ShuffleManager
shuffle系统的入口。ShuffleManager在driver和executor中的sparkEnv中创建。在driver中注册shuffle,在executor中读取和写入数据。
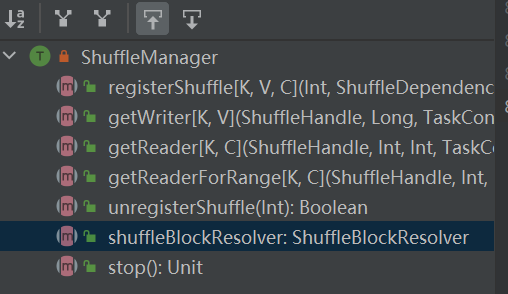
registerShuffle:注册shuffle,返回shuffleHandle
unregisterShuffle:移除shuffle
shuffleBlockResolver:获取shuffleBlockResolver,用于处理shuffle和block之间的关系
getWriter:获取partition对应的writer,在executor的map task中调用
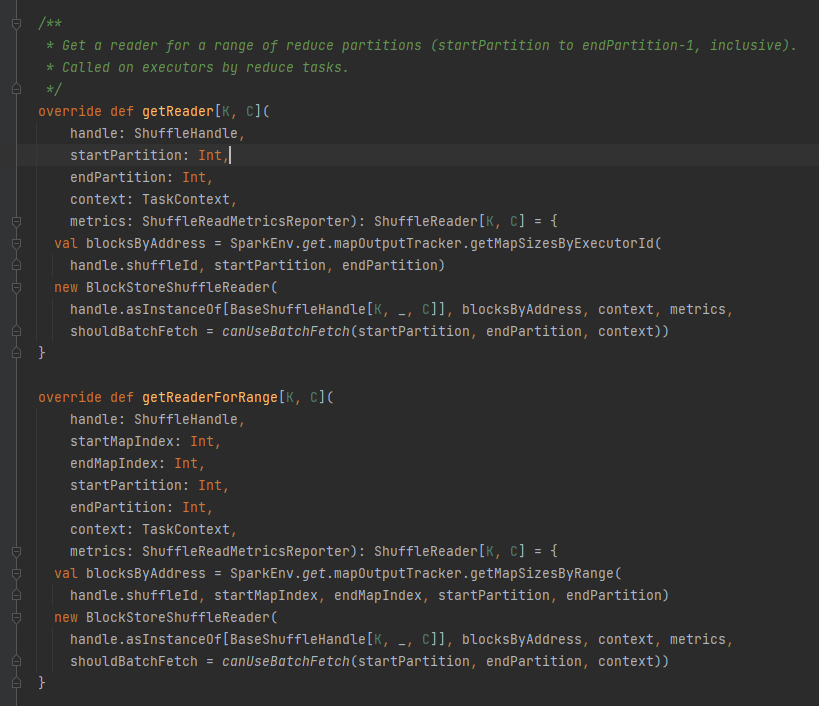
getReader、getReaderForRange:获取一段范围partition的reader,在executor的 reduce task中调用
SortShuffleManager
是shuffleManager的唯一实现。
在基于sort的shuffle中,进入的消息会按照partition进行排序,最后输出一个单独的文件。
reducer会读取这个文件的一段区域数据。
当输出的文件太大了,不能全部放在内存中的时候,会spill在磁盘上生成排序的中间结果文件,这些中间文件会合并成一个最终文件输出。
Sort-based shuffle有两个方式:
- 序列化sort,使用序列化sort需要满足三个条件:
- 没有map-side combine
- 支持序列化的值relocation(KryoSerializer和sparkSql自定义序列化器)
- 小于等于16777216个partition
- 非序列化sort,其它所有情况都可以使用非序列化sort
序列化sort的优势
在序列化sort模式下,shuffle writer将进来的消息序列化后保存在一个数据结构中并排序。
- 二进制数据排序而非Java对象:排序操作直接在序列化的二进制数据上进行,而不是在Java对象上,这样可以降低内存消耗并减少垃圾回收(GC)的开销。
这一优化要求所使用的记录序列化器具备特定属性,使得序列化后的记录能够在无需先反序列化的情况下重新排序。 - 高效的缓存排序算法:采用专门设计的缓存效率高的排序器(ShuffleExternalSorter),它能够对压缩后的记录指针数组和分区ID进行排序。通过每个记录仅占用8字节的空间,这种策略使得更多的数据能够装入缓存中,从而提升性能。
- 溢出合并过程针对同一分区内的序列化记录块进行,整个合并过程中不需要对记录进行反序列化,避免了不必要的数据转换开销。
- 如果溢出压缩编解码器支持压缩数据的拼接,那么溢出合并过程仅需简单地将序列化并压缩过的溢出分区数据拼接起来,形成最终输出分区。这允许使用高效的直接数据拷贝方法,如NIO中的transferTo,并且在合并过程中避免了分配解压缩或复制缓冲区的需要,提升了整体效率。
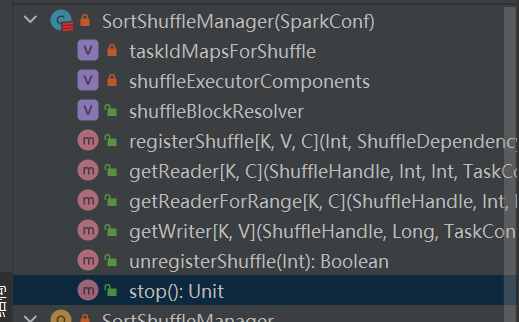
registerShuffle
根据不同场景选择对应的handle。优先顺序是BypassMergeSortShuffleHandle>SerializedShuffleHandle>BaseShuffleHandle
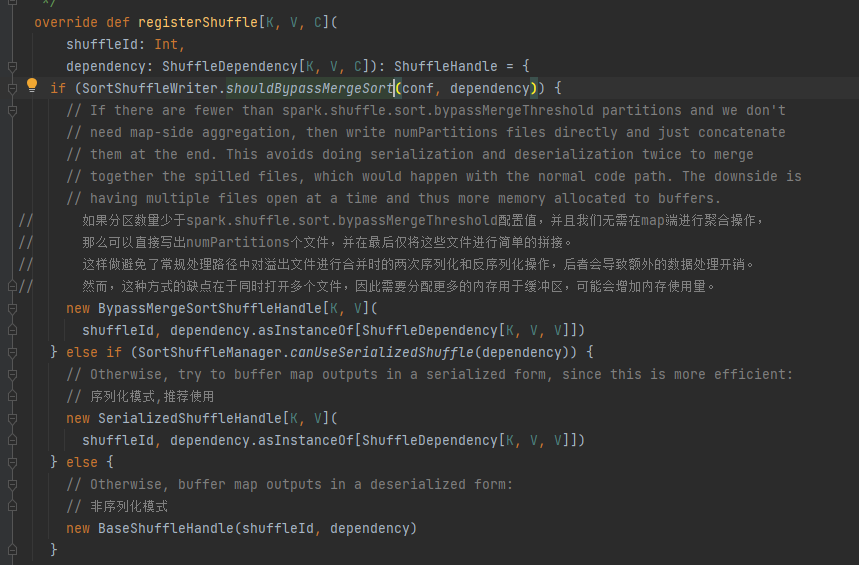
bypass条件:没有mapside,partition数量小于等于_SHUFFLE_SORT_BYPASS_MERGE_THRESHOLD_

序列化handle条件:序列化类支持支持序列化对象的迁移,并且不使用mapSideCombine操作以及父RDD的分区数不大于 (1 << 24)
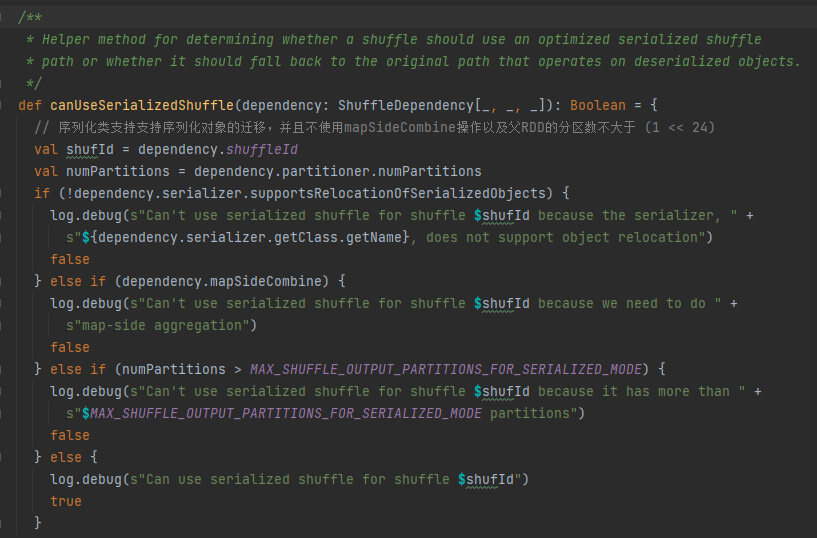
getWriter
首先缓存此次的shuffle和map信息到taskIdMapsForShuffle_中_
根据shuffle对应的handle选择对应的writer.
BypassMergeSortShuffleHandle->BypassMergeSortShuffleWriter
SerializedShuffleHandle->UnsafeShuffleWriter
BaseShuffleHandle->SortShuffleWriter
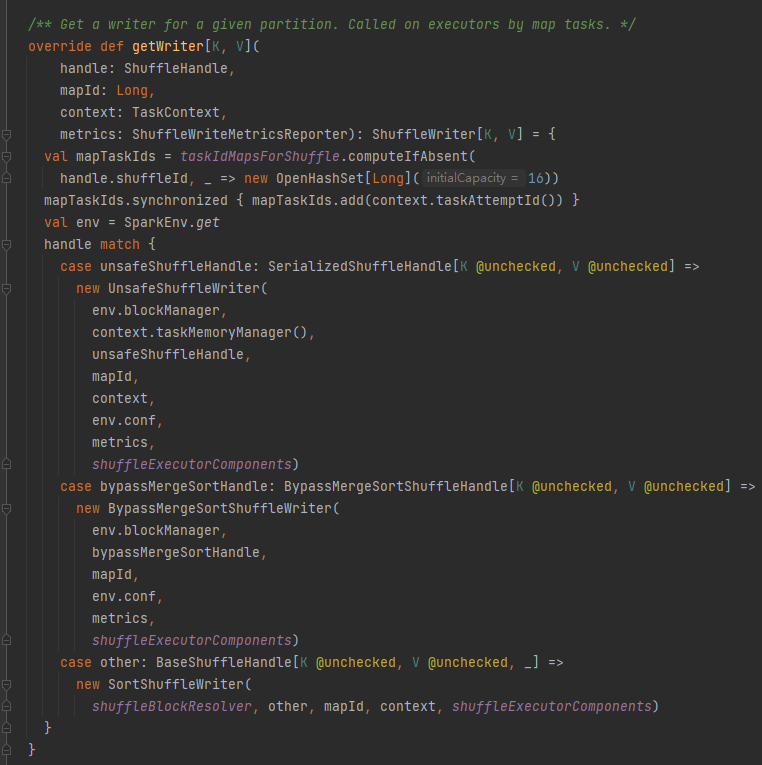
unregisterShuffle
taskIdMapsForShuffle移除对应的shuffle和shuffle对应map产生的文件
getReader/getReaderForRange
获取shuffle文件对应全部block地址,即blocksByAddress.
创建BlockStoreShuffleReader对象并返回.
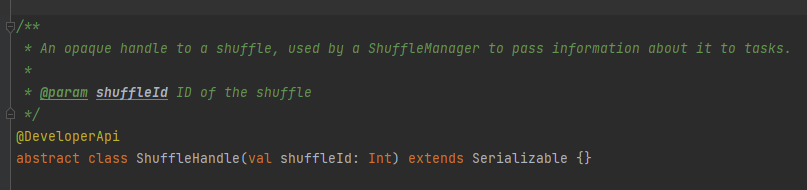
ShuffleHandle
主要是用来传递shuffle的参数,同时也是一个标记,标记选择哪个writer
BaseShuffleHandle

BypassMergeSortShuffleHandle

SerializedShuffleHandle
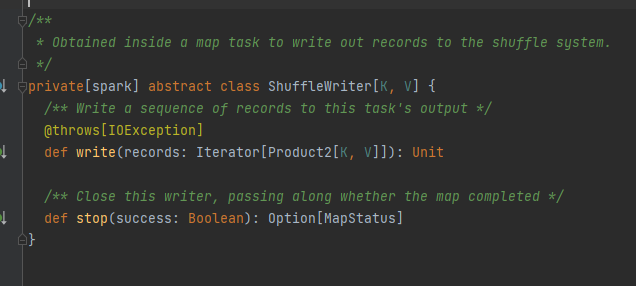
ShuffleWriter
抽象类,负责map任务输出消息.主要方法是write,有三个实现类
- BypassMergeSortShuffleWriter
- SortShuffleWriter
- UnsafeShuffleWriter
后面在单独分析。
ShuffleBlockResolver
特质,实现类可以根据mapId、reduceId、shuffleId来获取对应的block数据.
IndexShuffleBlockResolver
ShuffleBlockResolver的唯一实现类。
创建并维护逻辑块与物理文件位置之间的映射关系,针对来自同一map任务的shuffle块数据。
属于同一个map任务的shuffle块数据会被存储在一个整合的数据文件中。
而这些数据块在数据文件中的偏移量,则被单独存储在一个索引文件中。
.data是数据文件后缀
.index是索引文件后缀
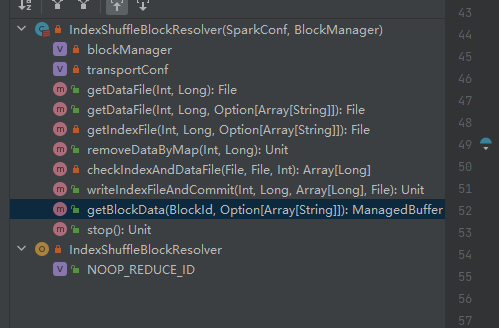
getDataFile
获取数据文件。
生成ShuffleDataBlockId,调用的blockManager.diskBlockManager.getFile方法获取file
getIndexFile
同getDataFile类似
生成ShuffleIndexBlockId,调用的blockManager.diskBlockManager.getFile方法获取file

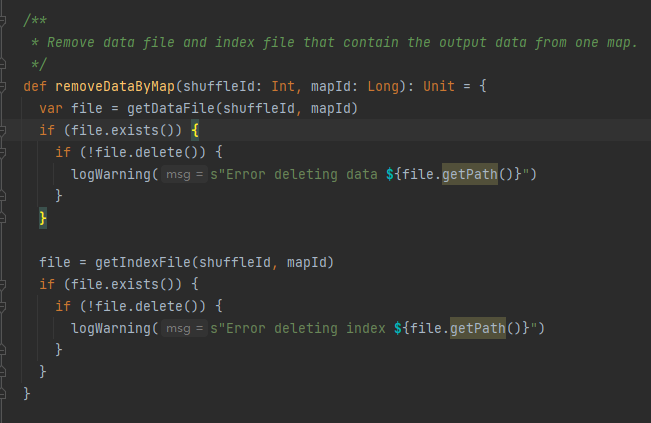
removeDataByMap
根据shuffleId和mapId获取到data文件和index文件,然后删除
writeIndexFileAndCommit
根据mapId、shuffleId获取对应的data文件和index文件。
检查data文件和index文件是否存在并且能够匹配上,直接返回。
不能匹配上,就生成新的index临时文件。再重命名生成新的index文件和data文件并返回。
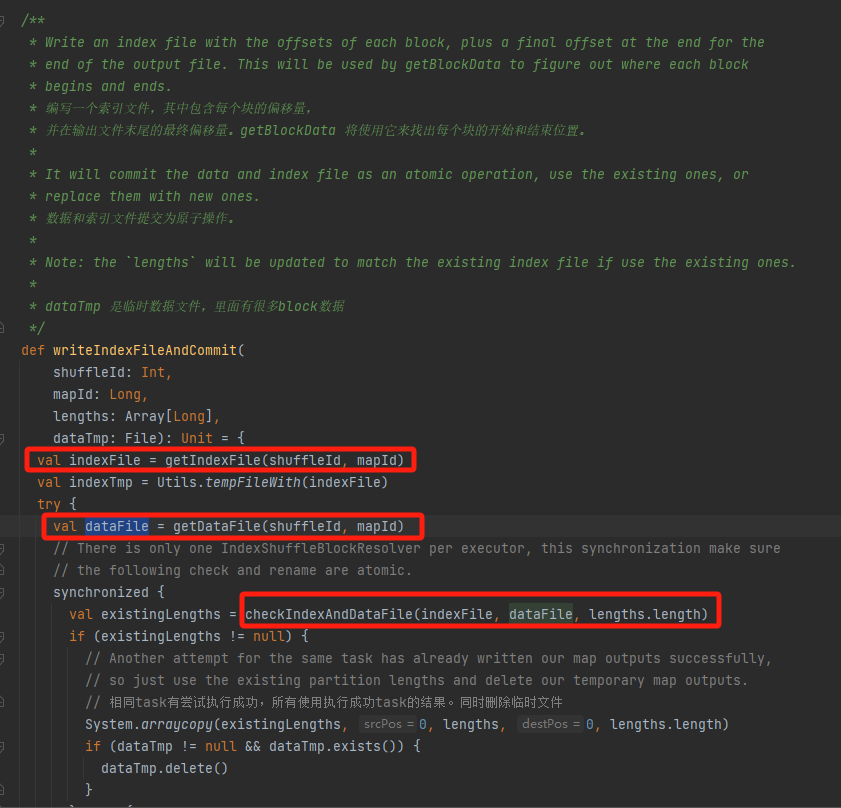

假设shuffle有3个partition,对应数据大小分别是1000、1500、2500。
index文件,首行是0,后面都是partition数据的累加值,第二行是1000,第三行是1000+1500=2500,第三行是2500+2500=5000.
data文件是按照partition大小排序进行存储的。

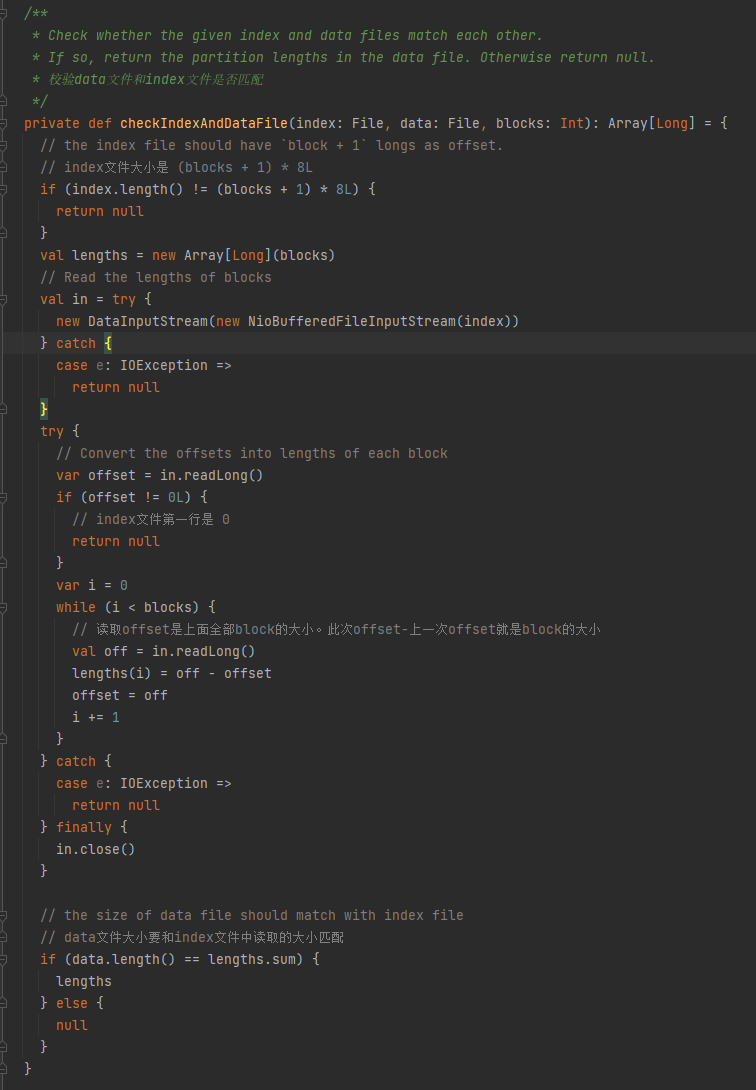
checkIndexAndDataFile
校验data文件和index文件是否匹配,不匹配返回null,匹配返回partition大小的数组。
1.index文件大小是 (blocks + 1) * 8L
2.index文件第一行是 0
3.获取partition的大小写入lengths,lengths的汇总值等于data文件大小
满足上面三个条件,返回lengths,否则返回null
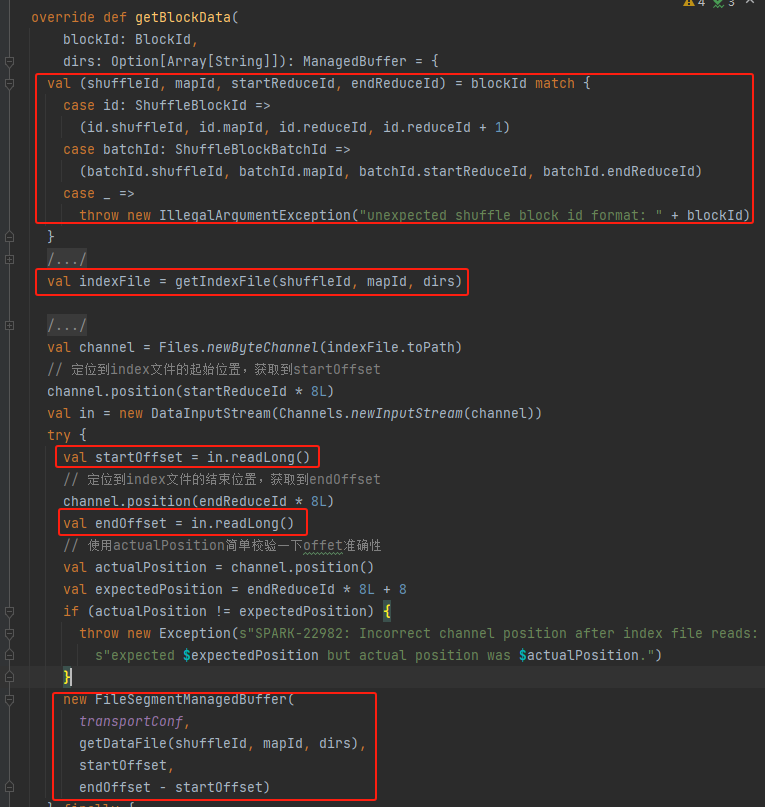
getBlockData
获取到shuffleId、mapId、startReduceId、endReduceId
获取到index文件
读取对应的startOffset和endOffset
使用data文件、startOffset、endOffset生成FileSegmentManagedBuffer并返回