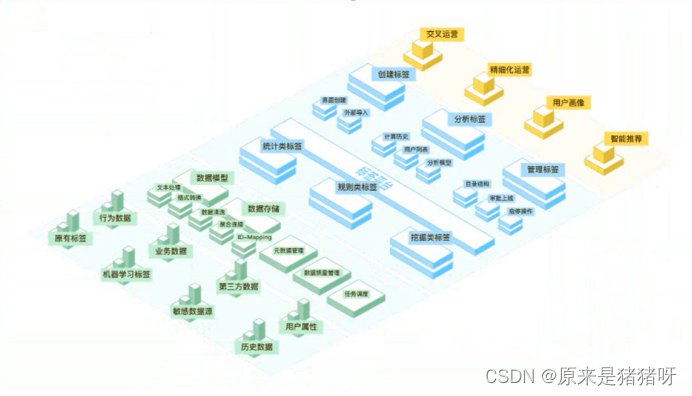
我们讲解了个性化流量分发体系搭建流程中的数据加工阶段,不过在前面我们主要讲解了如何构建结构化标签,并未提及用户画像和物品画像的构建,以及如何将用户画像与物品画像进行匹配。本节课我们探讨下如何通过深加工帮助用户快速获取有效信息。
对于大部分互联网公司而言,它们提供的服务主要以信息发布和交易撮合为主,因此在搭建个性化流量分发体系时,我们最大的困难是如何基于流量场景实现用户与物品的快速匹配,从而实现用户利益与平台利益最大化。
为了实现这个目标,首先我们需要将用户标签和物品标签进行解构,然后通过某种媒介形式(也就是 02 讲介绍的结构化标签体系)把这两者进行快速匹配。
比方说你正在请女朋友吃饭,拿到菜单时到底该点什么菜呢?如果你们之前一起吃过好几次饭,你就已经知道她喜欢吃什么不喜欢吃什么(用户动态行为),她是不是有忌口(用户数据),再看一眼饭店菜单(物品静态数据),就立马知道点什么菜了。
通过以上这个例子,我们大致理解了这个场景。那如何解构用户标签和物品标签呢?这就涉及用户画像和物品画像的构建。
下面我们先一起来看看用户画像的构建过程。
构建用户画像
什么是用户画像?用户画像说白了就是一个人的标签集合。关于用户标签是什么以及怎么划分,02 讲中我们已经介绍过了,这里就不过多赘述了
那如何构建用户画像呢?构建用户画像前,我们首先需要从用户基础信息和动机信息出发,再从不同类型用户中抽取出一个典型特征来还原一个用户的特征,而这个特征抽取的过程就是用户画像构建的过程。
为了便于你理解,我们也举一个简单例子说明下。以58 同城本地服务为例,为了尽可能全面地描述用户信息,首先我们需要挖掘用户的人口属性、地理位置、上网习惯、兴趣偏好、业务行为偏好、业务属性等数据,然后将这些数据不断优化更新,再抽象出具体的信息标签,最后通过组合的方式搭建出一个立体虚拟模型。
1.用户动机与特征
学到这,我们有必要普及下用户动机、特征这两个概念。
1)用户动机
在选择和使用媒体时,用户往往具备很强的主动权和目的性,因此用户动机其实指的就是用户使用互联网的目的,它通常分为社交、消磨时间、查找信息、分享、表达、娱乐……这几种。
2)特征
用户画像由大量的特征组成,比如基本特征、统计特征、偏好特征等,而特征的特点分为以下三点,也可参考下图进行理解。
特征最直观的一个属性是有特征值,而这个特征值可以是单值,也可以是多值,它具有具体数据类型、数据分布,比如枚举范围、日期类、真实值等。
同时,特征还有生成逻辑,它主要通过规则或者算法模型产生,且在不同条件下它还会产生新的特征。
除此之外,特征还能区分类目城市。

如果我们想要根据用户画像来进行针对性的业务提升,就需要对画像中的大量特征及特征值进行维护和管理,接下来我们一起看下特征管理的实现过程及注意要点。
2.特征管理的实现过程
在实际业务中存在着具体特征、管理特征与特征值时,首先我们通过维度将具体特征进行归类,并对特征值进行管理;接着,针对不同条件我们使用限定词来扩充特征;最后,我们把特征和特征值属性归类到特征和特征值字典中进行维护。
下图所示是我们的实际业务场景——58 同城到家精选保洁业务。

在特征管理过程中,有几个注意要点我需要说明下。
在生成特征后,如果重新导入特征,特征依赖就会出现环状结构,引起特征血缘错乱。
因此,业务方申请特征时,我们需要检测是否有环状结构。如果该特征在使用时又产生了新数据,那么这些新数据就会通过数仓写入画像系统,此时我们同样需要对其进行检测。
以下图为例,业务 1 使用特征 1 会产出特征 2,业务 2 使用特征 2 会产出特征 3,如果业务 3 使用特征 1 和特征 3 会产出特征 2,根据之前的内容介绍我们推导特征 2 会产出特征 3,也就是说这种情况下会出现环状结构。

那遇到这种情况怎么解决呢?我们发现此问题的出现是因为特征 1 使用了特征 3,因此我们不能使用特征 3 ,而应当把特征 1 和特征 2 整合计算后新生成特征 4,这样才不会出现依赖环。
由于维度匮乏、信息缺失、信息不准确等原因,很多时候我们仅依靠用户个人填写的基础信息很难对真实系统进行全方位的刻画,因此我们还需要借助算法模型进行预测。
比如一些看似抽象的职业标签,通过海量的数据分析后我们就能推测出一部分用户的职业类型,且经过模型预测后该值的概率较高,比如那些经常定位在政府机关的用户,其为公务员的可能性比较大。
再比如用户的下单行为,我们也能通过海量的数据分析推测出一部分人正处于哪个人生阶段,且经过模型预测后该值的概率较高,比如最近经常浏览“房屋装修”服务的用户,有可能正处于装修期。再比如在服务评价里经常称呼男朋友、女朋友的用户有可能正处在恋爱期。
当然,这些蛛丝马迹的可能仅仅是相对应算法的输入特征,至于结果究竟如何还需要通过更完善的模型来判别。
那么用户画像构建好后,它可以用来做什么呢?
3.用户画像的应用用途
有了用户画像后,我们就可以使用它进行业务分析、精准运营、算法应用、广告投放、用户变现等。如下图所示,通过分析画像当中用户的基本属性、消费信息、行为数据,我们就可以对其进行个性化推荐、精准广告投放。

其实,用户画像还可以对外提供三大能力:
1) IDMapping “能唯一定位一个人”
2) 受众定向 “能找到这批人”
3) 人群扩选 “能找到和这批人相似的人”
比如 58 集团拥有 58 同城、赶集网、安居客、中华英才网等多个互联网业务,彼此之间的用户体系需要打通。在 58 同城内部,我们就是通过用户 ID 打通了 58 同城、赶集网、安居客等平台的核心数据源,各使用方使用一个账号或手机号就能获取到该用户在各个业务线的全部行为。

这里,我们主要提一下 IDMapping、受众定向、人群扩选这三个概念。
IDMapping
是指针对单个用户 ID,我们基于用户历史行为,比如登录记录、下单记录、评价记录等多维信息为其呈现对应的特征画像。
受众定向
是指通过对用户包人群进行计算,利用多标签间交集、并集(去重)、差集等操作进行人群的筛选和生成。俗话说“物以类聚,人以群分”,相比 ID Mapping 而言,受众定向针对的不是某个单个用户,而是分析呈现一群用户的特征。
以 58 同城本地服务为例,找“月嫂”的用户通常不是找“婚庆服务”的用户,卖家可以把最近 30 天在店铺有成交记录的用户的身份和偏好进行分析,然后相应调整营销策略、定向投放广告。
人群扩选
是将已知的一部分用户作为种子,产出特征相似更广的用户集,人群扩选常见的流量应用场景如广告精准投放、拉新促活等,它的实现思路主要分为以下三大步骤。
特征汇总 :发现用户的共有特征,便于寻找其相似用户。
特征处理 :一般来说,不同特征之间可能存在不同数据类型,且连续型特征之间的量级往往差异很大。以 58 同城本地服务的客单价特征为例,房屋装修的客单价从几万到几十万不等,而管道疏通的客单价一般是几十到上百不等,为此特征处理就显得尤为重要。
特征差异化分析 :在对特征进行差异化分析时,我们先对输入人群和全网用户特征向量上的比例进行对比,然后分析两者之间差异,再提取一部分显著性差异,最后利用显著性特征对输入人群进行放大。
以 58 同城本地服务为例,经过特征汇总和处理后,我们发现找“租房”的用户与找“搬家”、“保洁”的用户存在一定重合,从而快速找到了这三个品类的潜在用户群体。
构建物品画像
物品画像同用户画像一样,我们可以把物品画像构建简单地理解为物品信息标签化的过程。
在这个过程中,我们首先需要挖掘物品结构化标签,再通过各个维度把结构化标签进行有序组织,最终形成物品画像。
物品画像主要分为基本信息、供给侧信息、存储侧信息、消费侧信息这 4 个层面,下面我们以 58 同城到家精选服务画像为例,
基本信息包括类目属性、价格信息、店铺信息、商家信息等;
供给侧信息包括商家供给数、商家服务能力分等;
存储侧信息包括库存数、库存金额等;
消费侧信息包括订单数、下单用户数、销量信息、优惠券金额、实付金额等,这些信息经过不同维度提取后,最终构成了完整的物品画像。
用户画像与物品画像匹配
用户画像与物品画像都构建好之后,我们就可以通过个性化流量分发体系实现快速匹配了,如搜索、推荐、精准推送等。
为方便你更容易理解这部分内容,我们简单举个例子说明下。
比如 58 同城到家精选用户标签中有价格段偏好,物品画像标签中也有价格段偏好,如果用户经常下单 100~200 元的保洁服务,用户画像中就会产生一个 100~200 元保洁服务的标签。而如果物品画像中保洁服务的 SKU 正好是 100~200 元,我们就可以利用个性化流量分发体系将用户标签与物品标签对齐,最终实现个性化、精准化匹配。
在利用画像将用户和物品进行打通时,用户画像和物品画像之间往往存在着很多交集和联动,这就要求我们通过大数据对画像系统进行查询组合处理。比如我们需要通过画像找到物品的目标用户,再将物品推荐或推送给用户,这个过程两者之间就存在着很多交集与联动。
而查询组合的过程其实就是一个树形结构(如下图所示),其中叶子节点是具体查询条件,它用来记录查询条件,如查询字段、条件符、值等。根节点是条件符;在该条件基础之上根节点又会与新查询条件聚合,并创建出一个新的叶子节点,后续并以此类推。而关系节点连接叶子节点,用来记录左查询条件、交集并集操作符及右查询条件。

你可以看到,在查询组合时是多状态的,为了简化查询业务流程,就需要我们对查询条件进行一定的封装,那我们又该如何对查询条件进行封装呢?查询条件封装过程分为 4 个步骤,具体如下图所示:
查询条件创建叶子节点;
与其他节点取交集/并集运算;
创建新节点(当前节点为左节点,设置运算符,其他节点为右节点);
返回新节点。

总的来说,在用户画像与物品画像匹配的过程中,精细化、个性化才是根本。
体系评估
在使用用户画像和物品画像时,首先我们需要对画像体系进行有效性判断,即体系评估,以期达成使用目标。
在对用户画像和物品画像评估时,我们可以基于画像标签的指标分别从准确率、覆盖率、平均标签数、时效性、其他指标等维度进行评定。在这里,我们把用户和物品统称为项目,以下举例皆是以用户画像为主,物品画像为辅。
1.准确率
准确率是画像标签中最核心的指标,对于体系匹配效果具有决定性意义,比如说我们想找到 58 同城到家精选偏好是 100-200 元的保洁服务的用户,如果标记为 100-200 元的这个用户的标签是错的,那我们找到的用户也肯定是错的。
标签的准确率为被打对标签的项目数除以打上这个标签的项目数,关于准确率的计算方法如下所示:

2.覆盖率
覆盖率是画像标签的重要指标之一,是体系匹配效能达成的保证,比如我们还是想找 58 同城到家精选偏好是 100-200元 的保洁服务的用户,如果“100-200 元”这个标签标记的用户只有 3 人,那么这个标签也没有意义,因此标签需要覆盖总体项目的一定比例。
关于覆盖率的计算方法是打上该标签的项目数与总项目数之比,其具体计算公式如下所示:

3.平均标签数
标签是项目单个维度的反映,因此我们需要给每个项目打上多种标签,只有这样我们才能更全面地理解这个项目,那项目的平均标签数如何定义呢?
关于平均标签数的计算方法是项目的标签总数与被打上标签的项目数之比,其具体计算公式如下所示:

4.其他指标
标签具有唯一性、可读性等其他指标,因这些指标无法给出量化标准,所以在评估时只是用来作为辅助参考,如在 58 同城本地服务中,“货车搬家”“厢货搬家”属于同义标签,因此需要进行统一归一化处理。
最后,特别声明一下:在对画像体系进行评估时,我们需要优先保证画像标签的准确率和覆盖率。
本节总结
学到这里,恭喜你已经了解了用户画像和物品画像搭建的全过程,04 讲我们将开始了解推荐系统的评价标准。
对于用户画像和物品画像构建的内容,如果你还有不同的见解,欢迎在留言区与我分享个人观点。另外,如果本节课内容对你有启发和帮助,欢迎分享给更多的朋友哦~