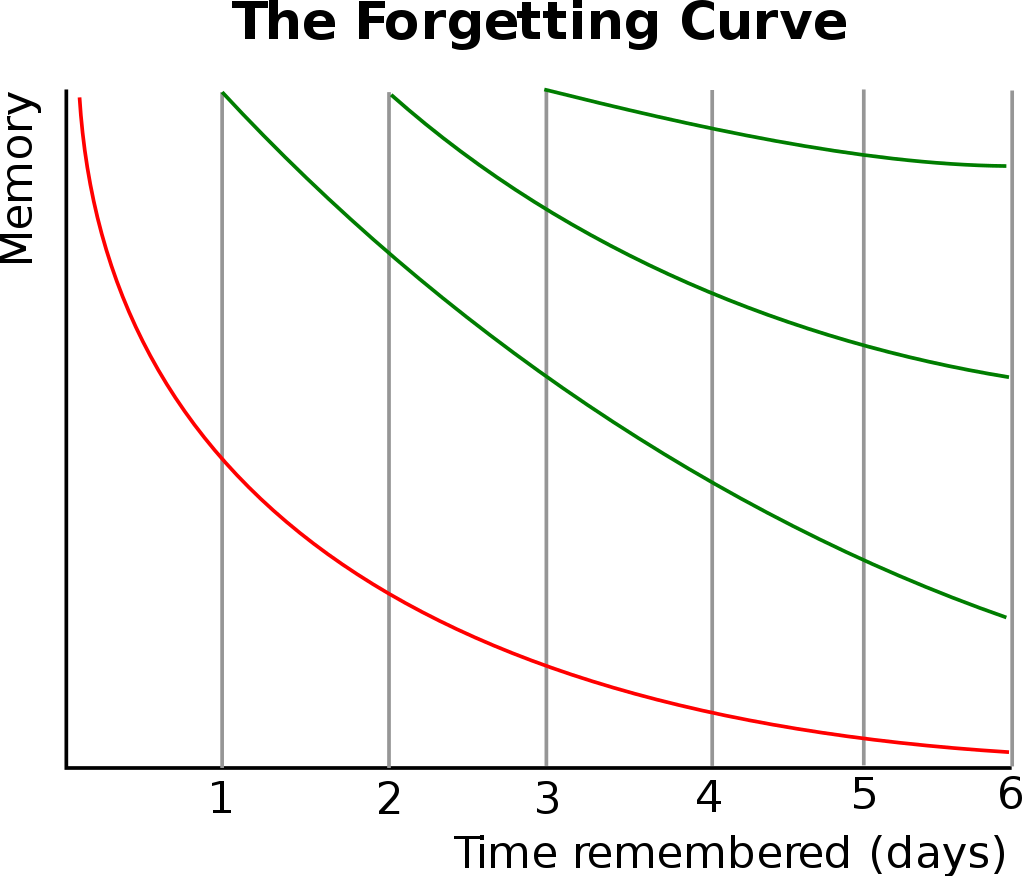
深度学习和NLP中的注意力和记忆

一、说明
深度学习的最新趋势是注意力机制。在一次采访中,现任 OpenAI 研究总监的 Ilya Sutskever 提到,注意力机制是最令人兴奋的进步之一,而且它们将继续存在。这听起来很令人兴奋。但什么是注意力机制?
神经网络中的注意力机制(非常)松散地基于人类中的视觉注意力机制。人类的视觉注意力得到了很好的研究,虽然存在不同的模型,但它们本质上都归结为能够以“高分辨率”聚焦在图像的某个区域,同时以“低分辨率”感知周围的图像,然后随着时间的推移调整焦点。
神经网络中的注意力有着悠久的历史,特别是在图像识别方面。示例包括学习将中央凹瞥见与三阶玻尔兹曼机相结合,或使用用于图像跟踪的深度架构学习参加地点。但直到最近,注意力机制才进入通常用于NLP的递归神经网络架构(并且越来越多地用于视觉)。这就是我们将在这篇文章中重点介绍的内容。
二、注意力解决了什么问题?#
为了理解注意力可以为我们做什么,让我们以神经机器翻译(NMT)为例。传统的机器翻译系统通常依赖于基于文本统计属性的复杂特征工程。简而言之,这些系统很复杂,构建它们需要大量的工程工作。神经机器翻译系统的工作方式略有不同。在 NMT 中,我们将句子的含义映射到固定长度的向量表示中,然后基于该向量生成翻译。通过不依赖 n-gram 计数之类的东西,而是尝试捕捉文本的更高层次的含义,NMT 系统比许多其他方法更好地泛化到新句子。也许更重要的是,NTM 系统更容易构建和训练,并且不需要任何手动特征工程。事实上,Tensorflow 中的简单实现只不过是几百行代码。
大多数 NMT 系统的工作原理是使用递归神经网络将源句子(例如德语句子)编码为向量,然后根据该向量解码英语句子,也使用 RNN。

RNN for Machine Translation
在上图中,“Echt”、“Dicke”和“Kiste”单词被输入编码器,在特殊信号(未显示)之后,解码器开始生成翻译的句子。解码器不断生成单词,直到生成特殊的句子结尾标记。在这里,ℎ向量表示编码器的内部状态。
如果你仔细观察,你会发现解码器应该只根据最后的隐藏状态生成翻译 h 3 ℎ_3 h3 从编码器。这 h 3 ℎ_3 h3 vector 必须对我们需要了解的有关源句子的所有内容进行编码。它必须充分体现其意义。用更专业的术语来说,该向量是一个句子嵌入。事实上,如果你使用PCA或t-SNE在低维空间中绘制不同句子的嵌入进行降维,你可以看到语义上相似的短语最终彼此接近。这真是太神奇了。
尽管如此,假设我们可以将有关一个可能很长的句子的所有信息编码到一个向量中,然后让解码器仅基于此产生良好的翻译,这似乎有些不合理。假设您的源句子有 50 个单词长。英文翻译的第一个单词可能与源句子的第一个单词高度相关。但这意味着解码器必须考虑 50 步前的信息,并且该信息需要以某种方式编码到向量中。众所周知,递归神经网络在处理这种长程依赖关系方面存在问题。从理论上讲,像 LSTM 这样的架构应该能够处理这个问题,但在实践中,远程依赖关系仍然存在问题。例如,研究人员发现,反转源序列(将其向后馈送到编码器)会产生更好的结果,因为它缩短了从解码器到编码器相关部分的路径。同样,两次输入序列似乎也有助于网络更好地记忆事物。
我认为颠倒句子的方法是一种“黑客”。它使事情在实践中更好地工作,但这不是一个有原则的解决方案。大多数翻译基准都是在法语和德语等语言上完成的,这些语言与英语非常相似(甚至中文的词序也与英语非常相似)。但是在某些语言(如日语)中,句子的最后一个单词可以高度预测英语翻译中的第一个单词。在这种情况下,反转输入会使情况变得更糟。那么,还有什么替代方案呢?注意力机制。
使用注意力机制,我们不再尝试将完整的源句子编码为固定长度的向量。相反,我们允许解码器在输出生成的每个步骤中“关注”源句子的不同部分。重要的是,我们让模型根据输入的句子以及到目前为止产生的内容来学习要注意什么。因此,在非常一致的语言(如英语和德语)中,解码器可能会选择按顺序处理事情。在生成第一个英语单词时注意第一个单词,依此类推。这就是在神经机器翻译中通过联合学习对齐和翻译所做的,如下所示:

NMT Attention
在这里,y的是我们翻译的单词,由解码器生成,而x是我们的源句词。上图使用双向循环网络,但这并不重要,您可以忽略相反的方向。重要的部分是每个解码器输出字 y t y_t yt 现在取决于所有输入状态的加权组合,而不仅仅是最后一个状态。这里的"a"表示的权重定义了每个输出应考虑多少每个输入状态。所以,如果 a 3 , 2 a_{3,2} a3,2 是一个很大的数字,这意味着解码器在生成目标句子的第三个单词时会非常注意源句子中的第二个状态。这里的a通常归一化为总和 1(因此它们是输入状态的分布)。
注意力的一大优势是,它使我们能够解释和可视化模型正在做什么。例如,通过可视化注意力权重矩阵a,当一个句子被翻译时,我们可以理解模型是如何翻译的:

NMT Attention Matrix
在这里,我们看到,在从法语翻译成英语时,网络会按顺序处理每个输入状态,但有时它会在生成输出时同时处理两个单词,例如将“la Syrie”翻译成“Syria”。
三、关注的代价#
如果我们再仔细观察一下注意力的方程式,我们就会发现注意力是有代价的。我们需要为输入和输出单词的每个组合计算一个注意力值。如果您有一个 50 个单词的输入序列并生成一个 50 个单词的输出序列,则该序列将是 2500 个注意力值。这还不错,但是如果你进行字符级计算并处理由数百个标记组成的序列,上述注意力机制可能会变得非常昂贵。
实际上,这是相当违反直觉的。人类的注意力应该可以节省计算资源。通过专注于一件事,我们可以忽略许多其他事情。但这并不是我们在上面的模型中真正要做的。在决定关注什么之前,我们基本上是在详细研究所有内容。直观地说,这相当于输出一个翻译的单词,然后回溯你对文本的所有内部记忆,以决定接下来要生成哪个单词。这似乎是一种浪费,根本不是人类正在做的事情。事实上,它更像是内存访问,而不是注意力,在我看来,这有点用词不当(更多内容见下文)。尽管如此,这并没有阻止注意力机制变得非常流行,并在许多任务中表现出色。
另一种注意力方法是使用强化学习来预测要关注的大致位置。这听起来更像是人类的注意力,这就是视觉注意力的循环模型中所做的。
四、机器翻译之外的关注#
到目前为止,我们已经研究了对机器翻译的关注。但是,上述相同的注意力机制可以应用于任何循环模型。因此,让我们再看几个例子。
在“展示、参与和讲述”中,作者将注意力机制应用于生成图像描述的问题。他们使用卷积神经网络来“编码”图像,并使用具有注意力机制的递归神经网络来生成描述。通过可视化注意力权重(就像在翻译示例中一样),我们解释模型在生成单词时正在查看的内容:

Show, Attend and Tell Attention Visualization
在《语法作为外语》一书中,作者使用带有注意力机制的递归神经网络来生成句子解析树。可视化的注意力矩阵可以深入了解网络如何生成这些树:

Screen Shot 2015-12-30 at 1.49.19 PM
在《教机器阅读和理解》一书中,作者使用RNN来阅读文本,阅读(合成生成的)问题,然后得出答案。通过可视化注意力矩阵,我们可以看到网络在试图找到问题的答案时“看”在哪里:

Teaching Machines to Read And Comprehend Attention
五、注意力=(模糊)记忆?#
注意力机制解决的基本问题是,它允许网络回溯输入序列,而不是强迫它将所有信息编码为一个固定长度的向量。正如我上面提到的,我认为这种关注有点用词不当。换一种解释,注意力机制只是让网络访问其内部存储器,这是编码器的隐藏状态。在这种解释中,网络不是选择“参加”什么,而是选择从内存中检索什么。与典型的内存不同,这里的内存访问机制是软的,这意味着网络检索所有内存位置的加权组合,而不是从单个离散位置检索值。使内存访问软化的好处是,我们可以使用反向传播轻松地端到端地训练网络(尽管有一些非模糊方法使用采样方法而不是反向传播来计算梯度)。
记忆机制本身的历史要长得多。标准递归神经网络的隐藏状态本身就是一种内部存储器。RNN遭受梯度消失问题的困扰,这使它们无法学习长程依赖关系。LSTM 通过使用允许显式内存删除和更新的门控机制对此进行了改进。
现在,更复杂的内存结构的趋势仍在继续。端到端内存网络允许网络在进行输出之前多次读取相同的输入序列,并在每个步骤中更新内存内容。例如,通过对输入故事进行多个推理步骤来回答问题。然而,当网络参数权重以某种方式绑定时,端到端记忆网络中的内存机制与这里介绍的注意力机制相同,只是它在内存上进行了多次跳跃(因为它试图整合来自多个句子的信息)。
神经图灵机使用类似形式的内存机制,但具有更复杂的寻址类型,即使用基于内容的寻址(如此处)和基于位置的寻址,允许网络学习寻址模式以执行简单的计算机程序,如排序算法。
在未来,我们很可能会看到记忆和注意力机制之间更清晰的区别,也许会沿着强化学习神经图灵机的路线,它试图学习访问模式来处理外部接口。































![[AI 大模型] 阿里巴巴 通义千问](https://i-blog.csdnimg.cn/direct/a96da5e3326f45f49a4df9e0bac90501.png#pic_center)