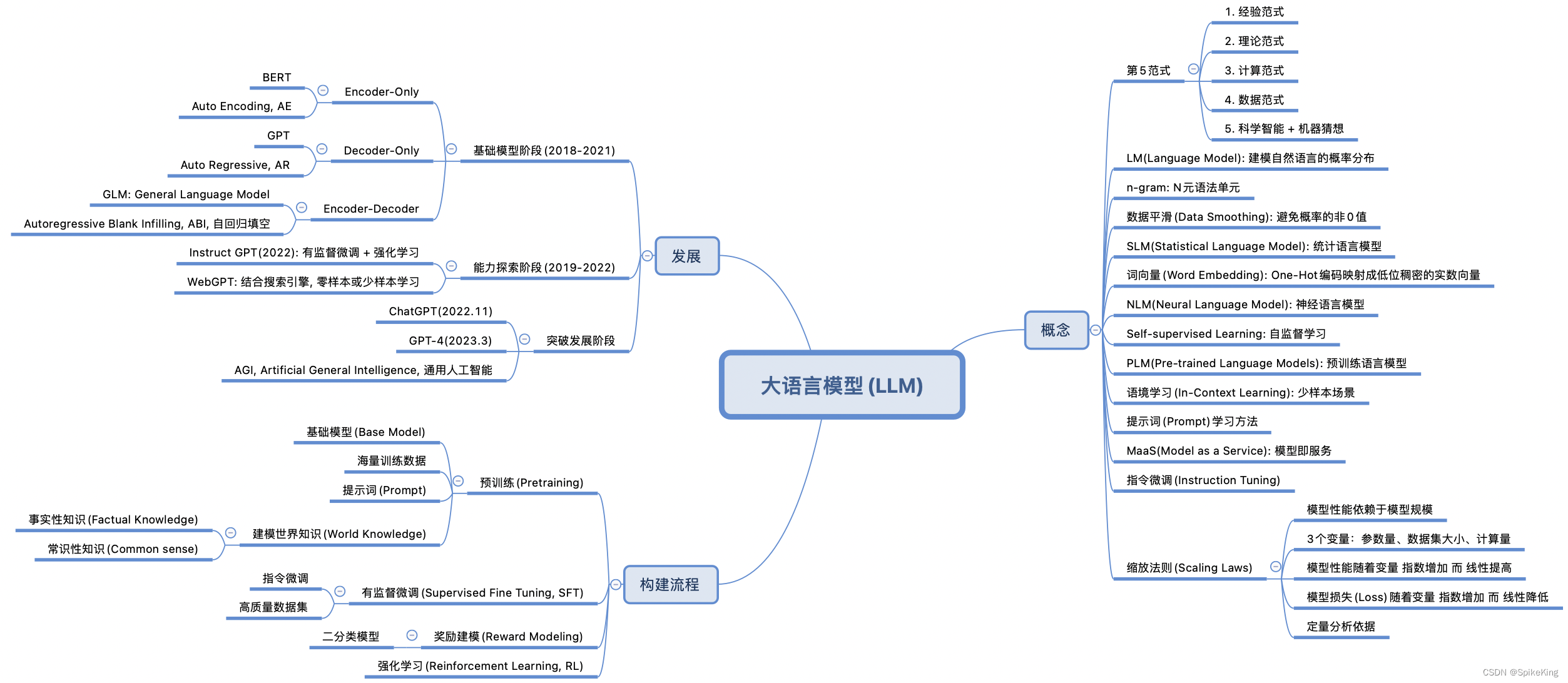
大模型知识点总结
1. 基础概念
1.1 大模型定义
大模型(Large Model)通常指参数量级达到数亿甚至数千亿的深度学习模型。这些模型通常基于Transformer架构,如GPT、BERT等。
1.2 常见大模型
- GPT系列(Generative Pre-trained Transformer)
- BERT(Bidirectional Encoder Representations from Transformers)
- T5(Text-to-Text Transfer Transformer)
- RoBERTa(Robustly Optimized BERT Pretraining Approach)
2. 模型架构
2.1 Transformer
Transformer是一种基于注意力机制的架构,主要由编码器(Encoder)和解码器(Decoder)组成。其主要特点包括:
- 自注意力机制(Self-Attention)
- 多头注意力机制(Multi-Head Attention)
- 残差连接(Residual Connections)
- 前馈神经网络(Feed-Forward Neural Networks)
2.2 编码器-解码器模型
典型的编码器-解码器模型结构如下:
输入序列 -> 编码器 -> 编码表示 -> 解码器 -> 输出序列
2.3 GPT模型
GPT模型是一个仅使用解码器部分的Transformer架构,其特点包括:
- 自回归生成模型(Autoregressive Model)
- 使用前面的文本生成后续文本
- 预训练和微调阶段
- 预训练:在大规模无监督文本数据上进行训练
- 微调:在特定任务的数据集上进一步训练
- 适用于文本生成任务
- 如对话系统、文本续写等
2.4 BERT模型
BERT模型是一个仅使用编码器部分的Transformer架构,其特点包括:
- 双向编码(Bidirectional Encoding)
- 同时考虑上下文信息
- 预训练任务
- 掩码语言模型(Masked Language Model, MLM)
- 随机掩盖输入文本中的部分单词,让模型预测这些单词
- 下一个句子预测(Next Sentence Prediction, NSP)
- 预测两个句子是否连续
- 掩码语言模型(Masked Language Model, MLM)
- 适用于自然语言理解任务
- 如问答系统、文本分类等
3. 训练与微调
3.1 预训练
预训练是指在大规模无标签数据集上进行训练,以学习通用的语言表示。
- 目标是使模型能够理解语言结构和上下文关系。
- 通常在大规模语料库(如Wikipedia、BooksCorpus)上进行。
3.2 微调
微调是在特定任务的数据集上进行训练,使预训练模型适应具体任务。
- 常见的微调任务包括文本分类、命名实体识别、机器翻译等。
- 使用有标签的数据进行训练,以优化特定任务的性能。
3.3 转移学习
转移学习是一种将预训练模型的知识迁移到新任务中的方法。
- 通过预训练和微调,提高在小数据集上的表现。
- 例如:将BERT预训练模型应用于情感分析任务。
4. 优化技术
4.1 混合精度训练
混合精度训练使用半精度(FP16)和单精度(FP32)混合计算,以加速训练过程并减少显存使用。
- 优点:提高训练速度,降低显存占用。
- 实现方法:使用NVIDIA的Apex工具或TensorFlow的mixed precision API。
4.2 模型压缩
模型压缩包括量化、剪枝和知识蒸馏等技术,以减少模型大小并提高推理速度。
- 量化:将模型权重从浮点数转换为低精度数(如INT8)。
- 剪枝:移除不重要的权重和神经元。
- 知识蒸馏:使用大型预训练模型指导小模型的训练。
4.3 并行训练
并行训练包括数据并行和模型并行,以利用多GPU/TPU进行高效训练。
- 数据并行:将数据划分成多个批次,并行处理。
- 模型并行:将模型划分成多个部分,并行处理。
5. 应用与挑战
5.1 应用
大模型在自然语言处理领域有广泛应用,包括:
- 文本生成(如对话系统、文本续写)
- 机器翻译(如Google Translate)
- 对话系统(如智能客服、聊天机器人)
- 情感分析(如社交媒体情感分析)
5.2 挑战
- 计算资源需求高:训练和推理过程需要大量计算资源。
- 模型解释性差:大模型的内部工作机制不易解释。
- 数据隐私与安全问题:训练数据的隐私和安全问题。
- 能耗与环境影响:训练大模型需要大量电力资源,可能对环境产生影响。
6. 未来发展
6.1 更大规模模型
研究人员正在探索具有数万亿参数的大模型,以期进一步提升模型性能。
- 例如:OpenAI的GPT-4、谷歌的PaLM等。
6.2 多模态模型
多模态模型融合了文本、图像、音频等多种数据模态,能够处理更加复杂的任务。
- 例如:OpenAI的CLIP模型、DALL-E模型。
6.3 更高效的训练方法
新的优化算法和训练方法,如自监督学习、少样本学习等,将进一步提升大模型的训练效率和泛化能力。
- 自监督学习:无需标签数据,通过构造预训练任务进行训练。
- 少样本学习:在极少量数据下,训练出具有良好性能的模型。