

Spark SQL
一、Spark SQL架构
能够直接访问现存的Hive数据
提供JDBC/ODBC接口供第三方工具借助Spark进行数据处理
提供更高层级的接口方便处理数据
支持多种操作方式:SQL、API编程
- API编程:Spark SQL基于SQL开发了一套SQL语句的算子,名称和标准的SQL语句相似
支持Parquet、CSV、JSON、RDBMS、Hive、HBase等多种外部数据源。(掌握多种数据读取方式)

Spark SQL核心:是RDD+Schema(算子+表结构),为了更方便我们操作,会将RDD+Schema发给DataFrame
数据回灌:用于将处理和清洗后的数据回写到Hive中,以供后续分析和使用。
BI Tools:主要用于数据呈现。
Spark Application:开发人员使用Spark Application编写数据处理和分析逻辑,这些应用可以用不同的编程语言编写,比如Python、Scala、Java等。
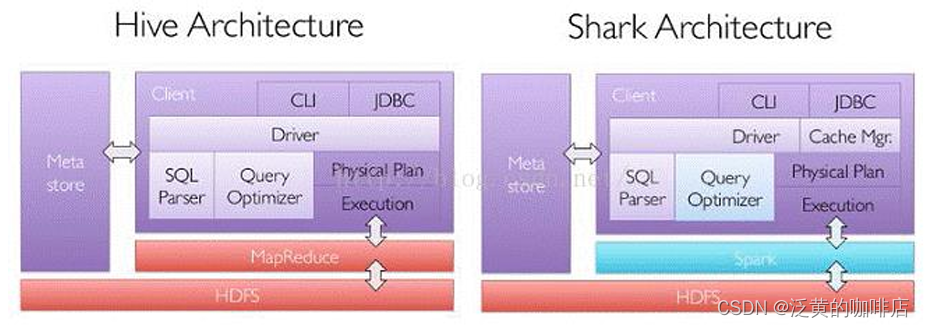
二、Spark SQL运行原理

- Catalyst优化器的运行流程:
- Frontend(前端)
- 输入:用户可以通过SQL查询或DataFrame API来输入数据处理逻辑。
- Unresolved Logical Plan(未解析的逻辑计划):输入的SQL查询或DataFrame转换操作会首先被转换为一个未解析的逻辑计划,这个计划包含了用户请求的所有操作,但其中的表名和列名等可能尚未解析。
- Catalyst Optimizer(Catalyst优化器) Catalyst优化器是Spark SQL的核心组件,它负责将逻辑计划转换为物理执行计划,并进行优化。Catalyst优化器包括以下几个阶段:
- Analysis(分析):将未解析的逻辑计划中的表名和列名解析为具体的元数据,这一步依赖于Catalog(元数据存储)。输出是一个解析后的逻辑计划。
- Logical Optimization(逻辑优化):对解析后的逻辑计划进行各种优化,如投影剪切、过滤下推等。优化后的逻辑计划更加高效。
- Physical Planning(物理计划):将优化后的逻辑计划转换为一个或多个物理执行计划。每个物理计划都代表了一种可能的执行方式。
- Cost Model(成本模型):评估不同物理计划的执行成本,选择代价最低的物理计划作为最终的物理计划。
- Backend(后端)
- Code Generation(代码生成):将选择的物理计划转换为可以在Spark上执行的RDD操作。这一步会生成实际的执行代码。
- RDDs:最终生成的RDD操作被执行,以完成用户请求的数据处理任务。
- 一个SQL查询在Spark SQL中的优化流程
SELECT name FROM(
SELECT id, name FROM people
) p
WHERE p.id = 1

- Filter下压:将Filter操作推到更靠近数据源的位置,以减少不必要的数据处理。
- 合并Projection:减少不必要的列选择
- IndexLookup return:name:如果存在索引,可以直接通过索引查找并返回
name列
三、Spark SQL API
SparkContext:Spark应用的主入口,代表了与Spark集群的连接。
SQLContext:Spark SQL的编程入口,使用SQLContext可以运行SQL查询、加载数据源和创建DataFrame。
HiveContext:SQLContext的一个子集,可以执行HiveQL查询,并且可以访问Hive元数据和UDF。
SparkSession:Spark2.0后推荐使用,合并了SQLContext和HiveContext,提供了与Spark所有功能交互的单一入口点。
创建一个SparkSession就包含了一个SparkContext。
若同时需要创建SparkContext和SparkSession,必须先创建SparkContext再创建SparkSession。否则,会抛出如下异常,提示重复创建SparkContext:
详细解释
创建SparkSession的代码
val conf: SparkConf = new SparkConf()
.setMaster("local[4]")
.setAppName("SparkSql")
def main(args: Array[String]): Unit = {
SparkSession.builder()
.config(conf)
.getOrCreate()
}
优化:减少创建代码,SparkSessionBuilder工具类
package com.ybg
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.SparkSession
// 封装SparkSession的创建方法
class SparkSessionBuilder(master:String,appName:String){
lazy val config:SparkConf = {
new SparkConf()
.setMaster(master)
.setAppName(appName)
}
lazy val spark:SparkSession = {
SparkSession.builder()
.config(config)
.getOrCreate()
}
lazy val sc:SparkContext = {
spark.sparkContext
}
def stop(): Unit = {
if (null != spark) {
spark.stop()
}
}
}
object SparkSessionBuilder {
def apply(master: String, appName: String): SparkSessionBuilder = new SparkSessionBuilder(master, appName)
}
四、Spark SQL依赖
pom.xml
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spark.version>3.1.2</spark.version>
<spark.scala.version>2.12</spark.scala.version>
<hadoop.version>3.1.3</hadoop.version>
<mysql.version>8.0.33</mysql.version>
<hive.version>3.1.2</hive.version>
<hbase.version>2.3.5</hbase.version>
<jackson.version>2.10.0</jackson.version>
</properties>
<dependencies>
<!-- spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${spark.scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${spark.scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
若出现如下异常:
Caused by: com.fasterxml.jackson.databind.JsonMappingException:
Scala module 2.10.0 requires Jackson Databind version >= 2.10.0 and < 2.11.0
追加如下依赖:
-->
<!-- jackson-databind -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.10.0</version>
</dependency>
<!-- mysql -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<version>${mysql.version}</version>
</dependency>
</dependencies>
log4j.properties
log4j.properties应该放在资源包下。
log4j.rootLogger=ERROR, stdout, logfile # 设置可显示的信息等级
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=log/spark_first.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
五、Spark SQL数据集
1、DataSet
- 简介:
- 从Spark 1.6开始引入的新的抽象。
- 是特定领域对象中的强类型集合。
- 可以使用函数式编程或SQL查询进行操作。
- 等于RDD + Schema。
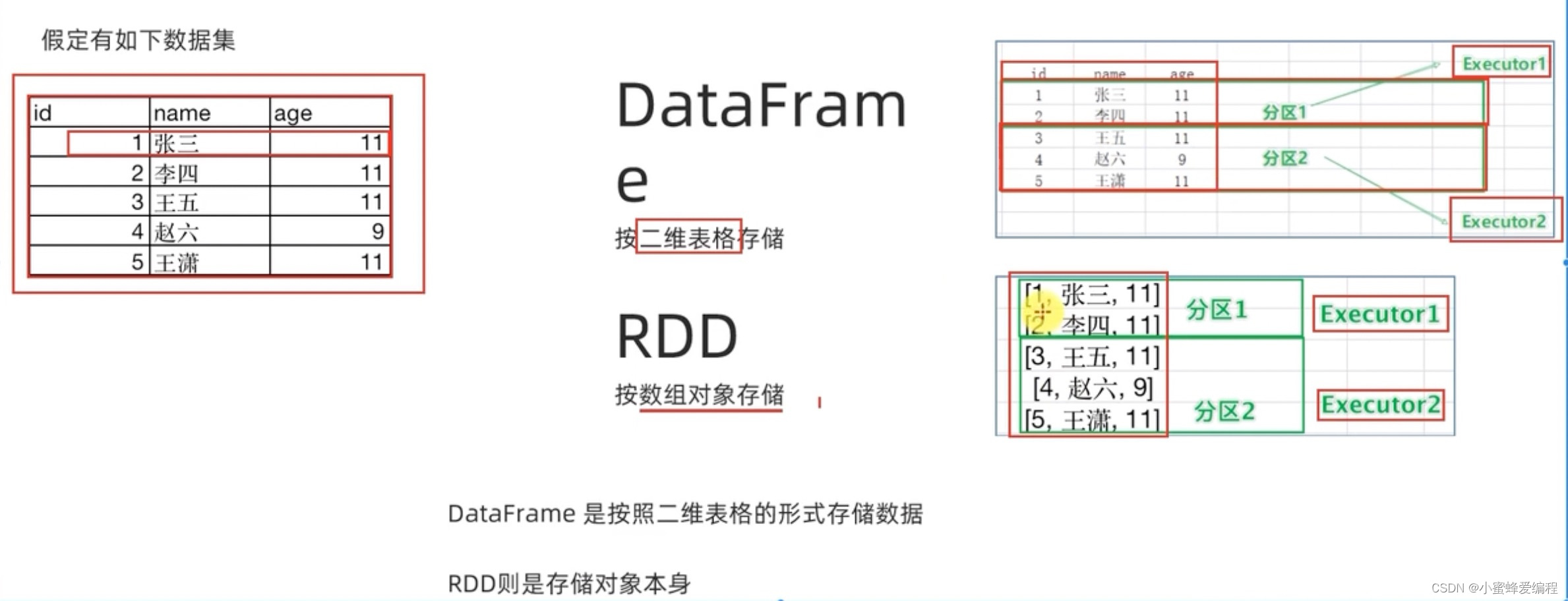
2、DataFrame
- 简介:
- DataFrame是特殊的DataSet:
DataFrame=DataSet[Row],行对象的集合,每一行就是一个行对象。 - 类似于传统数据的二维表格。
- DataFrame是特殊的DataSet:
- 特性:
- Schema:在RDD基础上增加了Schema,描述数据结构信息
- 嵌套数据类型:支持
struct,map,array等嵌套数据类型。 - API:提供类似SQL的操作接口。
详细解释
创建DataSet的代码
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
// 提供了一组隐式转换,这些转换允许将Scala的本地集合类型(如Seq、Array、List等)转换为Spark的DataSet。
import spark.implicits._
val dsPhone: Dataset[Product] = spark.createDataset(Seq(
Product(1, "Huawei Mate60", 5888.0f),
Product(2, "IPhone", 5666.0f),
Product(3, "OPPO", 1888.0f)
))
dsPhone.printSchema()
/**
* root
* |-- id: integer (nullable = false)
* |-- name: string (nullable = true)
* |-- price: float (nullable = false)
*/
创建DataFrame的代码
读取CSV文件
对于CSV文件,在构建DataFrame之前,必须要先创建一个Schema,再根据文件类型分不同情况进行导入。(读取JSON文件或者数据库表都并不需要)
注意:必须要
import spark.implicits._,导入隐式类,才能够识别一些隐式转换,否则会报错。CSV文件在创建DataFrame时,可以选择尽量模仿Hive中的OpenCSVSerDe的
val spark: SparkSession = SparkSession.builder()
.config(conf)
.getOrCreate()
import spark.implicits._
val schema: StructType = StructType(
Seq(
StructField("user_id", LongType),
StructField("locale", StringType),
StructField("birthYear", IntegerType),
StructField("gender", StringType),
StructField("joinedAt", StringType),
StructField("location", StringType),
StructField("timezone", StringType)
)
)
val frmUsers: DataFrame = spark.read
.schema(schema)
.option("separator", ",") // 指定文件分割符
.option("header", "true") // 指定CSV文件包含表头
.option("quoteChar", "\"")
.option("escapeChar", "\\")
.csv("C:\\Users\\lenovo\\Desktop\\users.csv")
.repartition(4)
.cache()
- 读取JSON文件
val frmUsers2: DataFrame = spark.read.json("hdfs://single01:9000/spark/cha02/users.json")
frmUsers2.show()
- 读取数据库表
val url = "jdbc:mysql://single01:3306/test_db_for_bigdata" // 数据库连接地址
val mysql = new Properties()
mysql.setProperty("driver", "com.mysql.cj.jdbc.Driver")
mysql.setProperty("user", "root")
mysql.setProperty("password", "123456")
spark
.read
.jdbc(url,"test_table1_for_hbase_import",mysql) // (url,TableName,连接属性)
.show(100)
六、Spark_SQL的两种编码方式
val spark: SparkSession = SparkSession.builder()
.config(conf)
.getOrCreate()
import spark.implicits._
val schema: StructType = StructType(
Seq(
StructField("user_id", LongType),
StructField("locale", StringType),
StructField("birthYear", IntegerType),
StructField("gender", StringType),
StructField("joinedAt", StringType),
StructField("location", StringType),
StructField("timezone", StringType)
)
)
val frmUsers: DataFrame = spark.read
.schema(schema)
.option("separator", ",") // 指定文件分割符
.option("header", "true") // 指定CSV文件包含表头
.option("quoteChar", "\"")
.option("escapeChar", "\\")
.csv("C:\\Users\\lenovo\\Desktop\\users.csv")
.repartition(4)
.cache()
此处已经创建好了DataFrame
1. 面向标准SQL语句(偷懒用)
frmUsers.registerTempTable("user_info") // 此方法已过期
spark.sql(
"""
|select * from user_info
|where gender='female'
|""".stripMargin)
.show(10)
2. 使用Spark中的SQL算子(更规范)
frmUsers
.where($"birthYear">1990)
.groupBy($"locale")
.agg(
count($"locale").as("locale_count"),
round(avg($"birthYear"),2).as("avg_birth_year")
)
.where($"locale_count">=10 and $"avg_birth_year">=1993)
.orderBy($"locale_count".desc)
.select(
$"locale", $"locale_count", $"avg_birth_year",
dense_rank()
.over(win)
.as("rnk_by_locale_count"),
lag($"locale_count",1)
.over(win)
.as("last_locale_count")
)
.show(10)
七、常用算子
1.基本SQL模板
select
col,cols*,agg*
where
conditionCols
group by
col,cols*
having
condition
order by
col asc|desc
limit
n
2.select
select语句在代码的开头可以不写,因为有后续的类似where和group by语句已经对列进行了操作,指明了列名。如果后续有select语句,则优先按照后面的select语句进行。
frmUsers.select(
$"locale",$"locale_count"
)
3.agg
.agg(
count($"locale").as("locale_count"),
round(avg($"birthYear"),2).as("avg_birth_year")
)
4.窗口函数
- over子句
注意:over子句中的分区信息是可以被重用的
val win: WindowSpec = Window.partitionBy($"gender").orderBy($"locale_count".desc)
frmUsers
...
.select(
dense_rank()
.over(win)
.as("rnk_by_locale_count")
)
5.show
show(N)表示显示符合条件的至多N条数据。(不是取前N条再提取出其中符合条件的数据)
frmUsers
...
.show(10)
6.条件筛选 where
newCol:Column = $"cus_state".isNull
newCol:Column = $"cus_state".isNaN
newCol:Column = $"cus_state".isNotNull
newCol:Column = $"cus_state".gt(10) <=> $"cus_state">10
newCol:Column = $"cus_state".geq(10) <=> $"cus_state">=10
newCol:Column = $"cus_state".lt(10) <=> $"cus_state"<10
newCol:Column = $"cus_state".leq(10) <=> $"cus_state"<=10
newCol:Column = $"cus_state".eq(10) <=> $"cus_state"===10
newCol:Column = $"cus_state".ne(10) <=> $"cus_state"=!=10
newCol:Column = $"cus_state".between(10,20)
newCol:Column = $"cus_state".like("张%")
newCol:Column = $"cus_state".rlike("\\d+")
newCol:Column = $"cus_state".isin(list:Any*)
newCol:Column = $"cus_state".isInCollection(values:Itrable[_])
多条件:
newCol:Column = ColOne and ColTwo
newCol:Column = ColOne or ColTwo
在Spark SQL中,不存在Having子句,Where子句的实际作用根据相对于分组语句的前后决定。
7.分组
// 多重分组
/**
rollup的效果:
select birthYear,count(*) from user group by birthYear
union all
select gender,birthYear,count(*) from user group by gender,birthYear
存在"字段不对应"的情况:
空缺的字段会自动补全为null
*/
frmUsers
.rollup("gender", "birthYear")
.count()
.show(100)
// 为了方便查找到每个数据行所对应的分组方式
spark.sql(
"""
|select grouping__id,gender,birthYear,count(8) as cnt from user_info
|group by gender,birthday,
|grouping sets(gender,birthday,(gender,birthYear))
|""".stripMargin)
.show(100)
// 这里的group by子句定义了分组的列,到grouping sets明确指定了分组的组合
// 因而,在数仓设计的过程中,我们能够对不同分组依据下的不同数据依据grouping__id做分区。
RollUp和Cube的区别假设有三列:
1,2,3,使用CUBE(1, 2, 3),会生成以下组合:GROUP BY ()(不分组,整体聚合)GROUP BY (1)GROUP BY (2)GROUP BY (3)GROUP BY (1, 2)GROUP BY (1, 3)GROUP BY (2, 3)GROUP BY (1, 2, 3)
ROLLUP生成的分组组合是层级的,它从最详细的分组开始,一步步减少分组的列,直到整体聚合。假设有三列:
1,2,3,使用ROLLUP(1, 2, 3),会生成以下组合:GROUP BY (1, 2, 3)(最详细的分组)GROUP BY (1, 2)GROUP BY (1)GROUP BY ()(不分组,整体聚合)
8.关联查询
val frmClass: DataFrame = spark.createDataFrame(
Seq(
Class(1, "yb12211"),
Class(2, "yb12309"),
Class(3, "yb12401")
)
)
val frmStu: DataFrame = spark.createDataFrame(
Seq(
Student("henry", 1),
Student("ariel", 2),
Student("jack", 1),
Student("rose", 4),
Student("jerry", 2),
Student("mary", 1)
)
)
// 1.笛卡尔积(默认情况下)
frmStu.as("S")
.join(frmClass.as("C"))
.show(100)
/**
+-----+-------+-------+---------+
| name|classId|classId|className|
+-----+-------+-------+---------+
|henry| 1 | 1 | yb12211|
|henry| 1 | 2 | yb12309|
|henry| 1 | 3 | yb12401|
|ariel| 2 | 1 | yb12211|
|ariel| 2 | 2 | yb12309|
|ariel| 2 | 3 | yb12401|
| jack| 1 | 1 | yb12211|
| jack| 1 | 2 | yb12309|
| jack| 1 | 3 | yb12401|
| rose| 4 | 1 | yb12211|
| rose| 4 | 2 | yb12309|
| rose| 4 | 3 | yb12401|
|jerry| 2 | 1 | yb12211|
|jerry| 2 | 2 | yb12309|
|jerry| 2 | 3 | yb12401|
| mary| 1 | 1 | yb12211|
| mary| 1 | 2 | yb12309|
| mary| 1 | 3 | yb12401|
+-----+-------+-------+---------+
*/
// 2.内连接
frmStu.as("S")
.join(frmClass.as("C"), $"S.classId" === $"C.classId","inner")
.show(100)
/**
+-----+-------+-------+---------+
| name|classId|classId|className|
+-----+-------+-------+---------+
|henry| 1 | 1 | yb12211|
|ariel| 2 | 2 | yb12309|
| jack| 1 | 1 | yb12211|
|jerry| 2 | 2 | yb12309|
| mary| 1 | 1 | yb12211|
+-----+-------+-------+---------+
*/
// 启用using:使用Seq("Column")代表关联字段
frmStu.as("S")
.join(frmClass.as("C"), Seq("classId"),"right")
.show(100)
// 3.外连接
frmStu.as("S")
.join(frmClass.as("C"), $"S.classId" === $"C.classId","outer") // left | right | outer
.show(100)
/**
+-----+-------+-------+---------+
| name|classId|classId|className|
+-----+-------+-------+---------+
|henry| 1 | 1 | yb12211|
| jack| 1 | 1 | yb12211|
| mary| 1 | 1 | yb12211|
| null| null | 3 | yb12401|
| rose| 4 | null | null|
|ariel| 2 | 2 | yb12309|
|jerry| 2 | 2 | yb12309|
+-----+-------+-------+---------+
*/
// 4.反连接:返回左数据集中所有没有关联字段匹配记录的左数据集的行
frmStu.as("S")
.join(frmClass.as("C"), $"S.classId" === $"C.classId","anti")
.show(100)
/**
+----+-------+
|name|classId|
+----+-------+
|rose| 4 |
+----+-------+
*/
// 5.半连接:返回左数据集中所有有关联字段匹配记录的左数据集的行
frmStu.as("S")
.join(frmClass.as("C"), $"S.classId" === $"C.classId","semi")
.show(100)
/**
+-----+-------+
| name|classId|
+-----+-------+
|henry| 1 |
|ariel| 2 |
| jack| 1 |
|jerry| 2 |
| mary| 1 |
+-----+-------+
*/
9.排序
frmStu.orderBy(cols:Column*)
10.数据截取
frmStu.tail(n:Int)
frmStu.take(n:Int)





























![代码随想录算法训练营第71天:路径算法[1]](https://img-blog.csdnimg.cn/img_convert/c06472a67f2b8ce7b7ccbd111103ac63.png)






