一,项目简介
LLama-Factory,大模型训练框架,支持多种模型,多种训练方式,
项目github地址:link
项目特色
- 多种模型:LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Yi、Gemma、Baichuan、ChatGLM、Phi 等等。
- 集成方法:(增量)预训练、(多模态)指令监督微调、奖励模型训练、PPO 训练、DPO 训练、KTO 训练、ORPO 训练等等。
- 多种精度:16 比特全参数微调、冻结微调、LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8/HQQ/EETQ 的 2/3/4/5/6/8 比特 QLoRA 微调。
- 先进算法:GaLore、BAdam、DoRA、LongLoRA、LLaMA Pro、Mixture-of-Depths、LoRA+、LoftQ、PiSSA 和 Agent 微调。
- 实用技巧:FlashAttention-2、Unsloth、RoPE scaling、NEFTune 和 rsLoRA。
- 实验监控:LlamaBoard、TensorBoard、Wandb、MLflow 等等。
- 极速推理:基于 vLLM 的 OpenAI 风格 API、浏览器界面和命令行接口。
二, 支持训练模型以及地址
或者去魔搭社区,是真的快
| 模型名 | 模型大小 | Template |
|---|---|---|
| Baichuan 2 | 7B/13B | baichuan2 |
| BLOOM/BLOOMZ | 560M/1.1B/1.7B/3B/7.1B/176B | - |
| ChatGLM3 | 6B | chatglm3 |
| Command R | 35B/104B | cohere |
| DeepSeek (Code/MoE) | 7B/16B/67B/236B | deepseek |
| Falcon | 7B/11B/40B/180B | falcon |
| Gemma/Gemma 2/CodeGemma | 2B/7B/9B/27B | gemma |
| GLM-4 | 9B | glm4 |
| InternLM2 | 7B/20B | intern2 |
| Llama | 7B/13B/33B/65B | - |
| Llama 2 | 7B/13B/70B | llama2 |
| Llama 3 | 8B/70B | llama3 |
| LLaVA-1.5 | 7B/13B | vicuna |
| Mistral/Mixtral | 7B/8x7B/8x22B | mistral |
| OLMo | 1B/7B | - |
| PaliGemma | 3B | gemma |
| Phi-1.5/Phi-2 | 1.3B/2.7B | - |
| Phi-3 | 4B/7B/14B | phi |
| Qwen/Qwen1.5/Qwen2 (Code/MoE) | 0.5B/1.5B/4B/7B/14B/32B/72B/110B | qwen |
| StarCoder 2 | 3B/7B/15B | - |
| XVERSE | 7B/13B/65B | xverse |
| Yi/Yi-1.5 | 6B/9B/34B | yi |
| Yi-VL | 6B/34B | yi_vl |
| Yuan 2 | 2B/51B/102B | yuan |
三,硬件依赖
* 估算值
| 方法 | 精度 | 7B | 13B | 30B | 70B | 110B | 8x7B | 8x22B |
|---|---|---|---|---|---|---|---|---|
| Full | AMP | 120GB | 240GB | 600GB | 1200GB | 2000GB | 900GB | 2400GB |
| Full | 16 | 60GB | 120GB | 300GB | 600GB | 900GB | 400GB | 1200GB |
| Freeze | 16 | 20GB | 40GB | 80GB | 200GB | 360GB | 160GB | 400GB |
| LoRA/GaLore/BAdam | 16 | 16GB | 32GB | 64GB | 160GB | 240GB | 120GB | 320GB |
| QLoRA | 8 | 10GB | 20GB | 40GB | 80GB | 140GB | 60GB | 160GB |
| QLoRA | 4 | 6GB | 12GB | 24GB | 48GB | 72GB | 30GB | 96GB |
| QLoRA | 2 | 4GB | 8GB | 16GB | 24GB | 48GB | 18GB | 48GB |
四,安装环境和训练实战
4.1 环境安装
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
4.2 构建自己的数据集
[{
"input": "2023年3月16日14时55分许,鄂温克族自治旗伊敏河镇发生一起一般事故,造成一人死亡,直接经济损失人民币200万元。",
"output": "任务1:“是”,原文中提到了负面新闻,这些词汇与负面新闻相关。任务2:“不是”,由于原文没有提到了负面情绪,这和没有关系,因此不是。",
"instruction": "你是一个舆情分析专家,擅长分析一段文字的舆情类型。现在请你判断下述语句,任务1,是否与负面新闻,你的回答 只能从是或不是选择一个,任务2,是否与负面情绪,你的回答 只能从是或不是中选择一个。例如:待判断语句:今天合肥的天气真好。你的回复:1,不是,2,不是。现在待判断语句为:{}"
}]
解析:在指令监督微调时,instruction 列对应的内容会与 input 列对应的内容拼接后作为人类指令,即人类指令为 instruction\ninput。而 output 列对应的内容为模型回答。
如果指定,system 列对应的内容将被作为系统提示词。
[
{
"instruction": "人类指令,就是你要问模型的pormopt(必填)",
"input": "人类输入,输入的句子(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]
注册自己的数据集
将自己的数据集放到data目录下
vim data/dataset_info.json
### 添加一行内容
"my_train_data": {
"file_name": "my_train_data.json"
},
记着名字,一会训练要指定数据集名称
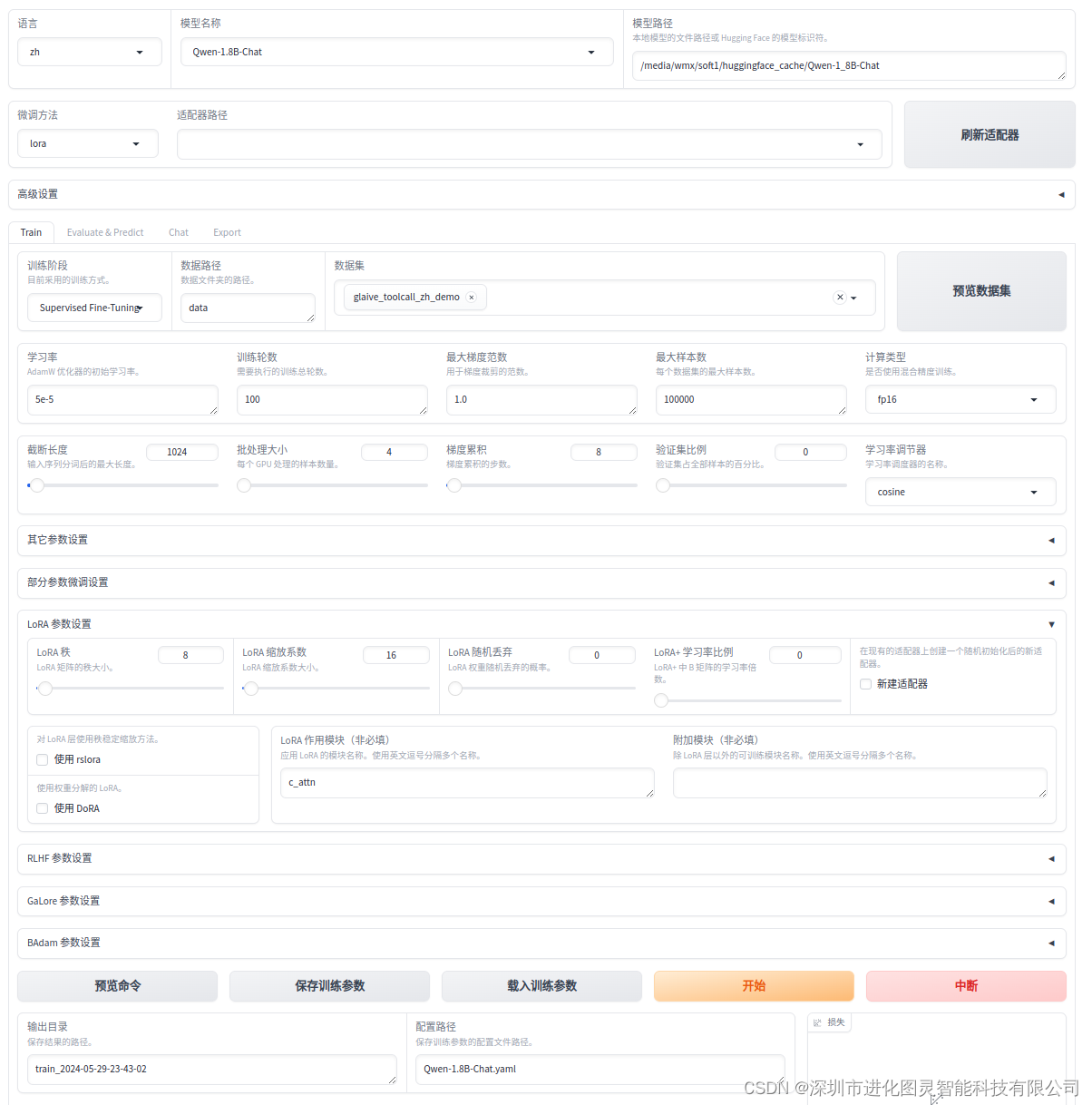
五,修改对应的yaml文件
### model
model_name_or_path:原始模型地址
### method
stage: sft
do_train: true
finetuning_type: lora
lora_target: all
### dataset
dataset: my_train,alpaca_en_demo(混合训练的样本集,防止知识遗忘,可以不用)
template: qwen
cutoff_len: 4096
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16
### output
output_dir: saves/qwen/lora/sft
logging_steps: 10
save_steps: 100
plot_loss: true
overwrite_output_dir: true
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
### eval
val_size: 0.1
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 500
开始训练
lora 指令微调
llamafactory-cli train examples/train_lora/mytrain_lora_sft.yaml
命令行
CUDA_VISIBLE_DEVICES=0,1,2,3 python src/train_bash.py --stage sft --do_train --model_name_or_path /app/model --dataset my_train_data --finetuning_type lora --lora_target q_proj,v_proj --output_dir /app/output --overwrite_cache --per_device_train_batch_size 1 --gradient_accumulation_steps 1 --lr_scheduler_type cosine --logging_steps 10 --save_steps 1000 --learning_rate 5e-5 --num_train_epochs 3.0 --template yi
合并模型
llamafactory-cli export examples/merge_lora/my_lora_sft.yaml
### vi examples\merge_lora\llama3_lora_sft.yaml改成自己路径就行了
### model
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
adapter_name_or_path: saves/llama3-8b/lora/sft
template: llama3
finetuning_type: lora
### export
export_dir: models/llama3_lora_sft
export_size: 2
export_device: cpu
export_legacy_format: false
或者
CUDA_VISBLE_DEVICES=0 python /app/src/export_model.py --model_name_or_path /app/model/ --adapter_name_or_path /app/output/checkpoint-3000/ --template default --finetuning_type lora --export_dir /app/lora_resul
t/20240422_1519 --export_size 2 --export_legacy_format False
模型推理
vi inference/yam.py,修改对应路径
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
adapter_name_or_path: saves/llama3-8b/lora/sft
template: llama3
finetuning_type: lora
llamafactory-cli chat examples/inference/llama3_lora_sft.yaml
或者
·```
python /app/src/cli_demo.py --model_name_or_path /app/lora_result/20240422_1519/ --template=qwen
未完待续·....



![[<span style='color:red;'>大</span><span style='color:red;'>模型</span>]<span style='color:red;'>Qwen</span>-<span style='color:red;'>7</span><span style='color:red;'>B</span>-Chat WebDemo](https://img-blog.csdnimg.cn/direct/568fd79bf1fe4e10ba83ff9bcf545de9.png#pic_center)
















![[21] Opencv_CUDA应用之使用Haar级联的对象检测](https://img-blog.csdnimg.cn/direct/71456f2d3221469386636223c85a4d45.png)






![[未公开0day]宏景HCM人力资源信息管理系统存在前台RCE](https://img-blog.csdnimg.cn/direct/8a3108d8ea124ea39068fa203ffd4ff9.png)