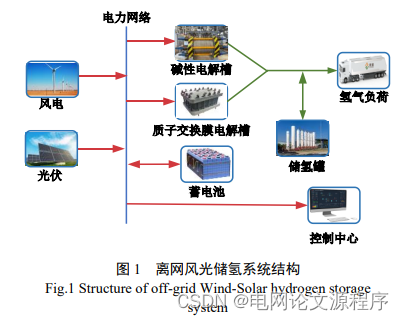
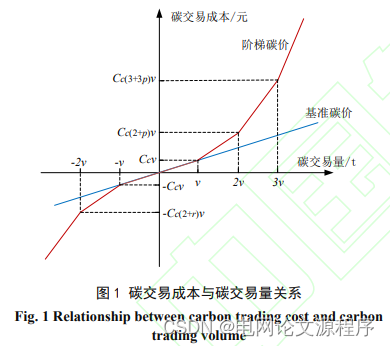
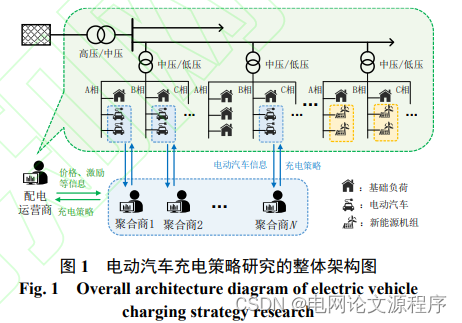
本专栏栏目提供文章与程序复现思路,具体已有的论文与论文源程序可翻阅本博主免费的专栏栏目《论文与完整程序》
论文与完整源程序_电网论文源程序的博客-CSDN博客![]() https://blog.csdn.net/liang674027206/category_12531414.html
https://blog.csdn.net/liang674027206/category_12531414.html
这篇论文的核心内容是提出了一个基于完全自适应噪声集合经验模态分解(CEEMDAN)和奇异谱分析(SSA)双重分解方法,以及双向长短时记忆网络(BiLSTM)的中长期电力负荷预测模型。以下是关键点的总结:
研究背景:中长期电力负荷预测对于电力市场策略制定、电网规划设计和可再生能源调度具有重要意义。由于中长期负荷序列噪声含量高,难以直接提取序列周期规律,影响预测精度。
研究目的:解决中长期电力负荷预测中存在的噪声干扰问题,提高预测的准确性。
方法论:
- 使用CEEMDAN对历史负荷数据进行分解,得到多个具有更清晰周期规律的子序列。
- 利用多尺度熵(MSE)计算子序列的复杂度,并将复杂度相似的子序列重构聚合。
- 采用SSA对重构后的复杂子序列进行二次分解,去除噪声并提取重要规律。
- 将最终得到的子序列输入BiLSTM模型进行预测。
技术创新点:
- 双重分解方法有效提高了预测精度,通过CEEMDAN和SSA的结合,深入挖掘负荷序列的历史规律。
- BiLSTM模型考虑了时间序列的正向和反向信息,增强了模型对时间序列上下文的感知力。
实验结果:
- 实验结果显示,经过双重分解可以将均方根误差(RMSE)降低87.4%。
- BiLSTM模型在预测未来一年的负荷序列时,拟合系数最高可提高2.5%。
- 提出的误差修正技术能够进一步将RMSE降低9.7%。
研究意义:该研究为电力系统中长期负荷预测提供了一种新的方法,能够提高预测精度,对电力系统的稳定运行和优化管理具有重要的实际应用价值。
论文信息:论文由王继东、于俊源、孔祥玉撰写,发表于《电网技术》杂志,网络首发日期为2024年7月4日。
基金项目:该研究得到了国家重点研发计划项目(2022YFB4200703)的支持。
这篇论文提供了一种结合了先进信号处理技术和深度学习的方法,以提高中长期电力负荷预测的准确性,并通过实验验证了其有效性。

根据论文内容,复现仿真实验的大致思路和程序代码框架如下:
1. 数据准备
- 收集历史电力负荷数据、气象数据(如温度、湿度、风速)和节假日信息。
- 对数据进行预处理,包括异常值处理、缺失值填补、数据归一化。
2. CEEMDAN分解
- 使用CEEMDAN方法对负荷数据进行分解,获取若干子序列。
3. 多尺度熵(MSE)计算
- 对每个子序列计算多尺度熵,评估其复杂度。
4. 子序列重构
- 根据MSE结果,将复杂度相似的子序列进行重构聚合。
5. SSA分解
- 对重构后的复杂子序列使用SSA进行二次分解,去除噪声。
6. BiLSTM模型训练与预测
- 将处理后的子序列输入BiLSTM模型进行训练。
- 使用训练好的模型进行中长期负荷预测。
7. 误差修正
- 结合外部因素(如气象条件)对预测结果进行误差修正。
8. 结果评估
- 使用RMSE、拟合系数等指标评估预测结果的准确性。
以下是使用Python语言的伪代码表示:
# 导入所需的库
import numpy as np
import pandas as pd
from keras.models import Sequential
from keras.layers import LSTM, Bidirectional, Dense
from sklearn.preprocessing import MinMaxScaler
from ceemdan import ceemdan_decomposition
from multiscale_entropy import calculate_mse
from singular_spectrum_analysis import ssa_decomposition
# 数据预处理
def preprocess_data(data):
# 异常值处理、缺失值填补、归一化处理
scaler = MinMaxScaler()
normalized_data = scaler.fit_transform(data)
return normalized_data
# CEEMDAN分解
def ceemdan_decompose(data):
return ceemdan_decomposition(data)
# 多尺度熵计算
def calculate_complexity(subsequences):
complexities = []
for seq in subsequences:
complexities.append(calculate_mse(seq))
return complexities
# SSA分解
def ssa_decompose(subsequences):
# 对每个子序列进行SSA分解
pass
# BiLSTM模型构建与训练
def train_bilstm_model(subsequences):
model = Sequential()
model.add(Bidirectional(LSTM(100), input_shape=(subsequences.shape[1], 1)))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse')
model.fit(subsequences, epochs=20, batch_size=32)
return model
# 误差修正
def error_correction(predictions, external_factors):
# 结合外部因素对预测结果进行修正
pass
# 主函数
def main():
# 加载数据
data = pd.read_csv('historical_load_data.csv')
# 数据预处理
normalized_data = preprocess_data(data)
# CEEMDAN分解
subsequences = ceemdan_decompose(normalized_data)
# 多尺度熵计算
complexities = calculate_complexity(subsequences)
# 子序列重构
reconstructed_subsequences = reconstruct_subsequences(subsequences, complexities)
# SSA分解
denoised_subsequences = ssa_decompose(reconstructed_subsequences)
# BiLSTM模型训练
bilstm_model = train_bilstm_model(denoised_subsequences)
# 预测
predictions = bilstm_model.predict(denoised_subsequences)
# 误差修正
final_predictions = error_correction(predictions, external_factors)
# 结果评估
evaluate_predictions(final_predictions, normalized_data)
if __name__ == "__main__":
main()请注意,上述代码仅为伪代码,实际实现时需要根据论文中的具体算法细节和所用数据集进行调整。此外,ceemdan_decomposition、calculate_mse、ssa_decomposition、reconstruct_subsequences 和 evaluate_predictions 函数需要根据论文中的方法具体实现。
本专栏栏目提供文章与程序复现思路,具体已有的论文与论文源程序可翻阅本博主免费的专栏栏目《论文与完整程序》
论文与完整源程序_电网论文源程序的博客-CSDN博客![]() https://blog.csdn.net/liang674027206/category_12531414.html
https://blog.csdn.net/liang674027206/category_12531414.html