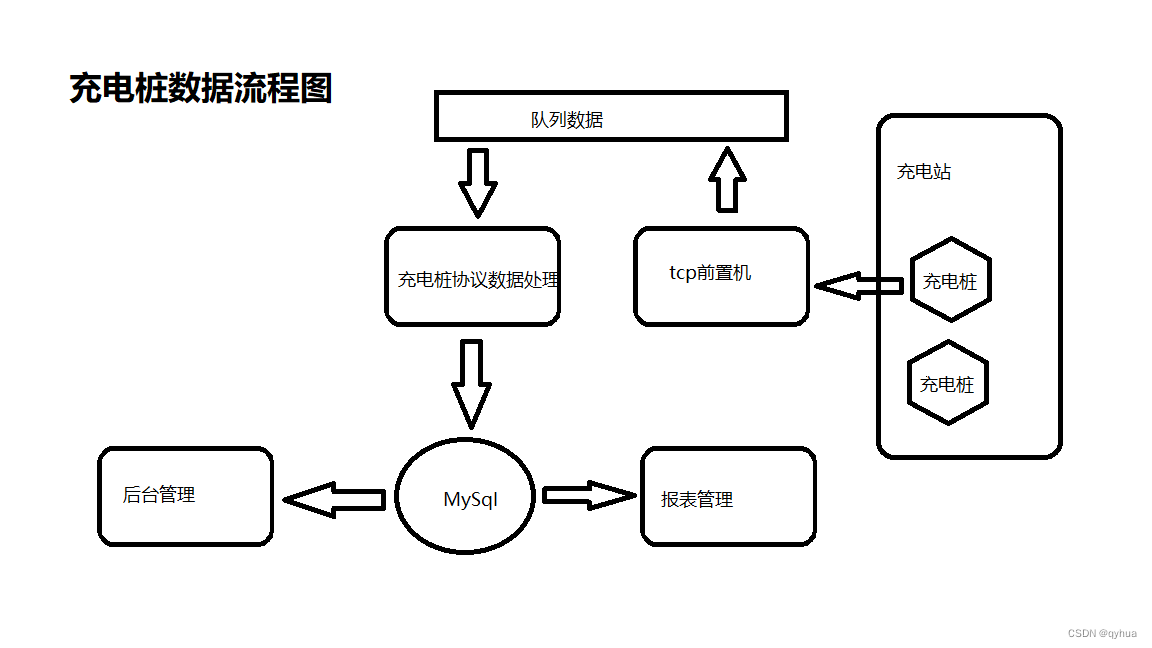
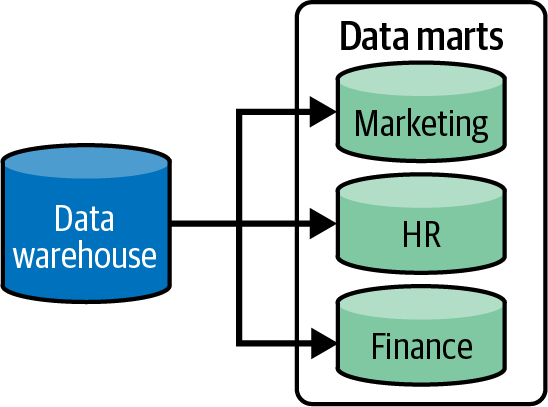
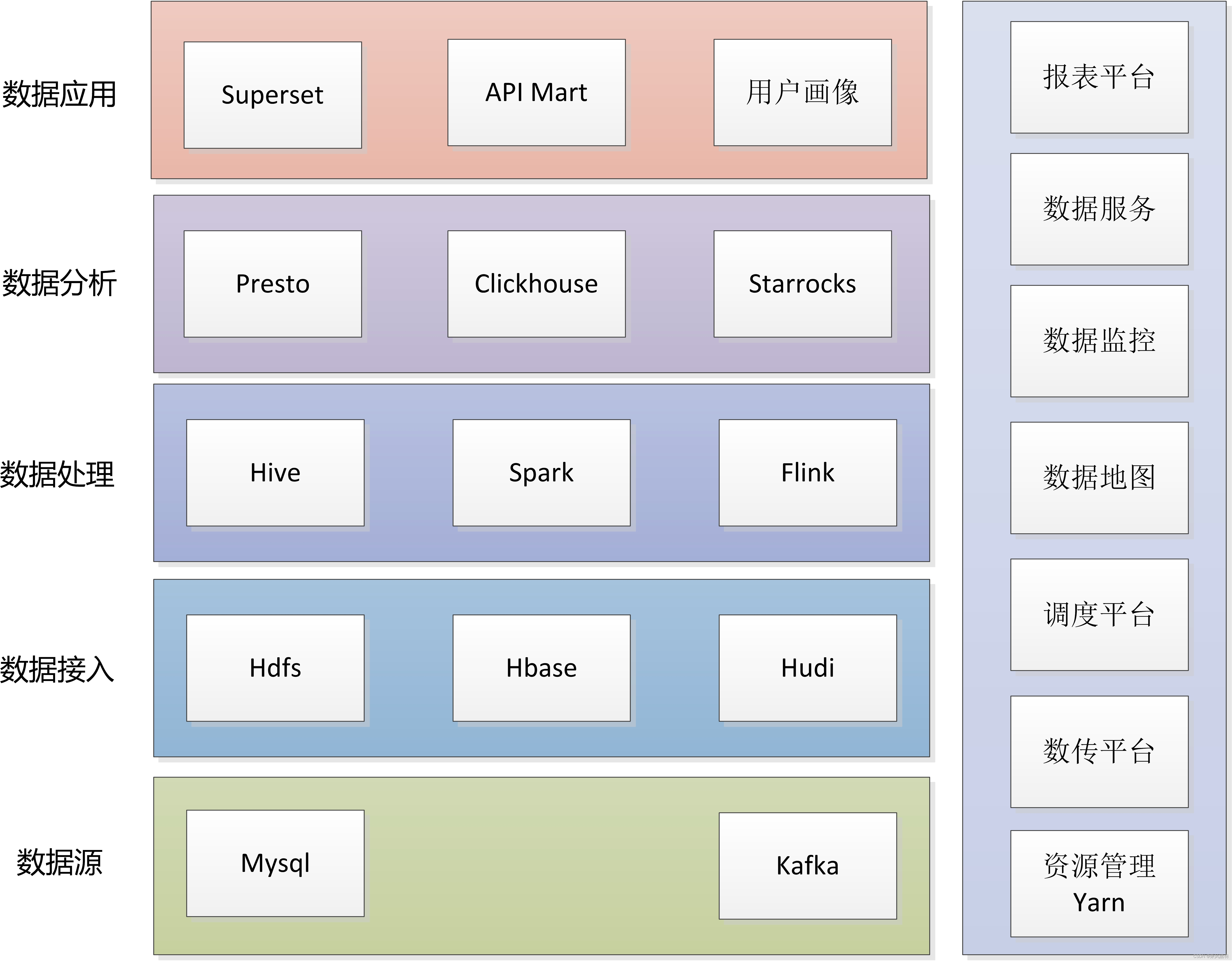
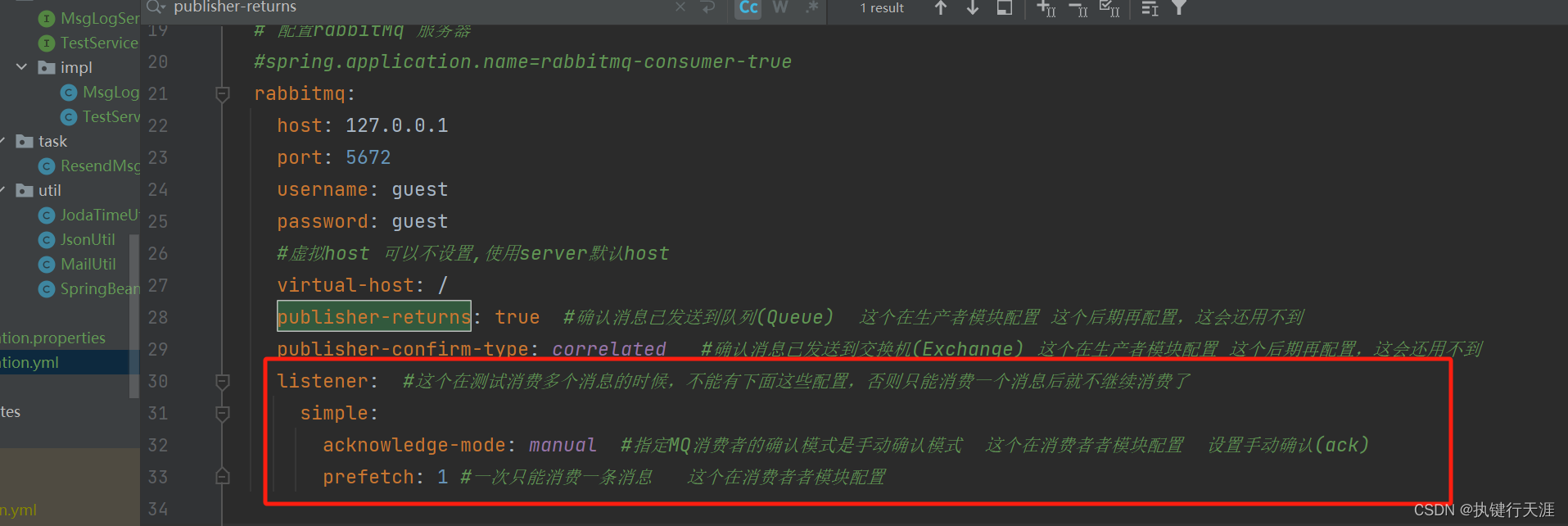
Storm之父Nathan Marz在《大数据系统构建:可扩展实时数据系统构建原理与最佳实践》一书中,提出了他认为大数据系统应该具有的属性。
1.鲁棒性和容错性(Robust and Fault-tolerant)
对大规模分布式系统来说,机器是不可靠的,可能会宕机,但是系统需要是健壮、行为正确的,即使是遇到机器错误。除了机器错误,人更可能会犯错误。在软件开发中难免会有一些Bug,系统必须对有Bug的程序写入的错误数据有足够的适应能力,所以比机器容错性更加重要的容错性是人为操作容错性。对于大规模的分布式系统来说,人和机器的错误每天都可能会发生,如何应对人和机器的错误,让系统能够从错误中快速恢复尤其重要。
2.低延迟读取和更新能力(Low Latency Reads and Updates)
许多应用程序要求数据系统拥有几毫秒到几百毫秒的低延迟读取和更新能力。有的应用程序允许几个小时的延迟更新,但是只要有低延迟读取与更新的需求,系统就应该在保证鲁棒性的前提下实现。
3.横向扩容(Scalable)
当数据量或负荷增大时,可扩展性的系统通过增加更多的机器资源来维持性能。也就是常说的系统需要线性可扩展,通常采用scale out(通过增加机器的个数)而不是scale up(通过增强机器的性能)。
4.通用性(General)
系统需要支持绝大多数应用程序,包括金融领域、社交网络、电子商务数据分析等。
5.延展性(Extensible)
在新的功能需求出现时,系统需要能够将新功能添加到系统中。同时,系统的大规模迁移能力是设计者需要考虑的因素之一,这也是可延展性的体现。
6.即席查询能力(Allows Ad Hoc Queres)
用户在使用系统时,应当可以按照自己的要求进行即席查询(Ad Hoc)。这使用户可以通过系统多样化数据处理,产生更高的应用价值。
7.最少维护能力(Minimal Maintenance)
系统需要在大多数时间下保持平稳运行。使用机制简单的组件和算法让系统底层拥有低复杂度,是减少系统维护次数的重要途径。Marz认为大数据系统设计不能再基于传统架构的增量更新设计,要通过减少复杂性以减少发生错误的几率、避免繁重操作。
8.可调试性(Debuggable)
系统在运行中产生的每一个值,需要有可用途径进行追踪,并且要能够明确这些值是如何产生的。