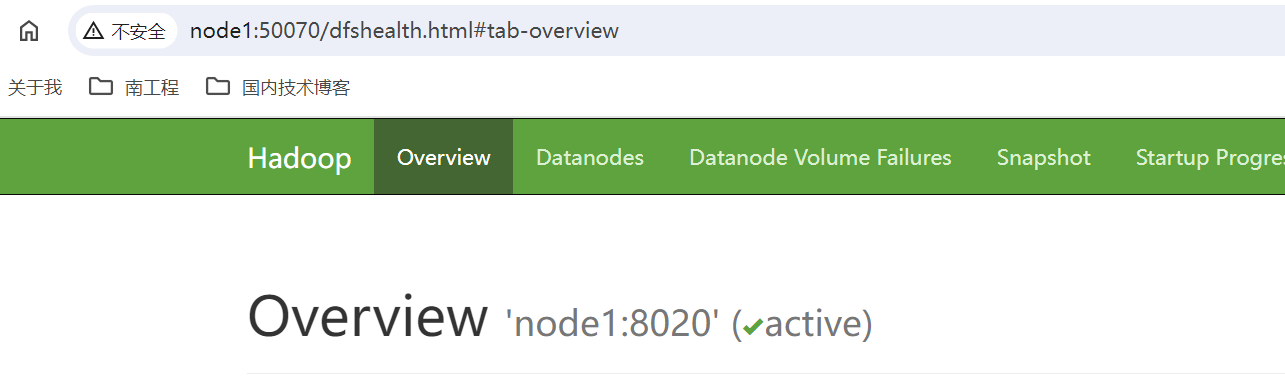
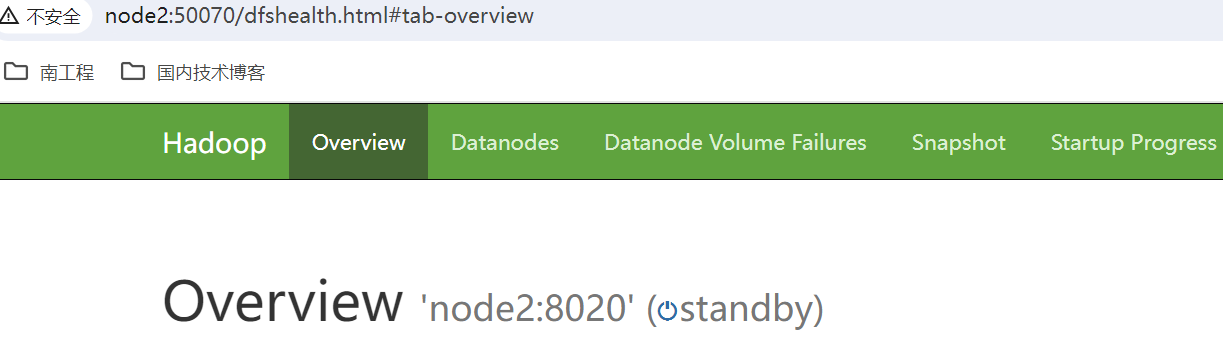
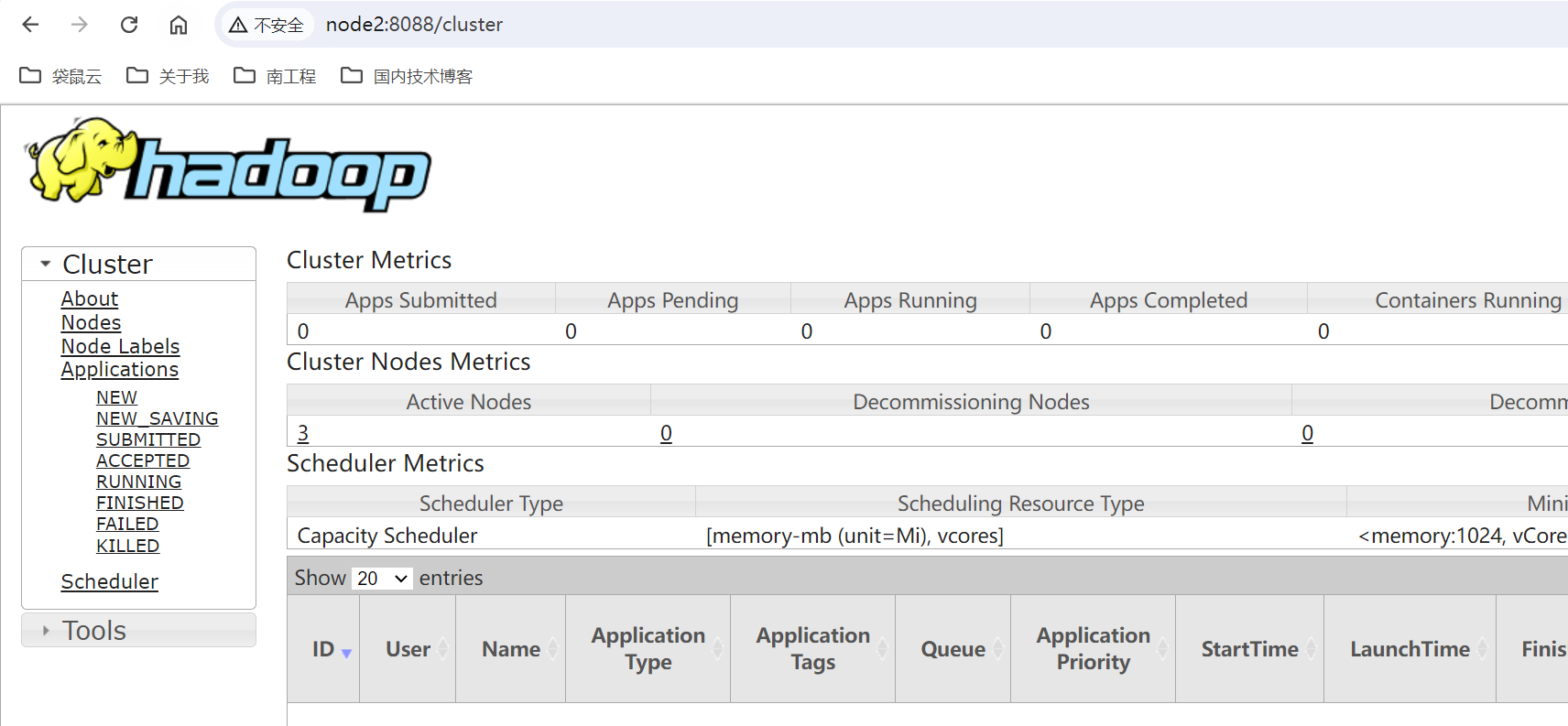
访问yarn:http://node1:8088,会直接跳转到node2的yarn管理界面
三、搭建Hive3.1.3集群
3.1、节点划分
| 节点IP | 节点名称 | Hive服务器 | Hive客户端 | MySQL |
|---|---|---|---|---|
| 192.168.10.130 | node1 | * | ||
| 192.168.10.131 | node2 | * | ||
| 192.168.10.132 | node3 | * |
3.2、搭建MySQL5.7.27作为元数据(node2)
选择MySQL5.7.27:

安装步骤:
①卸载Centos7自带mariadb
# 查找
rpm -qa|grep mariadb
# mariadb-libs-5.5.52-1.el7.x86_64
# 卸载,根据指定名字
rpm -e mariadb-libs-5.5.52-1.el7.x86_64 --nodeps
②上传MySQL安装压缩包
# 创建mysql安装包存放点
mkdir /opt/server/mysql
# 进入到上传目录
cd /opt/tools
# 解压
tar xvf mysql-5.7.27-1.el7.x86_64.rpm-bundle.tar -C /opt/server/mysql/
# 安装依赖
yum -y install libaio
yum -y install libncurses*
yum -y install perl perl-devel
yum -y install net-tools
# 切换到安装目录
cd /opt/server/mysql/
# 安装
rpm -ivh mysql-community-common-5.7.27-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-5.7.27-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-5.7.27-1.el7.x86_64.rpm
rpm -ivh mysql-community-server-5.7.27-1.el7.x86_64.rpm
③启动MySQL服务
#启动mysql
systemctl start mysqld.service
#查看生成的临时root密码(获取到密码之后)
cat /var/log/mysqld.log | grep password
④修改初始的随机密码,并进行授权
# 登录mysql
mysql -u root -p
Enter password: #输入在日志中生成的临时密码
# 更新root密码 设置为root
set global validate_password_policy=0;
set global validate_password_length=1;
set password=password('root');
# 授权账户 root、root
grant all privileges on *.* to 'root' @'%' identified by 'root';
# 刷新
flush privileges;
⑤设置MySQL自启动
#mysql的启动和关闭 状态查看
systemctl stop mysqld
systemctl status mysqld
systemctl start mysqld
#建议设置为开机自启动服务
systemctl enable mysqld
#查看是否已经设置自启动成功
systemctl list-unit-files | grep mysqld
3.3、详细搭建Hive服务
hive下载地址:https://archive.apache.org/dist/hive/

1、下载好的Hive 安装包上传到 【node1】 节点上 ,并修改名称
cd /opt/tools
# 解压到/opt/server目录
tar -zxvf ./apache-hive-3.1.3-bin.tar.gz -C /opt/server/
cd /opt/server
# 修改服务名
mv apache-hive-3.1.3-bin hive-3.1.3
2、将解压好的Hive 安装包发送到【node3】节点上
scp -r /opt/server/hive-3.1.3/ node3:/opt/server/
3、配置 【node1 、node3 】两台节点的 Hive 环境变量
vim /etc/profile
export HIVE_HOME=/opt/server/hive-3.1.3/
export PATH=$PATH:$HIVE_HOME/bin
#source 生效
source /etc/profile
4、在 【node1】 节点 $HIVE_HOME/conf 下创建 hive-site.xml 并配置
vim $HIVE_HOME/conf/hive-site.xml
配置如下:
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/opt/server/hive-3.1.3/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node2:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
</configuration>
5、在【node3】 节点 $HIVE_HOME/conf/ 中创建 hive-site.xml并配置
vim $HIVE_HOME/conf/hive-site.xml
配置如下:
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/opt/server/hive-3.1.3/warehouse</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node1:9083</value>
</property>
</configuration>
6、【node1 、 node3 】节点删除 $HIVE_HOME/lib 下" guava" 包,使用 Hadoop 下的包替换
#删除Hive lib目录下“guava-19.0.jar ”包
rm -rf /opt/server/hive-3.1.3/lib/guava-19.0.jar
#将Hadoop lib下的“guava”包拷贝到Hive lib目录下
cp /opt/server/hadoop-3.3.4/share/hadoop/common/lib/guava-27.0-jre.jar /opt/server/hive-3.1.3/lib/
7、【node1、node3】将"mysql-connector-java-5.1.38.jar" 驱动包上传到 $HIVE_HOME/lib目录下
这里node1,node3节点都需要传入,将mysql驱动包上传$HIVE_HOME/lib/目录下。
8、【node2】节点中使用mysq创建hive数据库
# 初始化前先创建数据库hive
mysql -u root -proot
create database hive charset=utf8;
8、【node1 】节点中初始化 Hive
#初始化hive,hive2.x版本后都需要初始化
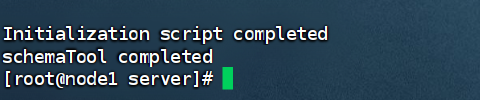
schematool -dbType mysql -initSchema
若是出现下面信息表示初始化完成:
可查看下【node2】mysql中数据库hive初始化内容:
mysql -uroot -proot
use hive;
show tables;
3.4、HiveServer2与Beeline
Hive Beeline 是Hive0.11版本引入的新命令行客户端,它是基于SQLLine Cli的JDBC客户端。Beeline工作模式有两种,即本地嵌入模式和远程模式。嵌入模式情况下,它返回一个嵌入式的Hive(类似于Hive CLI)。而远程模式则是通过Thrift协议与某个单独的HiveServer2进程进行连接通信。
想要通过Beeline写SQL查询Hive数据,必须配置HiveServer2服务,HiveServer2(HS2)是一种使客户端能够对Hive执行查询的服务。HiveServer2是已被废弃的HiveServer1(仅支持单客户端访问)的继承者。HiveServer2支持多客户端并发和身份验证。它旨在为JDBC和ODBC等开放API客户端提供更好的支持。
通过beeline和Hiverserver2连接操作Hive时,需要指定一个用户,这个用户可以随意指定,但是需要在HDFS中允许使用代理用户配置,需要在每台Hadoop 节点【node1 - node5】配置core-site.xml:
vim $HADOOP_HOME/etc/hadoop/core-site.xml
配置内容如下:
<!-- 配置代理访问用户 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
配置好完成之后,将以上文件分发到各个hadoo节点上,然后重新启动HDFS。
xsync $HADOOP_HOME/etc/hadoop/core-site.xml
重新启动HDFS:
# 也可以使用stop-all.sh命令停止Hadoop集群。
stop-dfs.sh
stop-yarn.sh
# 也可以使用start-all.sh命令启动Hadoop集群。
start-dfs.sh
start-yarn.sh
3.5、Hive 操作
服务端和客户端 client 操作
在服务端和客户端操作Hive,操作Hive之前首先启动HDFS集群,命令为:start-all.sh,启动HDFS集群后再进行Hive以下操作:
#在node1中登录Hive ,创建表test
hive
hive> create table test (id int,name string,age int ) row format delimited fields terminated by '\t';
#向表test中插入数据
hive> insert into test values(1,"zs",18);
#在node1启动Hive metastore
hive --service metastore &
#在node3上登录Hive客户端查看表数据
hive
hive> select * from test;
OK
1 zs 18
注意:客户端hive连接需要原本客户端服务器中配置了hive的meastore远程连接配置,否则无法远程连接。
本地嵌入模式使用 Beeline
首先在Hive服务端node1启动HiverServer2,然后在node1上可以直接登录beeline,操作如下:
#在node1 Hive服务端启动hiveserver2
hiveserver2
#在node1 Hive服务端进行操作
beeline
beeline> !connect jdbc:hive2://node1:10000
随意输入用户名和密码即可
远程模式使用 Beeline
在实际开发中建议远程模式使用beeline,这样并不是在Hive的服务端进行操作,比较安全。远程使用beeline就是直接找到Hive的客户端然后启动beeline,前提是需要在Hive的服务端启动Hiveserver2服务,这种情况下客户端的beeline是通过Thrift协议与服务端的HiveServer2进程进行连接通信。
#在node1节点上启动HiveServer2,如启动可以忽略
hiveserver2
#在node3客户端登录beeline,然后可以正常查询SQL语句
beeline
beeline> !connect jdbc:hive2://node1:10000
四、搭建Hbase集群
4.1、节点划分
这里选择HBase版本为2.2.6,搭建HBase各个角色分布如下:
| 节点IP | 节点名称 | HBase服务 |
|---|---|---|
| 192.168.10.133 | node3 | RegionServer |
| 192.168.10.134 | node4 | HMaster,RegionServer |
| 192.168.10.135 | node5 | RegionServer |
4.2、详细搭建HBase集群
Hbase下载地址:https://archive.apache.org/dist/hbase/2.2.6/
1、将下载好的安装包发送到【node4】 节点上 , 并解压 , 配置环境变量
cd /opt/tools
# 解压到/opt/server目录
tar -zxvf ./hbase-2.2.6-bin.tar.gz -C /opt/server/
当前节点配置HBase环境变量:
#配置HBase环境变量
vim /etc/profile
export HBASE_HOME=/opt/server/hbase-2.2.6/
export PATH=$PATH:$HBASE_HOME/bin
#使环境变量生效
source /etc/profile
2、【node4】配置$HBASE_HOME/conf/hbase-env.sh
编辑配置文件:
vim $HBASE_HOME/conf/hbase-env.sh
配置内容如下:
#配置HBase JDK
export JAVA_HOME=/opt/server/jdk1.8.0_221
#配置 HBase不使用自带的zookeeper
export HBASE_MANAGES_ZK=false
#Hbase中的jar包和HDFS中的jar包有冲突,以下配置设置为true,启动hbase不加载HDFS jar包
export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="true"
3、【node4】配置$HBASE_HOME/conf/hbase-site.xml
编辑配置文件:
vim $HBASE_HOME/conf/hbase-site.xml
删除原始配置,配置如下内容:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://mycluster/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node3,node4,node5</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
4、【node4】配置$HBASE_HOME/conf/regionservers ,配置 RegionServer 节点
编辑配置文件:
vim $HBASE_HOME/conf/regionservers
配置文件内容:
node3
node4
node5
5、【node4】配置backup-masters文件
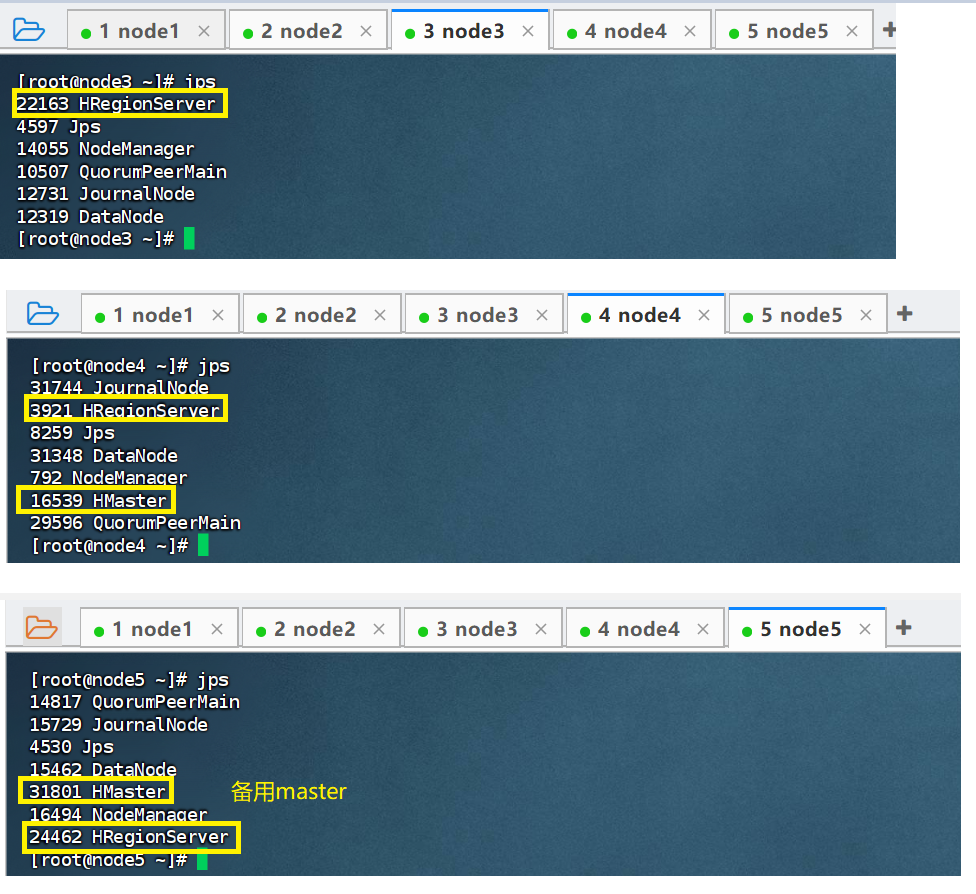
手动创建$HBASE_HOME/conf/backup-masters文件,指定备用的HMaster,需要手动创建文件,这里写入node5,在HBase任意节点都可以启动HMaster,都可以成为备用Master ,可以使用命令:hbase-daemon.sh start master启动。
#创建 $HBASE_HOME/conf/backup-masters 文件,写入node5
vim backup-masters
# 配置内容如下
node5
6、【node4】复制hdfs-site.xml 到 $HBASE_HOME/conf/ 下
cp /opt/server/hadoop-3.3.4/etc/hadoop/hdfs-site.xml /opt/server/hbase-2.2.6/conf/
7、【node4】将HBase 安装包发送到 【node3、node5】 节点上,并在 node3 , node5 节点上配置 HBase 环境变量
scp -r /opt/server/hbase-2.2.6 node3:/opt/server/
scp -r /opt/server/hbase-2.2.6 node5:/opt/server/
# 注意:在node3、node5上配置HBase环境变量。
vim /etc/profile
# 配置内容如下
export HBASE_HOME=/opt/server/hbase-2.2.6/
export PATH=$PATH:$HBASE_HOME/bin
#使环境变量生效
source /etc/profile
8、重启Zookeeper 、重启 HDFS 及启动 HBase集群
【node3-5】全部重启zookeeper:
zkServer.sh restart
【node1】重启HDFS:
# 关闭整个集群服务
stop-all.sh
# 启动hdfs、yarn
start-dfs.sh
start-yarn.sh
【node4】启动Hbase集群:
#注意:一定要重启Zookeeper,重启HDFS,在node4节点上启动HBase集群
start-hbase.sh
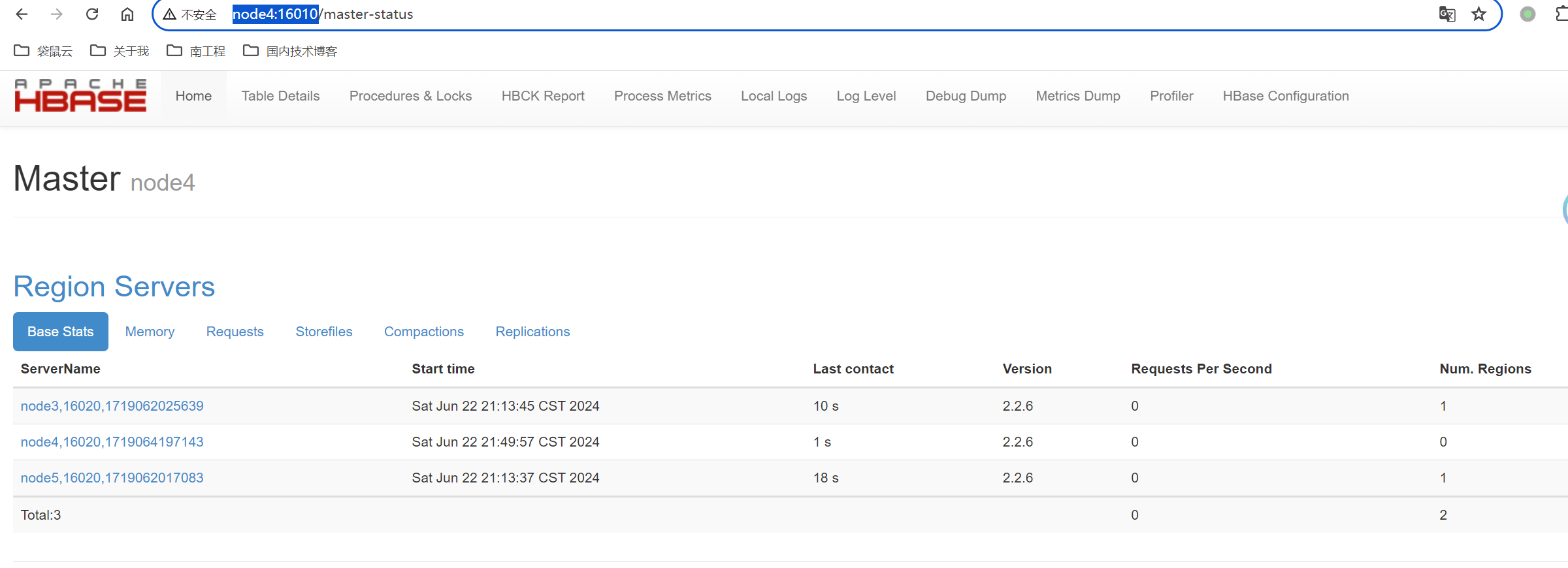
#访问WebUI,http://node4:16010。
# 停止集群:在任意一台节点上stop-hbase.sh
若是出现下面报错:

重新执行下面命令即可:
start-hbase.sh
对于node3、node4、node5启动柜的服务如下:
此时可以访问web的ui界面:http://node4:16010/
4.3、HBase操作
在Hbase中【node4】创建表test,指定’cf1’,'cf2’两个列族,并向表test中插入几条数据:
#进入hbase
[root@node4 ~]# hbase shell
#创建表test
create 'test','cf1','cf2'
#查看创建的表
list
#向表test中插入数据
put 'test','row1','cf1:id','1'
put 'test','row1','cf1:name','zhangsan'
put 'test','row1','cf1:age',18
#查询表test中rowkey为row1的数据
get 'test','row1'
五、搭建Kafka3.3.1集群
5.1、节点划分
择Kafka版本为3.3.1,对应的搭建节点如下:
| 节点IP | 节点名称 | Kafka服务 |
|---|---|---|
| 192.168.10.130 | node1 | kafka broker |
| 192.168.10.131 | node2 | kafka broker |
| 192.168.10.132 | node3 | kafka broker |
5.2、详细搭建Kafka集群
下载Kafka3.3.1地址:https://archive.apache.org/dist/kafka/3.3.1/
1、将Kakfa解压包上传到/opt/tools目录下
cd /opt/tools
# 解压到/opt/server目录
tar -zxvf ./kafka_2.13-3.3.1.tgz -C /opt/server/
2、【node1】配置Kafka环境变量
vim /etc/profile
# 在node1节点上编辑profile文件,vim /etc/profile
# Kafka
export KAFKA_HOME=/opt/server/kafka_2.13-3.3.1/
export PATH=$PATH:$KAFKA_HOME/bin
#使环境变量生效
source /etc/profile
3、【node1】配置Kafka
在node1节点上配置Kafka,进入$KAFKA_HOME/config中修改server.properties,修改内容如下:
vim $KAFKA_HOME/config/server.properties
# 配置内容如下
broker.id=0 #注意:这里要唯一的Integer类型
log.dirs=/opt/server/kafka_2.13-3.3.1/logs #真实数据存储的位置
zookeeper.connect=node3:2181,node4:2181,node5:2181 #zookeeper集群
4、【node1】以上配置发送到【node2 , node3】节点上
node1节点执行分发命令:
scp -r /opt/server/kafka_2.13-3.3.1 node2:/opt/server/
scp -r /opt/server/kafka_2.13-3.3.1 node3:/opt/server/
发送完成后,在node2、node3节点上配置Kafka的环境变量:
vim /etc/profile
# 在node2、node3节点上编辑profile文件,vim /etc/profile
# Kafka
export KAFKA_HOME=/opt/server/kafka_2.13-3.3.1/
export PATH=$PATH:$KAFKA_HOME/bin
#使环境变量生效
source /etc/profile
5、修改【node2,node3】 节点上的 server.properties 文件
node2、node3节点修改$KAFKA_HOME/config/server.properties文件中的broker.id,node2中修改为1,node3节点修改为2:
vim $KAFKA_HOME/config/server.properties
# node2节点配置
broker.id=1
# node3节点配置
broker.id=2
6、【node1】创建Kafka启动脚本,分发到【node2、node3】
node1上创建$KAFKA_HOME/bin路径中编写Kafka启动脚本"startKafka.sh",内容如下:
vim $KAFKA_HOME/bin/startKafka.sh
# 配置内容如下:
nohup /opt/server/kafka_2.13-3.3.1/bin/kafka-server-start.sh /opt/server/kafka_2.13-3.3.1/config/server.properties > /opt/server/kafka_2.13-3.3.1/kafkalog.txt 2>&1 &
# 设置权限
chmod +x $KAFKA_HOME/bin/startKafka.sh
node1上进行分发到node2、node3:
scp /opt/server/kafka_2.13-3.3.1/bin/startKafka.sh node2:/opt/server/kafka_2.13-3.3.1/bin/
scp /opt/server/kafka_2.13-3.3.1/bin/startKafka.sh node3:/opt/server/kafka_2.13-3.3.1/bin/
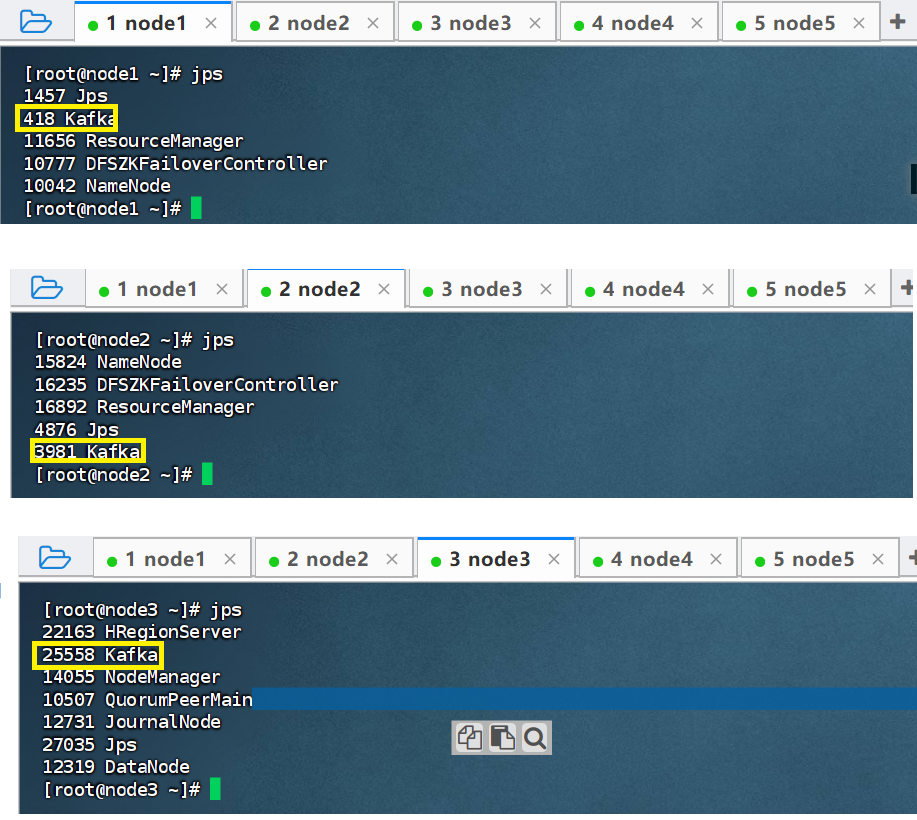
7、【node1、node2、node3】启动Kafka
在node1,node2,node3三台节点上分别执行startKafka.sh脚本,启动Kafka:
startKafka.sh
启动脚本之后会有一个kafka服务:
5.3、Kafka命令操作
#创建topic
kafka-topics.sh --create --bootstrap-server node1:9092,node2:9092,node3:9092 --topic testtopic --partitions 3 --replication-factor 3
#查看集群中的topic
kafka-topics.sh --list --bootstrap-server node1:9092,node2:9092,node3:9092
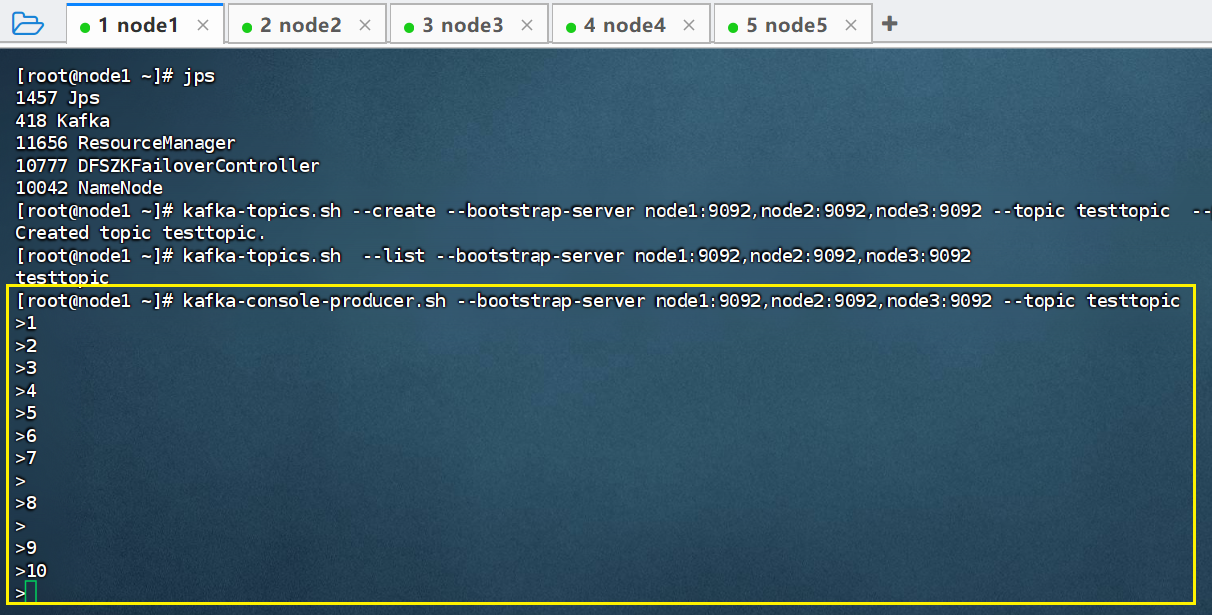
#【node1】console控制台向topic 中生产数据
kafka-console-producer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic testtopic
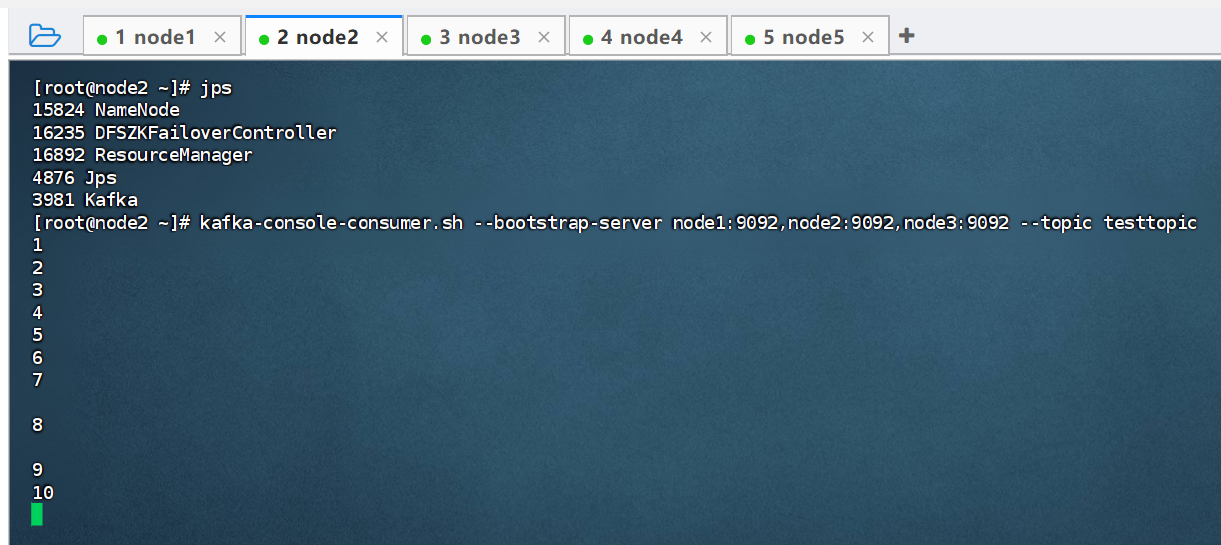
#【node2】console控制台消费topic中的数据
kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic testtopic
# 注意:以上创建好之后,可以向Kafka topic中写入数据测试Kafka是否正常。
#删除topic
kafka-topics.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --delete --topic testtopic
效果如下:
在node1节点中我们启动生产客户端:
同时在node2节点中启动消费客户端,此时我们在生产客户端中生产的消息,消费客户端都能够收到:
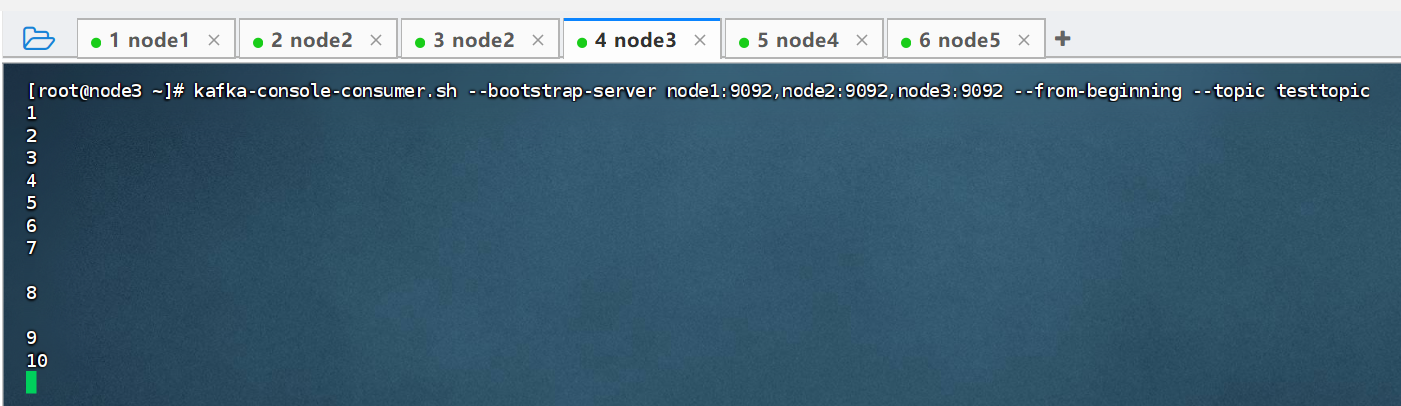
此时可以在node3中重新接受从一开始的消息,重新消费下:
kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --from-beginning --topic testtopic
小结
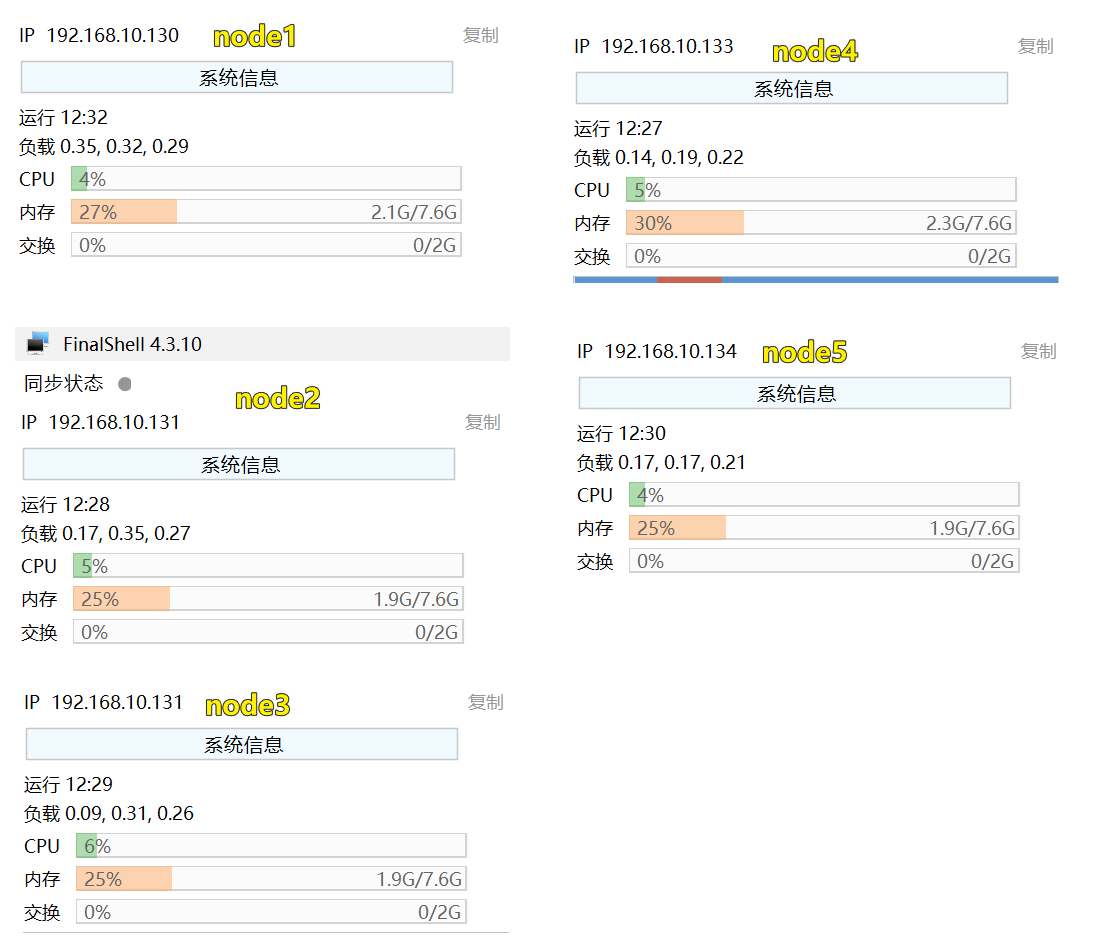
服务器内存使用量
服务总览:
| 节点IP | 节点名称 | 搭建服务 |
|---|---|---|
| 192.168.10.130 | node1 | NN、ZKFC、RM、Hive服务器、kafka broker |
| 192.168.10.131 | node2 | NN、ZKFC、RM、MySQL、kafka broker |
| 192.168.10.132 | node3 | zookeeper、DN、JN、NM、Hive客户端、RegionServer、kafka broker |
| 192.168.10.133 | node4 | zookeeper、DN、JN、NM、HMaster,RegionServer |
| 192.168.10.134 | node5 | zookeeper、DN、JN、NM、RegionServer |
当前启动的各个节点服务内存消耗了在2G左右
快速关闭集群命令
# 【node1、node2、node3】关闭kafka
kafka-server-stop.sh
# 【node4或者任意一台】停止整个hbase集群
stop-hbase.sh
# 【node1-3,对于启动的需要关闭】关闭hive
ps aux | grep hiveserver2
kill -9 <PID>
# 【node1】直接关闭hdfs、yarn集群
stop-all.sh
# 【node3、4、5】依次关闭zookeeper服务
zkServer.sh stop
快速启动集群命令
# 【node3、4、5】依次打开zookeeper服务
zkServer.sh start
# 【node1】启动hdfs、yarn集群
start-dfs.sh
start-yarn.sh
# 【node1-3】hive根据实际情况来进行启动
# 在node1启动Hive metastore
hive --service metastore &
# 在node1 Hive服务端启动hiveserver2
hiveserver2
# 【hbase4】hbase启动
start-hbase.sh
# 【node1、node2、node3】打开kafka
startKafka.sh
参考文章
[1]. 实现不同主机间scp复制时无需认证/输入密码:https://blog.csdn.net/inkflow/article/details/98793199
[2]. 配置xsync 和写xsync配置文件的两种方法!!怎么设置免密?…… Linux虚拟机scp命令、rsync命令与xsync命令的使用和具体实现:https://blog.csdn.net/2201_75806156/article/details/133443592



































![[微信小程序知识点]自定义组件-拓展-外部样式类](https://i-blog.csdnimg.cn/direct/41c263ef1d9c4e23a0b3a233e65c5c82.png)