1、K-Means聚类算法
K表示超参数个数,如分成几个类别,K值就取多少。若无需求,可使用网格搜索找到最佳的K。
步骤:
1、随机设置K个特征空间内的点作为初始聚类中心;
2、对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记种类;
3、接着对标记的聚类中心之后,重新计算出每个聚类的中心点(平均值);
4、如果计算得出的新中心点与原中心点一样,那么结束,否则执行第二步。
means表示寻找新的聚类中心点是采用特征平均值确定。
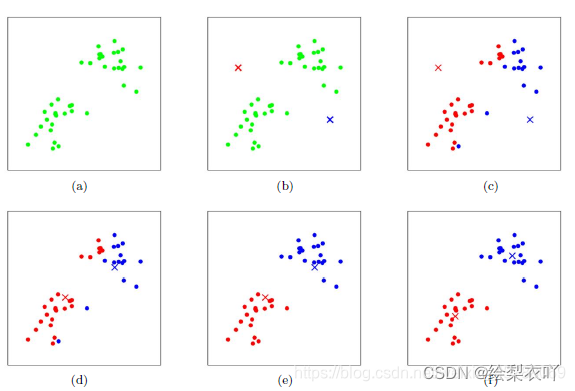
2、K-means图解
具体演示视频可查看(B站UP主:KnowingAI知智)
若我们手上有一些水果,我们希望对它们进行分类,假设分为两类,则此时K=2。
step1:随机选取两个样本点作为聚类中心点centrol

step2:计算其他每个样本与聚类中心centrol的距离,距离谁近就归为哪类,一般采用欧氏距离。

step3:根据已分类的结果,重新计算聚类中心,聚类中心是已分类的所有样本的平均值(means)

然后重复之前的步骤,重新计算距离进行划分,直到某一次计算聚类中心点和上次相同,则聚类结束。
3、聚类算法优缺点分析
聚类算法不需要手动设置标签,故属于无监督学习,相比于监督学习,它更加简单、易于理解,但是准确率方面不如监督学习。
4、K-Means()算法实现案例
API调用:
API:sklearn.cluster.KMeans(n_clusters=8, init='k=means++')
n_cluster:初始聚类中心数量,即K值
from sklearn.cluster import KMeans
import numpy as np
import matplotlib.pyplot as plt
# 生成示例数据,100个二维数据,横坐标纵坐标都在0-1范围内
X = np.random.rand(100, 2)
# 创建K-means模型
kmeans = KMeans(n_clusters=3)
# 训练模型
kmeans.fit(X)
# 获取聚类结果
labels = kmeans.labels_
# 获取每个数据点的簇标签。labels_是一个数组,表示每个数据点所属的簇的索引。
centroids = kmeans.cluster_centers_
# 获取每个簇的质心坐标。cluster_centers_是一个形状为(n_clusters, n_features)的数组,表示每个簇的质心位置。
# 可视化结果
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.scatter(centroids[:, 0], centroids[:, 1], s=300, c='red', marker='x')
plt.show()

5、聚类效果的评估(轮廓系数评估法)
内部距离最小化,外部距离最大化
轮廓系数: S C i = b i − a i m a x ( b i , a i ) SCi=\frac{b_i-a_i}{max(b_i,a_i)} SCi=max(bi,ai)bi−ai
b i b_i bi:一个簇内某个样本到其他簇的所有样本距离的最小值
a i a_i ai:一个簇内某个样本到本身簇内所有样本距离的平均值
b i > > a i b_i>>a_i bi>>ai 此时 S C i ≈ 1 SCi≈1 SCi≈1 效果好
b i < < a i b_i<<a_i bi<<ai 此时 S C i ≈ − 1 SCi≈-1 SCi≈−1 效果差
轮廓系数取值范围在 ( − 1 , 1 ) (-1,1) (−1,1),越接近 1 1 1,聚类效果越好,越接近 − 1 -1 −1,聚类效果越差
from sklearn.metrics import silhouette_score #计算轮廓系数,传入样本点和分类标签
如上例中,加上如下代码
from sklearn.metrics import silhouette_score
score = silhouette_score(X,labels)
print(f"轮廓系数为{score}")
轮廓系数为0.3873688462341751,分类效果一般。可以加一个循环找到一定范围内最优的K值,此处用轮廓系数衡量
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
import numpy as np
import matplotlib.pyplot as plt
# 生成示例数据,100个二维数据,横坐标纵坐标都在0-1范围内
X = np.random.rand(100, 2)
# 创建K-means模型
best_score=0
for k in range(2,11):
kmeans = KMeans(n_clusters=k)
# 训练模型
kmeans.fit(X)
# 获取聚类结果
labels = kmeans.labels_
# 获取每个数据点的簇标签。labels_是一个数组,表示每个数据点所属的簇的索引。
centroids = kmeans.cluster_centers_
score = silhouette_score(X,labels)
if score > best_score:
best_score = score
best_k = k
print(f'最佳簇数: {best_k}, 轮廓系数: {best_score}')
# 最佳簇数: 4, 轮廓系数: 0.42684837185343705


![[<span style='color:red;'>机器</span><span style='color:red;'>学习</span>]<span style='color:red;'>K</span>-<span style='color:red;'>means</span>——聚类<span style='color:red;'>算法</span>](https://img-blog.csdnimg.cn/direct/2079fdc508124a808fb7216649db5432.png)