前言
损失函数(Loss Function):是定义在单个样本上的,是指一个样本的误差,度量模型一次预测的好坏。
代价函数(Cost Function)=成本函数=经验风险:是定义在整个训练集上的,是所有样本误差的平均,也就是所有损失函数值的平均,度量平均意义下模型预测的好坏。
目标函数(Object Function)=结构风险=经验风险+正则化项=代价函数+正则化项:是指最终需要优化的函数,一般指的是结构风险。正则化项(regularizer)=惩罚项(penalty term)。
损失函数类型
平方损失函数(Quadratic Loss Function)又称均方误差(Mean Squared Error, MSE)
一种常用的回归损失函数。它衡量的是模型预测值与真实值之差的平方的平均值。平方损失函数对于大的误差给予了更大的惩罚,这使得它成为许多回归任务中首选的损失函数之一。
平方损失函数的公式(MSE):

import torch
# 创建一个包含从 0.0 到 4.0(包括0.0和4.0)的浮点数的一维张量 x
x = torch.arange(5.0) # 注意这里的 5.0,它确保了 x 是浮点类型
# 创建一个与 x 形状相同但所有元素都是 1.0 的浮点类型张量 Y
Y = torch.ones_like(x, dtype=torch.float32) # 显式指定 dtype 为 torch.float32
# 创建一个 MSELoss 的实例
MSE = torch.nn.MSELoss()
# 计算 x 和 Y 之间的均方误差,并将结果存储在变量 a 中
a = MSE(x, Y)
# 打印结果
print(a) # 输出:tensor(3.),表示 x 和 Y 之间的均方误差
print(x) # 输出:tensor([0., 1., 2., 3., 4.]),x 的值
print(Y) # 输出:tensor([1., 1., 1., 1., 1.]),Y 的值
注意
- 平方损失函数对异常值(outliers)非常敏感,因为异常值会导致误差的平方变得非常大,从而影响整个损失函数的值。
- 在某些情况下,如果预测值与实际值的差距非常大,使用平方损失函数可能会导致梯度爆炸,从而使得模型的训练变得不稳定。对于这类问题,可能需要考虑使用其他的损失函数,如绝对误差损失(L1损失)等。
L1范数损失(L1 Loss)也被称为最小绝对偏差(LAD)、平均绝对值误差(MAE)
L1 Loss损失函数的公式(MAE):

优点:
- 稳定性:L1 Loss对于任何输入值都有着稳定的梯度,即其梯度为常数(±1),这避免了梯度爆炸的问题,使得模型训练过程更加稳定。
- 鲁棒性:L1 Loss对离群点(outliers)的惩罚是固定的,不会因离群点而产生过大的损失值,从而提高了模型对异常值的鲁棒性。
- 稀疏性:L1 Loss在优化过程中倾向于产生稀疏解,即使得模型中的许多权重接近于0,这有助于特征选择,简化模型,并提高模型的泛化能力。
缺点:
- 不可导性:在0点处,L1Loss的梯度未定义(或者说是不连续的),这可能导致在优化过程中遇到一些困难,尤其是在使用梯度下降等基于梯度的优化算法时。
- 收敛性:由于L1 Loss的梯度为常数,当预测值接近真实值时,梯度仍然较大,这可能导致模型在最优解附近震荡,难以精确收敛。
使用场景
L1 Loss通常用于回归任务,尤其是在需要模型的权重具有稀疏性的场景下。然而,由于其在0点处的不可导性,L1 Loss在神经网络等复杂模型中的直接使用较少。相反,Smooth L1 Loss(平滑L1损失)作为L1 Loss和L2 Loss的结合,既保留了L1 Loss的鲁棒性,又解决了其在0点处不可导的问题,因此在目标检测等任务中得到了广泛应用。
# x = tensor([0., 1., 2., 3., 4.])
# y = tensor([1., 1., 1., 1., 1.])
# 计算差的绝对值
abs_diff = torch.abs(x - y)
# 输出: tensor([1., 0., 1., 2., 3.])
# 计算L1损失(平均绝对误差)
L1loss = torch.nn.L1Loss()
a = L1loss(x, y)
# 或者直接计算平均值,不使用torch.nn.L1Loss()
# a = torch.mean(abs_diff)
# 输出L1损失
print(a) # 应该是 (1 + 0 + 1 + 2 + 3) / 5 = 1.4
SmoothL1Loss,平滑L1损失函数
是深度学习中常用的一种损失函数,尤其在处理回归问题时表现出色。它是L1损失和L2损失的结合体,旨在减少对异常值的敏感性,并在优化过程中提供更加稳定的梯度。

特性与优势
- 结合L1和L2的优点:当误差较小时(∣x∣<β),SmoothL1Loss的计算方式类似于L2损失(平方误差),这使得它在原点附近更加平滑,有助于模型的快速收敛。当误差较大时(∣x∣≥β),SmoothL1Loss的计算方式则类似于L1损失(绝对误差),这有助于减少离群点对损失函数的影响,使模型更加鲁棒。
- 对异常值不敏感:相比于L2损失,SmoothL1Loss在误差较大时不会过度放大损失值,从而避免了梯度爆炸的问题。这对于包含异常值或噪声的数据集尤其有用。
- 稳定的梯度:SmoothL1Loss在误差的整个范围内都提供了相对稳定的梯度,这有助于模型的稳定训练。
应用场景
SmoothL1Loss在目标检测、物体跟踪、姿态估计等需要精确回归的任务中得到了广泛应用。特别是在目标检测的Bounding Box回归中,SmoothL1Loss能够有效地计算预测框与真实框之间的误差,并帮助模型优化预测结果。
在PyTorch的torch.nn.SmoothL1Loss类中,reduction和beta是两个重要的参数,它们分别用于控制损失值的计算和平滑转换点的设置。
reduction参数指定了应用于输出损失值的缩减方法。它有三个可选值:‘none’、‘mean’和’sum’。
- 当reduction='mean’时,函数会计算所有元素损失的平均值作为最终的损失值。这是回归任务中常用的做法,因为它将损失值标准化为单个标量,便于比较和反向传播。
- 如果设置为’none’,则函数将返回一个与输入形状相同的损失张量,不进行任何缩减。
- 如果设置为’sum’,则函数会计算所有元素损失的总和作为最终的损失值。
beta参数是一个超参数,用于定义SmoothL1Loss函数中的平滑转换点。在SmoothL1Loss的公式中,当误差的绝对值小于beta时,损失函数采用L2损失(平方误差)的形式;当误差的绝对值大于或等于beta时,损失函数采用L1损失(绝对误差减去0.5*beta)的形式。
- beta=1.0是PyTorch中SmoothL1Loss的默认值。这个值的选择是基于经验和实践的,旨在在L1损失和L2损失之间找到一个平衡点,以便在大多数情况下都能获得良好的性能。
- 调整beta的值可以改变损失函数对误差的敏感度。较小的beta值会使损失函数在误差较小时更加接近L2损失,从而在原点附近更加平滑;较大的beta值则会使损失函数更早地过渡到L1损失的形式,从而减少对大误差的惩罚。
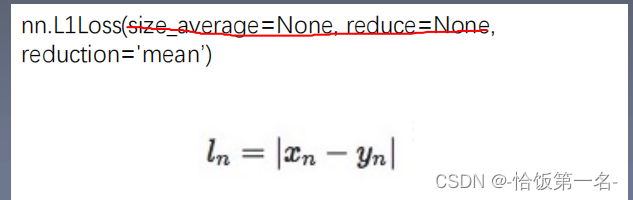


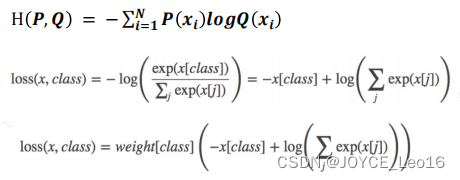
![[<span style='color:red;'>pytorch</span>] 8.<span style='color:red;'>损失</span><span style='color:red;'>函数</span>和反向传播](https://img-blog.csdnimg.cn/direct/68805a52e04447c6961be64c0897c3d5.png)