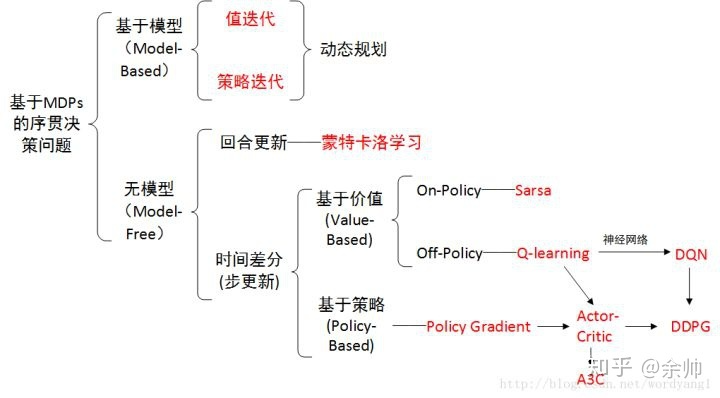
在强化学习(Reinforcement Learning, RL)中,Actor-Critic 算法是一类强大的策略梯度方法,结合了策略(Policy)和价值函数(Value Function)两种方法的优点。本文将详细介绍 Actor-Critic 算法的原理、实现细节及其在实际应用中的表现。
原理
Actor-Critic 算法由两部分组成:Actor 和 Critic。
- Actor:负责选择动作,基于策略
,参数化为
。Actor 的目标是最大化累积回报
。
- Critic:评估 Actor 的动作选择,基于价值函数
或优势函数
,参数化为
。
Actor-Critic 算法结合了策略优化和价值评估的过程,使用 Critic 来引导 Actor 的策略更新。Critic 提供的价值估计帮助 Actor 更有效地改进其策略。
策略梯度
策略梯度方法的目标是最大化累积回报 ,其梯度为:
其中, 是状态-动作值函数。使用 Critic 来估计
值,得到 Actor 的更新方向。
Advantage 函数
优势函数 是
值和状态值
之间的差异:
在实际实现中,通常使用优势函数来减少方差,提高策略更新的稳定性。
实战示例
以下是一个简单的 Actor-Critic 算法的实现示例,基于一个离散动作空间的环境:
import gym
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
# 环境
env = gym.make('CartPole-v1')
# 超参数
gamma = 0.99
learning_rate = 0.001
# 网络架构
class ActorCritic(tf.keras.Model):
def __init__(self, num_actions):
super(ActorCritic, self).__init__()
self.common = layers.Dense(128, activation='relu')
self.actor = layers.Dense(num_actions, activation='softmax')
self.critic = layers.Dense(1)
def call(self, inputs):
x = self.common(inputs)
return self.actor(x), self.critic(x)
# 训练过程
def train():
num_actions = env.action_space.n
model = ActorCritic(num_actions)
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
for episode in range(1000):
state = env.reset()
state = tf.convert_to_tensor(state)
state = tf.expand_dims(state, 0)
episode_reward = 0
with tf.GradientTape() as tape:
while True:
action_probs, critic_value = model(state)
action = np.random.choice(num_actions, p=np.squeeze(action_probs))
next_state, reward, done, _ = env.step(action)
next_state = tf.convert_to_tensor(next_state)
next_state = tf.expand_dims(next_state, 0)
_, next_critic_value = model(next_state)
td_target = reward + gamma * next_critic_value * (1 - int(done))
td_error = td_target - critic_value
actor_loss = -tf.math.log(action_probs[0, action]) * td_error
critic_loss = td_error ** 2
total_loss = actor_loss + critic_loss
episode_reward += reward
state = next_state
if done:
break
grads = tape.gradient(total_loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
print(f"Episode {episode}, Total Reward: {episode_reward}")
train()
Actor-Critic 算法的优缺点
优点:
- 高效的策略更新:结合了策略梯度和价值评估,使策略更新更高效。
- 稳定性好:通过使用价值函数评估,减少策略梯度的方差,提高训练稳定性。
- 适用于连续和离散动作空间:可以处理各种类型的动作空间。
缺点:
- 实现复杂:相比于单独的策略梯度或价值方法,实现复杂度更高。
- 依赖价值评估:价值函数评估的质量直接影响策略更新效果。
总结
Actor-Critic 算法通过结合策略梯度和价值评估,提供了一种高效、稳定的策略优化方法。它在处理复杂环境和大规模问题时表现出色。理解和实现 Actor-Critic 算法不仅能够帮助我们在强化学习领域中取得更好的成绩,还能为解决实际问题提供有力工具。