文章目录

📑前言
深度学习是当今人工智能领域的核心技术,尤其在图像处理、语音识别、自然语言处理等领域表现出色。要理解深度学习,首先需要掌握神经网络的训练过程,包括前向传播、反向传播、损失函数、优化算法以及梯度下降法及其变种。
一、前向传播与反向传播
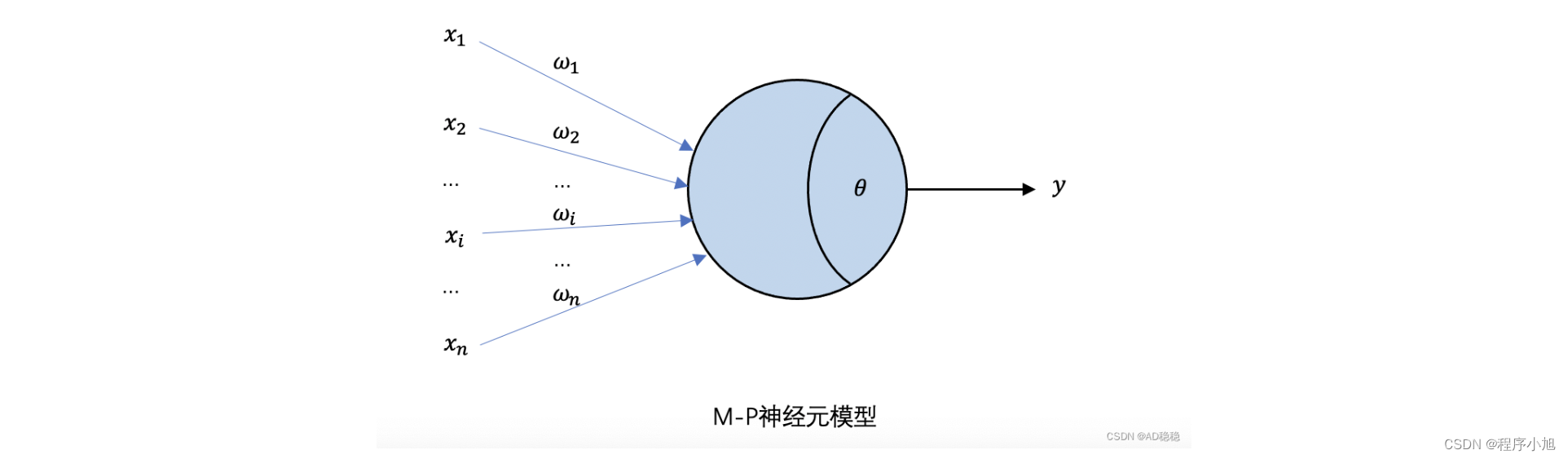
1.1 前向传播(Forward Propagation)
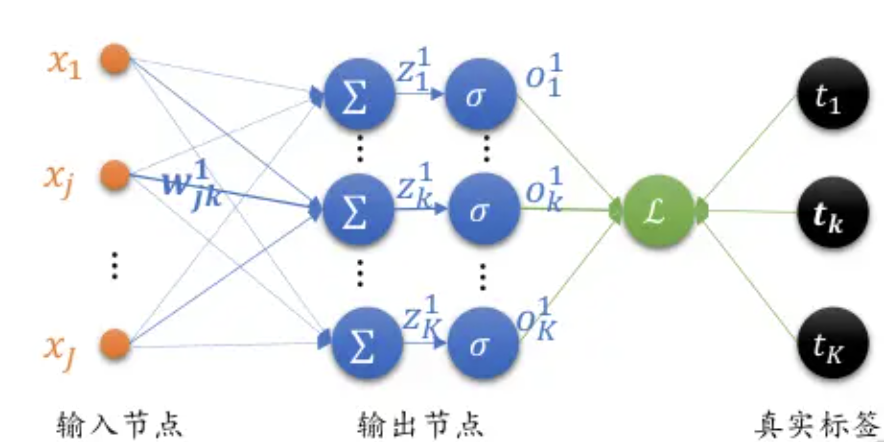
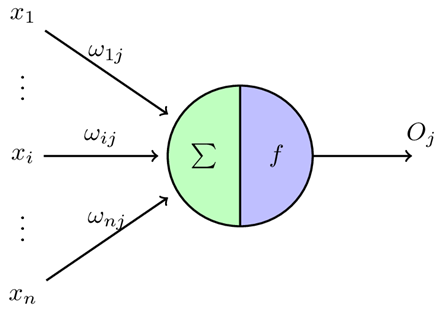
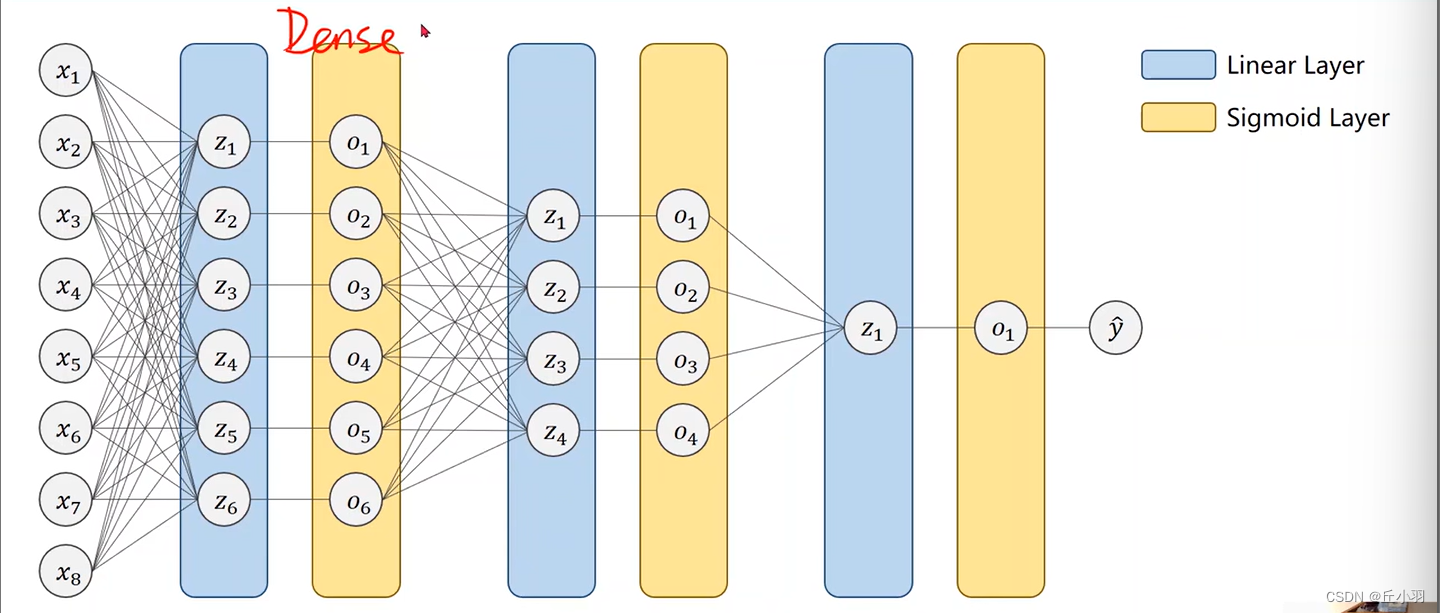
前向传播是神经网络的计算过程,通过输入层传递到输出层。每个神经元接收输入信号,进行加权求和,并通过激活函数得到输出。这个过程层层递进,最终在输出层得到预测结果。以下是一个简单的前向传播过程的步骤:
- 输入层: 输入数据 x 传入网络。
- 隐藏层: 每个隐藏层节点
 接收上一层节点的输出,并进行加权求和:
接收上一层节点的输出,并进行加权求和: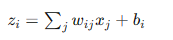 其中
其中 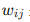 是权重,
是权重,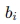 是偏置。
是偏置。 - 激活函数: 通过激活函数
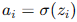 ,将线性组合结果非线性化。
,将线性组合结果非线性化。 - 输出层: 类似隐藏层的计算方式,最终输出预测结果。
通过前向传播,神经网络可以将输入映射到输出,这一过程是通过层层传递的方式实现的。
1.2 反向传播(Backpropagation)
反向传播是神经网络训练的核心算法,用于调整网络的权重和偏置,以最小化预测结果与真实值之间的误差。其基本步骤如下:
- 计算损失: 使用损失函数计算预测输出
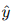 与真实标签
与真实标签 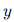 之间的误差
之间的误差 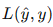 。
。 - 反向传递误差: 从输出层开始,逐层向后计算每个神经元的误差,并传递到前一层。
- 计算梯度: 对每个权重和偏置,计算损失函数关于它们的梯度

- 更新权重和偏置: 使用梯度下降法或其变种,更新网络的权重和偏置,使得损失函数值逐步减小。
反向传播的核心在于链式法则,通过逐层计算和传播梯度,最终调整所有参数,使网络的预测能力不断提高。
二、损失函数和优化算法
2.1 损失函数(Loss Function)
损失函数是衡量神经网络预测值与真实值之间差距的指标。常见的损失函数有:
- 均方误差(MSE): 主要用于回归问题,计算预测值与真实值之间的平方误差平均值。
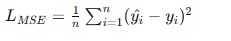
- 交叉熵损失(Cross-Entropy Loss): 主要用于分类问题,衡量预测概率分布与真实分布之间的差异。
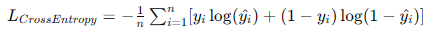
2.2 优化算法(Optimization Algorithms)
优化算法用于调整神经网络的权重和偏置,以最小化损失函数值。常见的优化算法包括:
- 梯度下降法(Gradient Descent): 通过计算损失函数的梯度,并沿着梯度的反方向更新参数,逐步减小损失函数值。
- 随机梯度下降(SGD): 每次仅使用一个或小批量样本来计算梯度并更新参数,适用于大规模数据集。
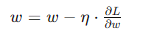
- 动量法(Momentum): 在更新参数时加入前一次更新的动量,帮助加速收敛并减少震荡。
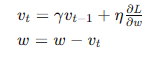
- AdaGrad: 根据梯度历史动态调整学习率,对稀疏数据表现良好。
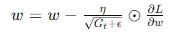
- RMSprop: 结合了动量和AdaGrad的优点,通过指数加权平均平滑梯度平方和。
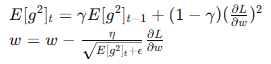
- Adam: 结合动量和RMSprop,适用于各种类型的神经网络和数据集。
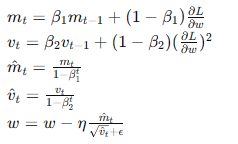
三、梯度下降法及其变种
3.1 梯度下降法(Gradient Descent)
梯度下降法是神经网络训练中最基本的优化算法,通过计算损失函数相对于参数的梯度,并沿梯度的反方向更新参数。基本的梯度下降法步骤如下:
- 初始化参数: 随机初始化网络的权重和偏置。
- 计算梯度: 使用反向传播算法,计算损失函数关于每个参数的梯度。
- 更新参数: 根据梯度和学习率,更新网络的权重和偏置。
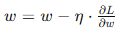
其中,η 为学习率,控制每次更新的步长。
3.2 梯度下降法的变种
为了提高训练效率和效果,梯度下降法有多种变种,每种变种都有其独特的特点和应用场景:
- 批量梯度下降(Batch Gradient Descent):
- 使用整个训练集来计算梯度和更新参数。
- 优点:每次更新都使用了全部数据,梯度计算准确。
- 缺点:计算开销大,内存占用高,不适用于大规模数据集。
- 随机梯度下降(Stochastic Gradient Descent, SGD):
- 每次仅使用一个样本来计算梯度并更新参数。
- 优点:计算速度快,适用于大规模数据集。
- 缺点:梯度更新波动较大,可能导致收敛速度慢。
- 小批量梯度下降(Mini-Batch Gradient Descent):
- 使用一个小批量样本来计算梯度并更新参数。
- 优点:折中批量梯度下降和随机梯度下降的优点,计算效率高,收敛较快。
- 缺点:需要选择合适的批量大小(通常在32到256之间)。
- 动量法(Momentum):
- 在梯度更新中引入动量,帮助加速收敛并减少震荡。
- 公式:
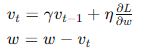
- 优点:在凹谷形状的损失面中加速收敛,减少震荡。
- AdaGrad:
- 根据梯度历史动态调整学习率,对稀疏数据表现良好。
- 公式:
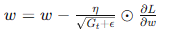
- 优点:在学习率调整上表现出色,适用于稀疏数据集。
- 缺点:学习率可能会过早地变得过小。
- RMSprop:
- 结合了动量和AdaGrad的优点,通过指数加权平均平滑梯度平方和。
- 公式:
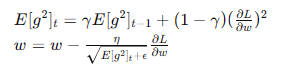
- 优点:在深度学习中表现稳定,适应性好。
- Adam(Adaptive Moment Estimation):
- 结合动量和RMSprop,适用于各种类型的神经网络和数据集。
- 公式:
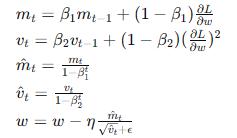
- 优点:广泛适用,具有良好的收敛性和稳定性。
四、小结
神经网络的训练过程是深度学习的核心,前向传播和反向传播是其基本步骤,而损失函数和优化算法则决定了模型的性能。梯度下降法及其变种提供了多种优化选择,使得神经网络能够高效地学习和改进。


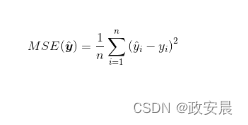
































![[ACM独立出版]2024年虚拟现实、图像和信号处理国际学术会议(ICVISP 2024)](https://i-blog.csdnimg.cn/direct/ced935e865c444328f0a47d4657dc958.jpeg)