顺序表解决了扩容的问题,但是定点增删的时间复杂度比较大。链表就很好的解决了这个问题。
以下代码均用C语言来写。
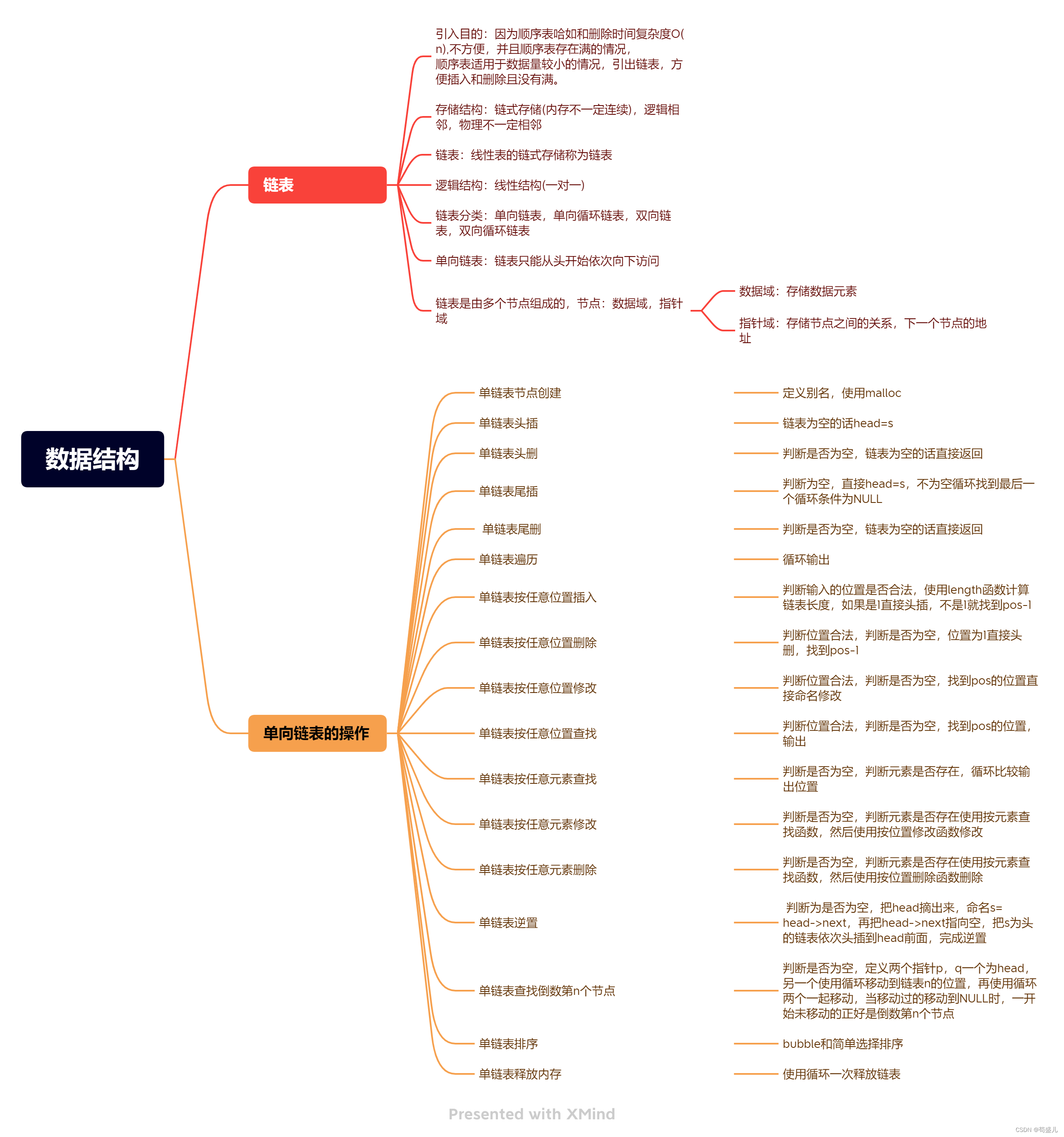
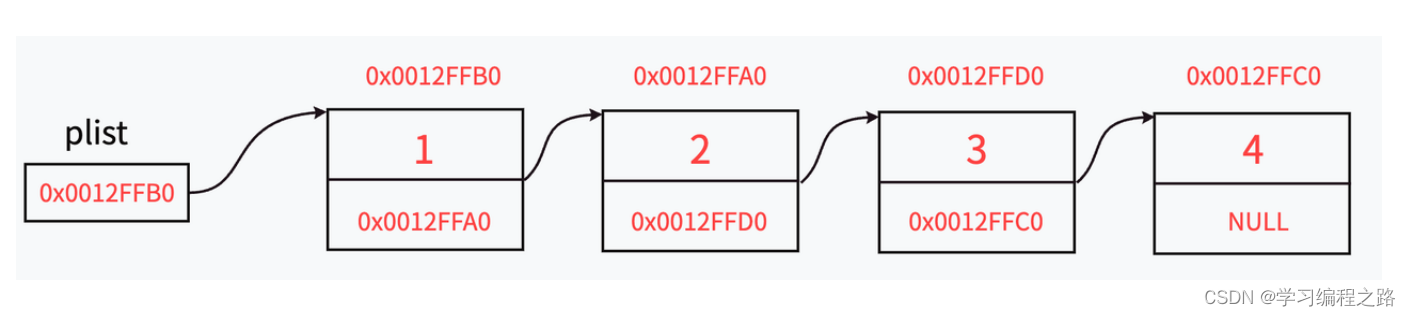
链表的结构
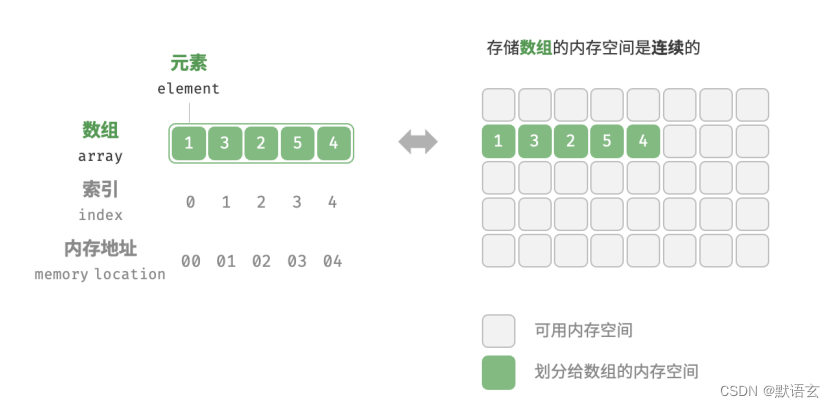
相比于顺序表的内存连续的结构,链表的内存是零散的,无形的链将各个内存串联起来就形成了链表。

而内存与内存之间相连的东西就是指针。让上一个节点存储下一个节点的地址。
最后一个节点的指针怎么办呢?
让它指向空就行了,这也是链表结尾的标志。
那么一个节点就要包括数据和下一个节点的指针两样东西,可以用结构体来打包成整体。

因为链表的这种结构让链表的插入和删除变得十分简单快速,只要改变节点指针指向就行了。
链表的类别
带有哨兵节点
带哨兵节点的链表,方便我们进行头插一系列处理,告别试用二级指针。
循环链表
循环链表的末尾不再指向空,而是指向头节点或者哨兵节点。循环链表一般配有哨兵节点,将哨兵节点作为循环结束的标志。
双向链表
双向链表是增加了一个指针指向我们的上一个节点,方便我们插入删除链表,另外尾删尾出也提升了时间复杂度。
三中组合就有六中结构,其中有几种是经常用到的。
最常见的三中链表结构
第一种就是不带头单向不循环链,这种会和后面的哈西表结合起来。力扣刷题里面经常遇到我们的这种链表,因为代码实现细节较多。
第二种是带头单向不循环链,这种链表可以免去很多判断的代码,让我们的代码变得简单,思路变得更清晰。
第三种是带头双向循环链表,这种链表各种操作的效率都普遍较高,追求效率就找它。
不带头单向不循环链表
主要掌握的函数(要能自行写出)

链表的遍历
整个链表如何找到呢?我们只要用一个节点指针指向链表的第一个节点就行了,通过指针指向下一个节点最后到最后一个就能遍历所有的节点,直到NULL结束。

链表节点的创建
我们已经知道一个节点的结构,我们直接用malloc函数来创建。

节点的查找
我们只要通过遍历一一对比值就行了。

链表的插入
链表的插入是插入到两个链表中间的,如果直让前面的节点指向插入的节点,那么后面的节点就找不到了,所以一般要创建一个节点指针来辅助我们插入。或者我们直接用双指针来实现链表的插入
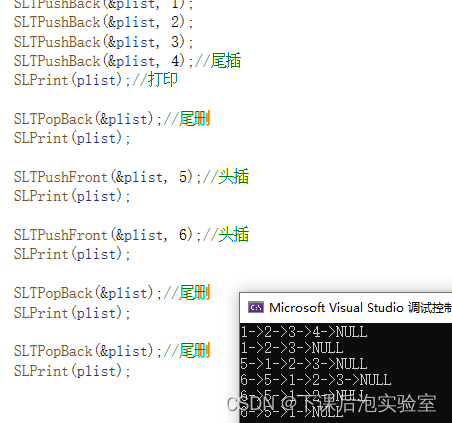
尾插
我们首先要创建一个指针来指向这个链表,但是开始链表是没有节点的,所以只能指向空。但是后面有链表了我们的指针又不能够指向空,所以我们只能用二级指针来解决(当然可以用返回值来解决,但是显得有点复杂,每次都要接收一下返回值)。

头插
头插需要值得注意的是要改变我们的指针。

在指定位置之后插入数据
这里需要用到双指针来实现操作

在指定位置之前插入数据
同理使用双指针

删除节点
这里不需要双指针,但是要节点指针储存一个节点地址
删除所指节点

删除所指节点后的节点

尾删

头删

销毁链表

带头单向不循环链表
我主要写和不带头差异很大的函数。
一般哨兵链表是没有数据的,我们也不能给它赋值特殊的数据,因为数据种类可能会改变,我们赋值不会相应改变,导致报错.
哨兵节点的创建

尾插
我们发现尾插可以不用考虑第一个插入是不是空链表的情况了

尾删
同理,我们也不需要考虑只有一个节点的情况是否特殊

带头循环双向链表
这种链表的结构如下


这种结构稍微复杂,所以请读者自行画图多理解一下。
哨兵节点的创建

创建完后就是一下结构:两个指针都指向自己

定点节点后插入
首先我们可以写一个寻找目标节点的代码,返回目标节点的指针

然后函数就是:

定点节点前插入
定点节点前插入和后插入是相同的道理,因为是循环双向的,所以就是代码反过来写。没有什么区别

前插尾插
因为header的prev节点和header之间插入就是尾插,所以我们的尾插时间复杂度之间就降到了O(1)。
前插还是一样的道理,把第一个数据的值传给dlink_insertfront就是前插了
两个函数我不写,请读者自行完成。
删除节点
删除节点也有优点:我们设这个要删的节点之前的节点为A,之后的为B,删除节点为cur
针对于定点删除:对于之前的单链表,我们如果要删除,就要用双指针,记录A,和cur的地址,这样才能让A链接B,并释放cur。但是我们如果是双向指针,我们只要cur的节点就行了,现让cur->prev指向cur->next,然后就能直接释放cur的内存了。
针对于定点节点后的节点删除:这个更简单,对于单链表我们要创建一个指针来指向A节点,然后A指向B再free,但是现在我们只要让A指向B,通过prev指针就能回溯到cur指针。
总之,我们插入和删除节点是要断开节点之间的指针的,但是我们双向链表断开时还有一条链子是没有断开的,这要就可以继续操作,十分方便
对于删除节点我也不再写它的函数,和插入节点是有异曲同工之妙的。
链表的用处
对于单向链表主要在刷题网站上面遇见,所以是必须要熟悉的。另外,这种链表是可以挂在哈西表上面的,属于高级数据结构,本作者还没有学习。
而我们带头的单向链表的好处也显示出来了,我们可以在刷题的时候,将没有带头的单向链表添加一个头链表,这样就可以省去很多操作,最后只要用一个指针存储头节点之后的指针,然后free掉头节点就行了,然后返回这个指针。
对于双向链表,如果只用它的结构,我们就用双向链表,方便。但是后面有更好的数据结构,所以双向链表用得并不多
链表的缺点
我们虽然用双向链表解决了头删尾删时间复杂度为O(N)的问题,将它降为O(1),但是它的查找效果是不行的,查找的速度是O(N),而且它不能很好的实现排序功能。
另外如果我们要更深层次的来考虑这个问题,我们要涉及到CPU的缓存命中率:
对于我们的顺序表,它的缓存命中率是很高的,但是我们的链表,它的缓存命中率几乎为零因为它的内存是不连续的,基本命中不了。这就导致我们链表要更频繁的读取内存里面的数据,在这个上面速度就比顺序表要慢。
这一点对我们写栈的函数有帮助,因为栈可以用链表,也可以用顺序表。我们优先考虑顺序表来写栈