小样本学习:解锁微调LLM的潜力
引言
在人工智能领域,尤其是自然语言处理(NLP),大型语言模型(LLM)已成为推动技术进步的关键力量。然而,传统的模型训练和微调往往依赖于海量标注数据,这不仅成本高昂,而且在许多现实场景中难以实现。小样本学习(Few-Shot Learning)作为一种前沿技术,旨在通过极少量的样本来高效训练模型,尤其在微调LLM时展现出巨大潜力。本文将深入探讨小样本学习的概念、原理及其在微调LLM中的应用,通过具体实例对比,揭示其独特优势和挑战。
一、小样本学习概览
1.1 定义
小样本学习,顾名思义,是指在仅有少数几个样本(通常是几个到几十个)的情况下,使机器学习模型能够快速学习新任务或适应新领域的方法。与传统的监督学习相比,小样本学习极大地降低了对大量标注数据的需求,使得模型在面对数据稀缺的情况时仍能有效工作。
1.2 原理
小样本学习的核心在于模型的泛化能力和迁移学习。泛化能力使模型能够从有限的样例中提取关键特征,而迁移学习则利用模型在先前任务中学到的知识,加速新任务的学习过程。这种能力对于LLM尤为重要,因为它们通常在大规模通用语料上预训练,拥有丰富的语言知识,只需少量特定领域的样本来微调,就能快速适应新任务。
二、小样本学习在微调LLM中的应用
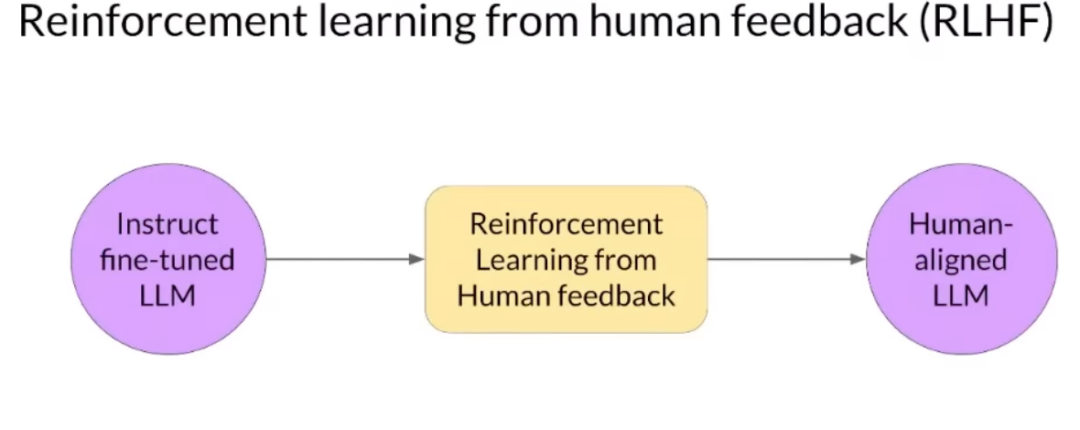
2.1 微调概念
微调是指在预训练模型的基础上,使用特定任务的小量数据集进行进一步训练,以适应该