💐💐扫码关注公众号,回复 spark 关键字下载geekbang 原价 90 元 零基础入门 Spark 学习资料💐💐
Spark 只知道开发者要做 map、filter,但并不知道开发者打算怎么做 map 和 filter。换句话说,对于 Spark 来说,辅助函数 f 是透明的。在 RDD 的开发框架下,Spark Core 只知道开发者要“做什么”,而不知道“怎么做”。这让 Spark Core 两眼一抹黑,除了把函数 f 以闭包的形式打发到 Executors 以外,实在是没有什么额外的优化空间。而这,就是 RDD 之殇。
DataFrame 是携带数据模式(Data Schema)的结构化数据,而 RDD 是不携带 Schema 的分布式数据集。恰恰是因为有了 Schema 提供明确的类型信息,Spark 才能耳聪目明,有针对性地设计出更紧凑的数据结构,从而大幅度提升数据存储与访问效率。
DataFrame 定义了一套 DSL 算子(Domain Specific Language)DSL 语言往往是为了解决某一类特定任务而设计,非图灵完备,因此在表达能力方面非常有限。DataFrame 的算子大多数都是标量函数(Scalar Functions),它们的形参往往是结构化二维表的数据列(Columns)。尽管 DataFrame 算子在表达能力方面更弱,但是 DataFrame 每一个算子的计算逻辑都是确定的,比如 select 用于提取某些字段,groupBy 用于对数据做分组,等等。这些计算逻辑对 Spark 来说,不再是透明的,因此,Spark 可以基于启发式的规则或策略,甚至是动态的运行时信息,去优化 DataFrame 的计算过程。
Catalyst 优化器的职责在于创建并优化执行计划,它包含 3 个功能模块,分别是创建语法树并生成执行计划、逻辑阶段优化和物理阶段优化。Tungsten 用于衔接 Catalyst 执行计划与底层的 Spark Core 执行引擎,它主要负责优化数据结果与可执行代码。
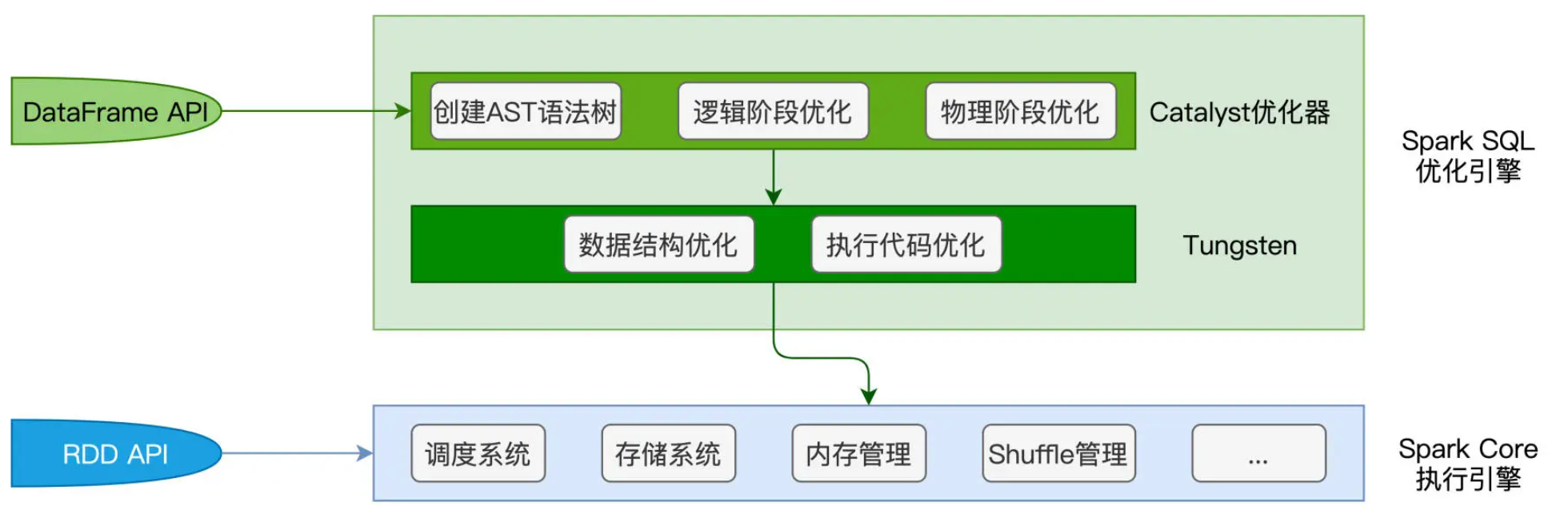
Catalyst 优化器
基于代码中 DataFrame 之间确切的转换逻辑,Catalyst 会先使用第三方的 SQL 解析器 ANTLR 生成抽象语法树(AST,Abstract Syntax Tree)。AST 由节点和边这两个基本元素构成,其中节点就是各式各样的操作算子,如 select、filter、agg 等,而边则记录了数据表的 Schema 信息,如字段名、字段类型,等等。
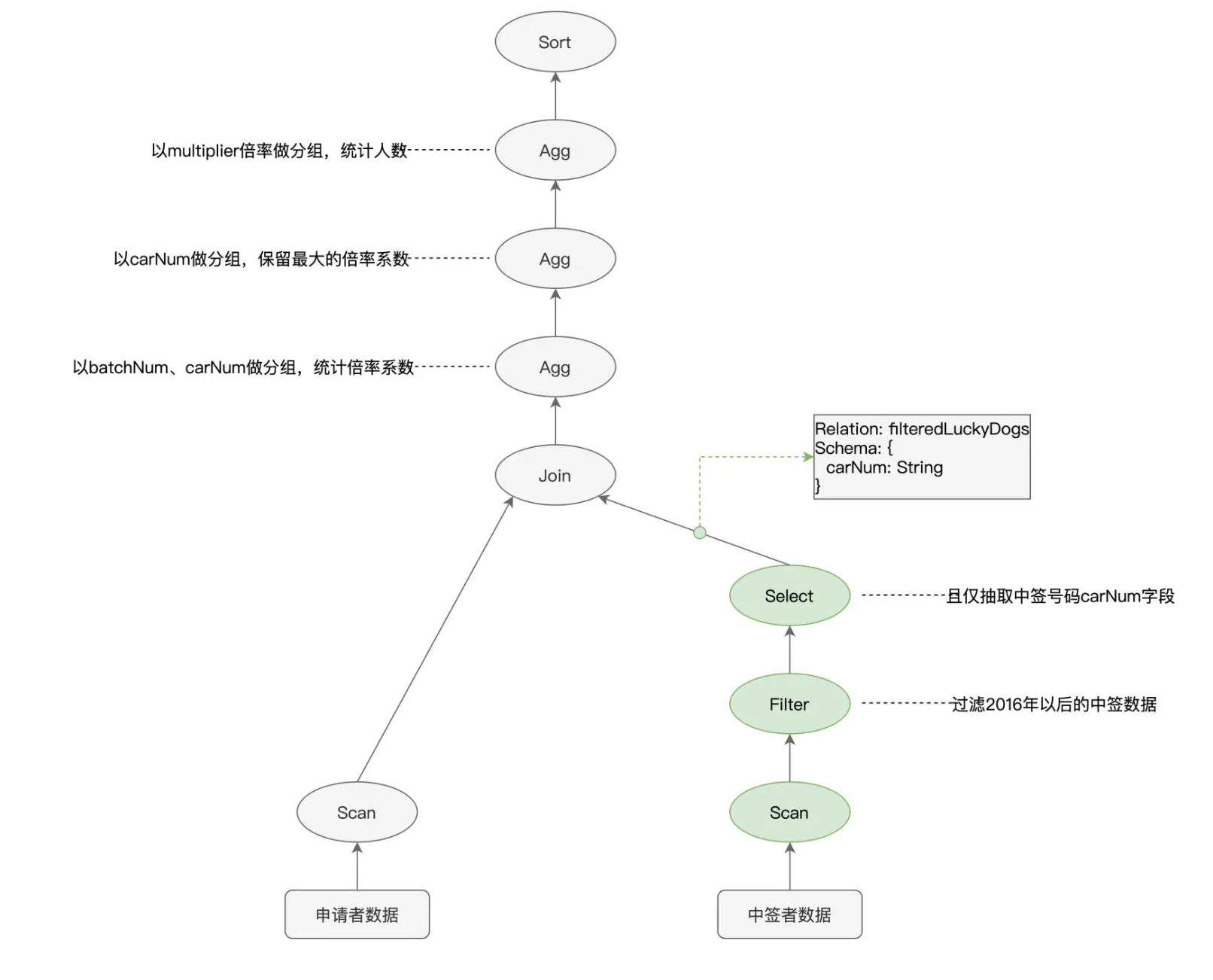
我们以图中绿色的节点为例,Scan 用于全量扫描并读取中签者数据,Filter 则用来过滤出摇号批次大于等于“201601”的数据,Select 节点的作用则是抽取数据中的“carNum”字段。我们的源文件是以 Parquet 格式进行存储的,而 Parquet 格式在文件层面支持“谓词下推”(Predicates Pushdown)和“列剪枝”(Columns Pruning)这两项特性。谓词下推指的是,利用像“batchNum >= 201601”这样的过滤条件,在扫描文件的过程中,只读取那些满足条件的数据文件。又因为 Parquet 格式属于列存(Columns Store)数据结构,因此 Spark 只需读取字段名为“carNum”的数据文件,而“剪掉”读取其他数据文件的过程。

以中签数据为例,在谓词下推和列剪枝的帮助下,Spark Core 只需要扫描图中绿色的文件部分。显然,这两项优化,都可以有效帮助 Spark Core 大幅削减数据扫描量、降低磁盘 I/O 消耗,从而显著提升数据的读取效率。因此,如果能把 3 个绿色节点的执行顺序,从“Scan > Filter > Select”调整为“Filter > Select > Scan”,那么,相比原始的执行计划,调整后的执行计划能给 Spark Core 带来更好的执行性能。
像谓词下推、列剪枝这样的特性,都被称为启发式的规则或策略。而 Catalyst 优化器的核心职责之一,就是在逻辑优化阶段,基于启发式的规则和策略调整、优化执行计划,为物理优化阶段提升性能奠定基础。
除了逻辑阶段的优化,Catalyst 在物理优化阶段还会进一步优化执行计划。与逻辑阶段主要依赖先验的启发式经验不同,物理阶段的优化,主要依赖各式各样的统计信息,如数据表尺寸、是否启用数据缓存、Shuffle 中间文件,等等。换句话说,逻辑优化更多的是一种“经验主义”,而物理优化则是“用数据说话”。在物理优化阶段,Catalyst 优化器需要结合 applyNumbersDF 与 filteredLuckyDogs 这两张表的存储大小,来决定是采用运行稳定但性能略差的 Shuffle Sort Merge Join,还是采用执行性能更佳的 Broadcast Hash Join。
Tungsten
Tungsten 主要是在数据结构和执行代码这两个方面,做进一步的优化。数据结构优化指的是 Unsafe Row 的设计与实现,执行代码优化则指的是全阶段代码生成(WSCG,Whole Stage Code Generation)。
对于 DataFrame 中的每一条数据记录,Spark SQL 默认采用 org.apache.spark.sql.Row 对象来进行封装和存储。我们知道,使用 Java Object 来存储数据会引入大量额外的存储开销。为此,Tungsten 设计并实现了一种叫做 Unsafe Row 的二进制数据结构。Unsafe Row 本质上是字节数组,它以极其紧凑的格式来存储 DataFrame 的每一条数据记录,大幅削减存储开销,从而提升数据的存储与访问效率。
接下来,我们再来说说 WSCG:全阶段代码生成。所谓全阶段,其实就是我们在调度系统中学过的 Stage。以图中的执行计划为例,标记为绿色的 3 个节点,在任务调度的时候,会被划分到同一个 Stage。代码生成,指的是 Tungsten 在运行时把算子之间的“链式调用”捏合为一份代码。