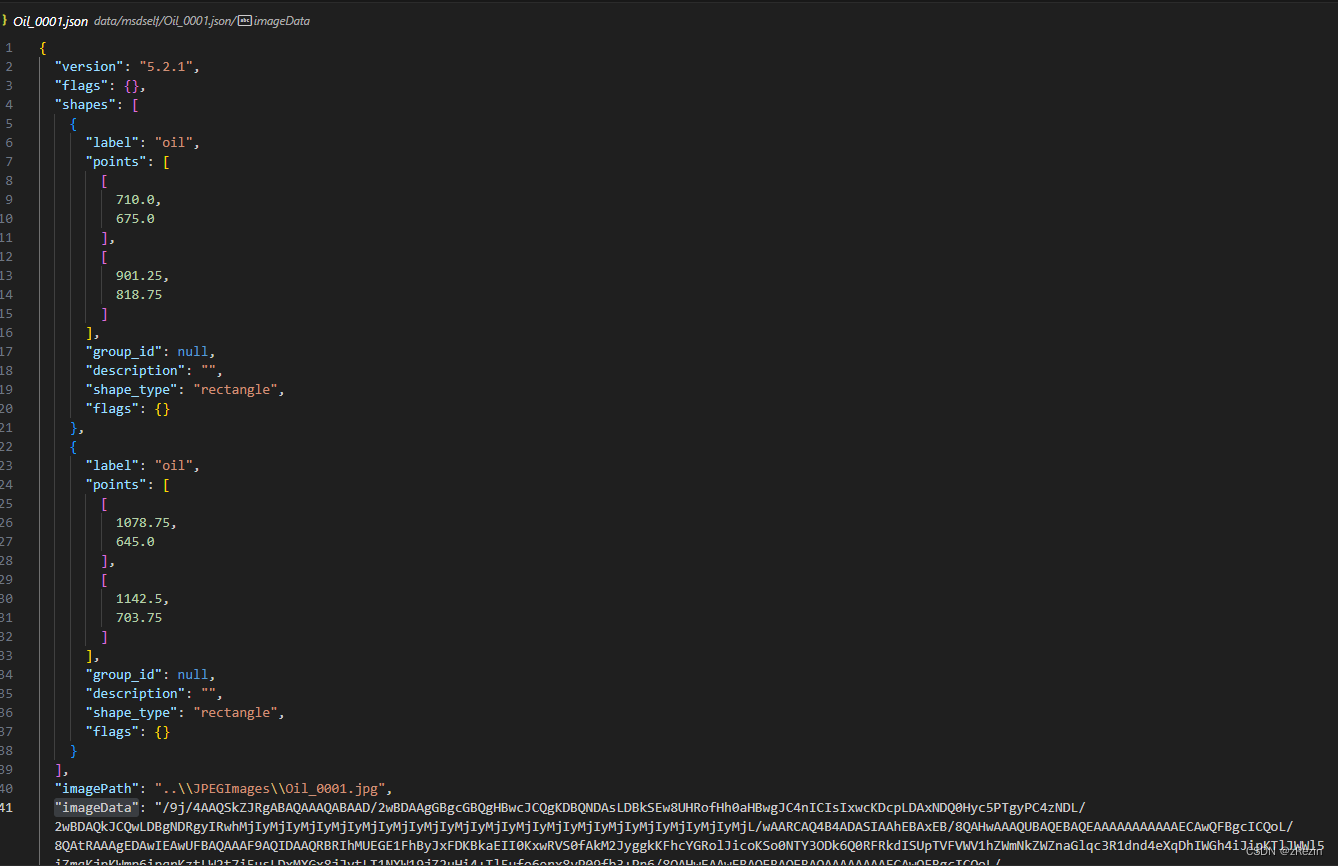
1、首先需要知道yoloV8目标检测的标签格式:
yolov8标签数据格式说明
After using a tool like Roboflow Annotate to label your images, export your labels to YOLO format, with one *.txt file per image (if no objects in image, no *.txt file is required). The *.txt file specifications are:
One row per object
Each row is class x_center y_center width height format.
Box coordinates must be in normalized xywh format (from 0 - 1). If your boxes are in pixels, divide x_center and width by image width, and y_center and height by image height.
Class numbers are zero-indexed (start from 0).
主要包括五个数字 id 、x 、y 、w,、h,分别代表标签类别、目标对象在图像中的中心位置(x,y)、目标对象的宽和高。
注意的是中心位置坐标、以及目标对象的宽和高都需要进行归一化到0-1之间。如下:
0 0.060000 0.460000 0.12 0.65
1 0.450000 0.480000 0.38 0.68
0 0.880000 0.470000 0.24 0.63
2、示例有两种标签类型,转化为.txt的代码如下:
import json
import os
import shutil
import random
# Convert label to idx
with open("labels.txt", "r") as f:
classes = [c.strip() for c in f.readlines()]
idx_dict = {c: str(i) for i, c in enumerate(classes)}
def convert_labelmes_to_yolo(labelme_folder, output_folder):
label_folder = os.path.join(output_folder, "labels") # label_folder = image_folder/labels
os.makedirs(label_folder, exist_ok=True)
image_folder = os.path.join(output_folder, "images") # image_folder = image_folder/images
os.makedirs(image_folder, exist_ok=True)
for root, dirs, files in os.walk(labelme_folder): # root-文件夹所在路径 dir-路经下的文件夹 file-里面的文件
for file in files:
file_path = os.path.join(root, file)
if os.path.splitext(file)[-1] != ".json": # 分割文件名和扩展名
shutil.copy(file_path, image_folder)
print(f"Copied {file_path} to {image_folder}")
else:
# 读取json文件
with open(file_path, 'r') as f:
labelme_data = json.load(f)
image_filename = labelme_data["imagePath"]
image_width = labelme_data["imageWidth"]
image_height = labelme_data["imageHeight"]
txt_filename = os.path.splitext(image_filename)[0] + ".txt"
txt_path = os.path.join(label_folder, txt_filename)
with open(txt_path, 'w') as f:
for shape in labelme_data["shapes"]:
label = shape["label"]
points = shape["points"]
x_min, y_min = points[0]
x_max, y_max = points[1]
center_x = round(((x_min + x_max) / 2) / image_width , 2)
center_y = round(((y_min + y_max) / 2) / image_height ,2)
width = round(abs(x_min - x_max) / image_width, 2)
height = round(abs(y_min - y_max) / image_height, 2)
class_id = label_dict[label]
f.write(f"{class_id} {center_x:.6f} {center_y:.6f} {width} {height}\n")
print(f"Converted {file} to {txt_path}")
print("转换成功")
def split_data(output_folder, dataset_folder):
random.seed(0)
split_rate = 0.2 #验证集占比
origin_label_path = os.path.join(output_folder, "labels")
origin_image_path = os.path.join(output_folder, "images")
train_label_path = os.path.join(dataset_folder, "train", "labels")
os.makedirs(train_label_path, exist_ok=True)
train_image_path = os.path.join(dataset_folder, "train", "images")
os.makedirs(train_image_path, exist_ok=True)
val_label_path = os.path.join(dataset_folder, "val", "labels")
os.makedirs(val_label_path, exist_ok=True)
val_image_path = os.path.join(dataset_folder, "val", "images")
os.makedirs(val_image_path, exist_ok=True)
images = os.listdir(origin_image_path)
num = len(images)
eval_index = random.sample(images,k=int(num*split_rate))
for single_image in images:
origin_single_image_path = os.path.join(origin_image_path, single_image)
single_txt = os.path.splitext(single_image)[0] + ".txt"
origin_single_txt_path = os.path.join(origin_label_path, single_txt)
if single_image in eval_index:
#single_json_path = os.path.join(val_label_path,single_json)
shutil.copy(origin_single_image_path, val_image_path)
shutil.copy(origin_single_txt_path, val_label_path)
else:
#single_json_path = os.path.join(train_label_path,single_json)
shutil.copy(origin_single_image_path, train_image_path)
shutil.copy(origin_single_txt_path, train_label_path)
print("数据集划分完成")
with open(os.path.join(dataset_folder,"data.yaml"),"w") as f:
f.write(f"train: {dataset_folder}\n")
f.write(f"val: {val_image_path}\n")
f.write(f"test: {val_image_path}\n\n")
f.write(f"nc: {len(classes)}\n")
f.write(f"names: {classes}\n")
if __name__ == '__main__':
label_dict = {"incp_tank": 0, "cp_tank": 1}
labelme_folder = "./labelme_folder" #labelme生成的标注文件所在的文件夹
output_folder = "./test" #存储yolo标注文件的文件夹
dataset_folder = "./mydata" #存储划分好的数据集的文件夹
convert_labelmes_to_yolo(labelme_folder, output_folder)#将labelme标注文件转换为yolo格式
split_data(output_folder, dataset_folder)#划分训练集和验证级
注意:你需要新建一个label.txt文件,把涉及到的标签名字输入进去,会自动得到.yaml文件。当然也可以把这一步省略,后面我们直接copy已有的.yaml把训练、验证的路径加进去即可。