文章目录
- 1. 【CoRL 2023】SayPlan: Grounding Large Language Models using 3D Scene Graphs for Scalable Robot Task Planning
- 2. ShapeLLM: Universal 3D Object Understanding for Embodied Interaction
- 3. 【2024-05】Grounded 3D-LLM with Referent Tokens
1. 【CoRL 2023】SayPlan: Grounding Large Language Models using 3D Scene Graphs for Scalable Robot Task Planning
动机
大型语言模型(LLMs)在开发多样化任务的通用规划代理方面展现出了令人印象深刻的成果。然而,将这些计划具体化到广阔、多层和多房间的环境中,对机器人技术来说是一个重大挑战。
摘要和结论
1)利用3DSG的层次性质,允许LLMs通过语义搜索从完整图的较小、压缩表示中寻找与任务相关的子图;
2)通过集成经典路径规划器来缩短LLM的规划范围;
3)引入一个迭代重规划流程,利用场景图模拟器的反馈来细化初始计划,纠正不可行的动作,避免规划失败。
引言
我们提出了一种可扩展的方法,通过利用3D场景图(3DSG)研究的不断增长[11, 12, 13, 14, 15, 16],将基于LLM的任务规划器具体化到跨越多个房间和楼层的环境中。3DSG能够捕获环境的丰富拓扑和层次化的语义图表示,具有编码任务规划所需的必要信息的多功能性,包括对象状态、谓词、功能和属性,并使用自然语言——适合由LLM解析。我们可以利用这种图的JSON表示作为预训练LLM的输入,然而,为了确保对广阔场景的计划的可扩展性,我们提出了三个关键创新点。
- 首先,我们提出了一种机制,通过操作“压缩”的3DSG的节点,使LLM能够进行语义搜索,寻找与任务相关的子图G’,该子图仅通过展开和收缩API函数调用来暴露完整图G的最顶层,从而使其能够在越来越大规模的环境中进行规划。通过这样做,LLM在规划期间只关注相对较小、信息丰富的子图G’,而不会超出其令牌限制。
- 其次,由于在这样的环境中跨越任务计划的范围随着给定任务指令的复杂性和范围而增长,LLM产生幻觉或不可行动作序列的倾向也在增加[17, 18, 7]。我们通过首先放宽LLM生成计划的导航组件的需求来应对这一点,而是利用现有的最优路径规划器,如迪杰斯特拉算法[19],连接由LLM生成的高级节点。
- 最后,为了确保所提出计划的可行性,我们引入了一个迭代重规划流程,使用来自场景图模拟器的反馈来验证和细化初始计划,以纠正任何不可执行的动作,例如,在将物品放入冰箱之前忘记打开冰箱——从而避免由于不一致性、幻觉或违反环境所施加的物理约束和谓词而导致的规划失败。
模型框架
3.1 Problem Formulation
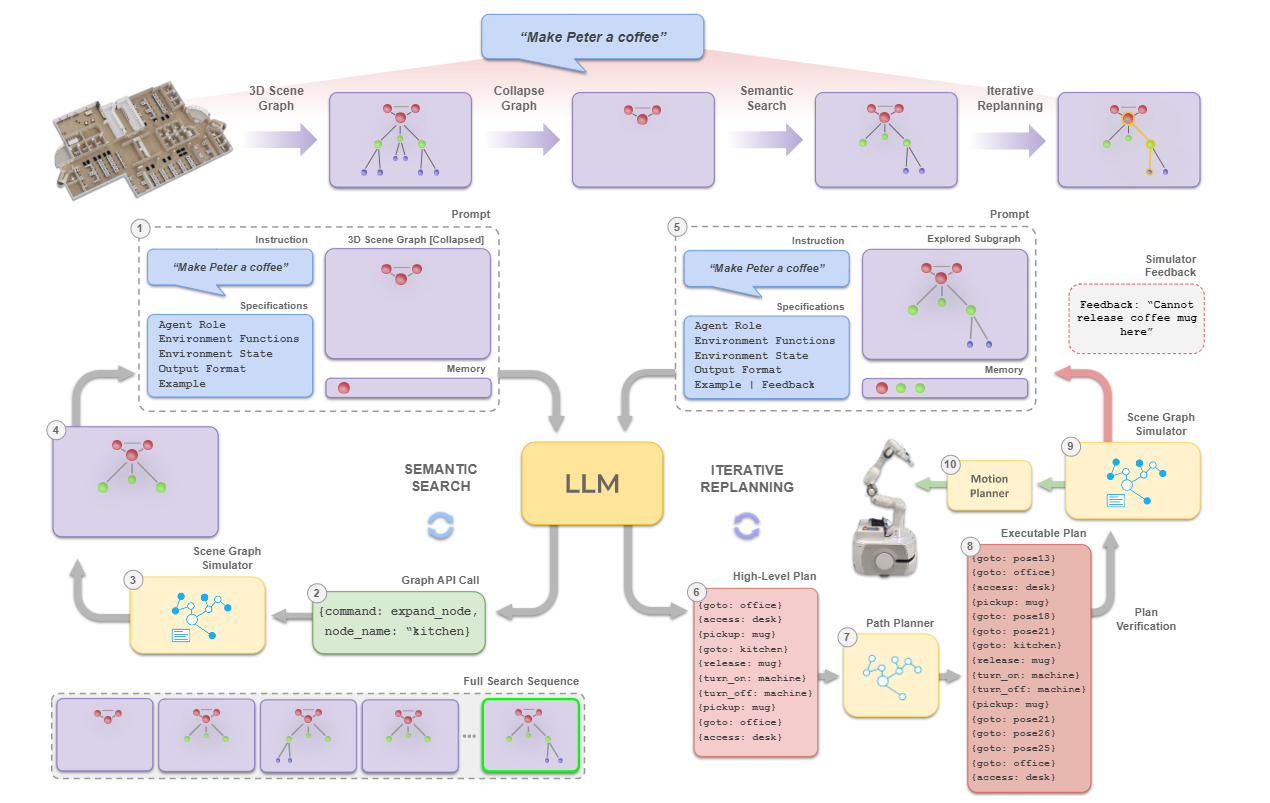
我们的目标是解决在大规模环境中基于自然语言指令的自主代理(如移动机械臂机器人)的长期任务规划的挑战。这要求机器人理解抽象和模糊的指令,理解场景并生成涉及移动机器人的导航和操控的任务计划。现有的方法缺乏在多层和多房间场景中进行推理的能力。我们专注于将大规模场景整合到基于语言模型(LLMs)的规划代理中,并解决可扩展性挑战。我们的目标是解决两个关键问题:1)在LLM的令牌限制内表示大规模场景;2)在生成大规模环境中的长期计划时减少LLM的幻觉和错误输出。
3.2 Preliminaries
3D场景图(3DSG)[11, 12, 14]最近作为机器人的可操作世界表示而出现[13, 15, 16, 39, 40, 41],它通过空间语义和对象关系在多个层次上对环境进行层次抽象,同时捕获环境中实体的相关状态、功能和谓词。

2. ShapeLLM: Universal 3D Object Understanding for Embodied Interaction
背景与动机:
3D形状理解是数字和物理世界中智能系统建模的基础能力,近年来在图形学、视觉、增强现实和具身机器人学等领域取得了巨大进展。为了被现实世界中的代理有效部署,需要满足几个关键标准,包括捕获足够的3D几何信息、模型应该具有与对象进行物理交互的基础时尚知识,以及需要一个通用接口作为信息编码和解码之间的桥梁。
摘要和结论
SHAPELLM 架构:SHAPELLM 结合了一个预训练的3D编码器和一个大型语言模型(LLM),用于有效的3D表示学习和理解。特别是,采用了 LLaMA 作为其 LLM,并提出了一个名为 RECON++ 的新型3D模型作为3D编码器。
RECON++ 编码器:RECON++ 通过集成多视图蒸馏来扩展 RECON,使用匈牙利算法进行自适应选择匹配进行优化,从而提高模型对3D形状信息的准确理解。
数据与训练:为了解决交互式3D理解中的“数据荒漠”问题,研究者使用 GPT-4V 在 Objaverse 数据集和 GAPartNet 上构建了约45K的指令跟随数据,并进行了监督微调。
3D MM-Vet 基准:为了评估模型在3D视觉语言任务中的表现,研究者开发了一个新的评估基准,包括59个不同的互联网3D对象和232个人工编写的问题-答案对。
引言
3D形状理解作为塑造智能系统在数字和物理世界中的基本能力,已经在图形学、视觉、增强现实和具身机器人学等众多领域取得了巨大进展。然而,要使这些系统在现实世界中得到有效部署,必须满足几个关键条件:首先,必须捕获足够的3D几何信息,以便进行精确的空间和结构处理;其次,模型应具备与对象进行物理交互的基础,这通常涉及到对对象的功能理解;最后,需要一个通用的接口作为信息编码和解码的桥梁,这有助于将高级指令转化为代理反应,例如对话响应和具身反馈。
最近在大型语言模型(LLMs)方面的进展展示了它们在任务中的基础知识和统一推理能力,这使得使用语言作为一个通用接口成为可能。然而,当将LLMs纳入3D对象理解时,尤其是依赖于精确几何的具身交互,仍然存在一些挑战——目前这方面的研究还相对不足。我们需要回答的问题是:什么构成了更好的3D表示,能够连接语言模型和交互导向的3D对象理解?
为了验证 SHAPELLM 的有效性,我们首先使用先进的 GPT-4V(ision) [115] 在处理后的 Objaverse 数据集 [29] 上构建了 ∼45K 指令跟踪数据,并使用来自 GAPartNet [47] 的 30K 体现部分理解数据进行监督微调。继 MM-Vet [179] 之后,我们进一步开发了一个名为 3D MM-Vet 的新型评估基准。该基准旨在评估视觉语言的核心能力,包括 3D 环境中的具体交互,从而促进未来的研究。3D MM-Vet 基准包括 59 个不同的 Internet1 3D 对象和 232 个人工编写的问答对。

模型框架

2.1 总体架构
本工作的主要目标是使用大型语言模型(LLM)作为通用接口来实现交互式3D理解。受到最近视觉理解工作[93]的启发,我们提出的SHAPELLM包括一个预训练的3D编码器和一个LLM,分别用于有效的3D表示学习和理解。
2.2 如何缓解交互式3D理解的数据荒漠问题?
大多数已发布的3D数据通常以3D对象-标题对的形式呈现,缺乏交互式风格。尽管一些并行的工作[62, 166]试图构建交互式3D理解数据集,但问题和答案(Q&A)主要基于注释的标题,通常提供有限的视角,没有足够的细节。此外,这些工作通常限于语义理解,没有考虑具身交互。为了解决这些限制,我们的工作使用GPT-4V(ision)[115]基于3D对象的多视图图像构建问题和答案对。为了数据多样性,我们明确引入了六个方面作为提示,如图3所示。以下,我们分别提供关于一般语义理解和具身对象理解的数据收集和构建的详细信息。

你可以基于这6个方面提出一些复杂的问题:对象的详细描述、一般视觉识别、知识、语言生成、空间关系和体现交互。

2.3. RECON++:扩展 3D 表示学习
现有的3D跨模态表示学习方法主要从单视图2D基础模型中提取高分辨率的对象特征,导致对形状理解的单一化。
为了解决上述限制,本文提出了RECON++,进行了多项改进。首先,多视图图像查询令牌协同理解不同视图中3D对象的语义信息,包括RGB图像和深度图。考虑到预训练数据在姿态方面的无序性,我们提出了一种基于二分图匹配的跨模态对齐方法,隐式学习3D对象的姿态估计。其次,我们扩展了RECON的参数并扩大了预训练数据集的规模,以获得稳健的3D表示。设N为多视图图像的数量,Ii是第i个视图的图像特征,Qi代表第i个视图的全局查询。按照Carion等人的方法,我们寻找一个具有最低成本的N元素的最优排列σ:
RECON++通过以下几个关键方面改进3D表示学习:
多视图图像查询:RECON++利用多视图图像来全面理解3D对象的语义信息,这包括RGB图像和深度图,从而为模型提供了丰富的几何和外观信息。
跨模态对齐:通过二分图匹配方法,RECON++能够隐式学习3D对象的姿态估计,这有助于模型更准确地对齐不同视图之间的特征。
扩大预训练规模:RECON++扩展了模型参数并增加了预训练数据集的规模,这有助于模型学习到更鲁棒和全面的3D表示。
特征融合:RECON++将局部3D点云编码器和全局3D点云解码器的特征结合起来,为3D理解任务提供了更全面的信息。
3D MM-Vet:3D 多模式理解评估基准
除了 3D 识别之外,LLM 还应表现出在现实世界具体场景中解决任务的能力。这需要统一上述能力,以遵循指令的方式逐步生成分解的任务操作,解决特定问题。因此,为了制定与上述任务描述相符的评估系统,我们建立了一个包含四级任务的多级评估任务系统:
i. 一般识别:遵循MM-Vet[179],我们评估LLM的基本理解能力,包括粗粒度和细粒度方面。粗粒度识别侧重于基本对象属性,如颜色、形状、动作等。而细粒度识别则深入到细节,如子部分和计数等。
ii. 知识能力与语言生成:为了检验模型理解和利用知识的能力,我们从MMBench[100]中汲取灵感,整合其推理组件。这包括自然和社会推理、物理属性、序列预测、数学等方面的知识,评估多模态LLM是否具备解决复杂任务所需的专业知识和能力。我们使用定制的提示来激发模型,提取详细的响应以评估语言生成。
iii. 空间意识:在3D中,空间意识的重要性比2D更高,因为提供了几何信息。点云包含位置信息,对于识别不同部件之间的空间关系至关重要。在2D中,要达到相同的信息强度水平,将需要多视图图像。因此,我们的评估包括探究LLM理解空间关系能力的问题。
iv. 具身交互:多模态LLM的应用范围扩展到具身交互领域,这得益于使用指令跟随数据。我们的评估系统通过正式请求LLM提供执行指令的步骤来测试它们的容量。这种方法旨在建立处理具身交互任务[39, 70]的连接。为了防止与训练数据重叠,我们收集的3D模型来源仅来自TurboSquid[142],这是一个在Objaverse[29]和ShapeNet[13]的获取列表中未包含的平台。我们精心策划了一个包含59个3D模型的数据集,生成了232个问题-答案对用于评估目的。在追求对单任务能力的精确评估中,每个问题都被设计为只测试前面概述的一个特定能力。每个问题都配有一个针对特定3D模型的相应答案,作为真实情况。更多的细节和分析可以在附录B中找到。

3. 【2024-05】Grounded 3D-LLM with Referent Tokens
动机
然而,对于3D感知和推理的统一模型的探索仍然很少,使其成为一个开放性问题。在本研究中,通过利用大型语言模型(LLM)的生成建模能力,我们引入了Grounded 3D-LLM,将多种3D视觉任务整合到语言格式中(见图1)。为了连接感知和语言,该模型将场景区域或对象特征表示为一种特殊标记,称为“引用标记”()。引用标记支持解码以识别场景中相应的实体。例如,可以表示诸如“附近的床头柜”或“三把棕色椅子”等实体,替换相应的文本标记。
摘要和结论
Grounded 3D-LLM,探索 3D 大型多模态模型 (3D LMM) 在统一的生成框架内整合各种 3D 视觉任务的潜力。该模型使用场景指代标 记作为特殊名词短语来引用 3D 场景,从而能够处理交错 3D 和文本数据的序列。它提供了一种自然的方法,可以使用特定于任务的指令模板将 3D 视觉任务转换为语言格式。
引言

- 我们开发了 Grounded 3D-LLM,它首先通过指称标记建立 3D 场景与语言短语之间的对应关系。此方法增强了场景引用,并有效地支持语言建模中的 3D 视觉任务,包括单对象和多对象基础,以及首次引入 3D 检测。
- 我们开发了精心设计的自动化 3D 场景字幕数据集管理管道,可在短语级别提供更精细的对应关系。在监督和零样本文本设置中使用 CLASP 进行的实验证明了对此数据进行预训练以实现短语级场景文本对齐的有效性。
- Grounded 3D-LLM 模型无需专门的模型,即可生成性地处理 3D 基础和语言任务。它在生成模型中的大多数下游任务中都取得了顶级性能,特别是在基础问题中,而无需针对特定任务进行微调。
模型框架
3.1 预备知识:视觉-语言对应关系
我们的动机是,短语到区域的对应关系提供了比句子级对应关系更细粒度的场景-文本对齐,使得能够在文本上下文中有效地建模具有相似属性的分组对象,例如空间关系或外观。一个视觉-语言模型首先在大量的场景-文本数据上进行预训练,以建立这种短语级跨模态对应关系。利用这种语义丰富的场景表示,一个LLM模型然后被训练将引用标记整合到具有共享语言描述的对象簇中。这个过程将引用标记的隐藏嵌入与它们对应的视觉参照物对齐,反映了短语到区域的方法。例如,在短语如“两个附近的棕色椅子”或简单地“对象”中,可以训练一个掩码解码器来产生的掩码嵌入,以推断这些目标椅子的位置和形状。
3.2 Grounded 3D-LLM

Grounded 3D-LLM的主要流程如图2所示。在预训练阶段,进行对比性语言-场景预训练(CLASP),以在短语层面上对齐大量场景-文本数据中的点和文本嵌入。在指令调整阶段,整体的Grounded 3D-LLM被训练以使用场景中的引用标记作为软文本标记来处理各种3D视觉任务,这些任务都在一个统一的生成模型框架中。
步骤1:对比性语言-场景预训练。Grounded 3D-LLM依赖于引用标记来引用3D场景,需要自然短语和场景参照物之间的短语级对齐。为了弥合3D和文本模态之间的差距,我们提出了对比性语言-场景预训练(CLASP)。这个模型共同训练一个3D编码器、一个文本编码器和一个跨模态交互器,用于文本引导的实例分割,如图2的左侧所示

3.3 Grounded Language Data

当然,让我们通过一个简化的例子来说明如何制作Grounded Language Data,按照论文中描述的步骤:
步骤1:自举对象字幕与GT标签校正(Bootstrapping object captions with GT label correction)
假设我们有一个3D扫描室内场景的数据集,里面包含了各种物体的3D模型和它们的标签,例如椅子、桌子、沙发等。首先,我们使用CogVLM模型来为每个物体生成描述性字幕。例如,对于一个椅子,CogVLM可能会生成:“这是一个红色的木椅。”
然后,我们需要校正这些字幕,确保它们与物体的真实标签一致。如果CogVLM错误地将一个物体描述为“红色的”,但实际上它是“蓝色的”,我们需要根据3D扫描数据集中的地面真实标签(GT)来纠正这个错误。
步骤2:将局部场景中的对象浓缩成字幕(Condensing objects in local scenes into a caption)
接下来,我们选择场景中的一个或多个物体作为“锚点”,并围绕这些物体生成描述整个局部场景的字幕。假设我们选择了一个沙发作为锚点,并且场景中还有一张桌子和两把椅子。我们可能生成如下字幕:
“一张蓝色的沙发位于房间中心,旁边是一张木质的长方形桌子,桌子上方悬挂着一个吊灯。”
在这个过程中,我们使用GPT-4模型来生成包含空间关系的自然语言描述。
步骤3:添加基于规则的关系(Adding rule-based relations)
为了进一步丰富字幕,我们添加程序生成的空间关系。例如,如果我们的规则库中有“沙发通常位于桌子旁边”这样的规则,我们就可以将这个关系添加到字幕中,生成如下描述:
“一张蓝色的沙发位于房间中心,旁边是一张木质的长方形桌子,桌子上方悬挂着一个吊灯。沙发和桌子构成了房间的休息区域。”
现有数据的转换(Conversion of existing data)
如果我们有现有的语言数据集,比如一个描述室内场景的文本集合,我们可以使用ChatGPT来提取与3D场景中物体相对应的短语。这些短语可以被用来训练模型,使其能够理解和生成与3D物体相关的语言描述。
扩展到具身对话和规划(Extension to embodied dialogue and planning)
最后,我们可以使用生成的地面化语言数据来训练模型进行具身对话和规划。例如,我们可以创建一个场景,其中包含了沙发、桌子和吊灯,然后生成以下对话:
- 用户:请问沙发旁边有什么?
- 助手:沙发旁边有一张木质的长方形桌子。
或者生成一个规划任务:
{
"prepare_for_guest": [
"Arrange [the blue sofa 1] facing [the wooden table 2]",
"Ensure [the lamp 3] is turned on for adequate lighting"
]
}
在这个例子中,我们使用了论文中描述的方法来生成与3D场景中物体相关的语言数据,这些数据可以用于训练和评估语言模型,使其能够理解和生成与3D视觉任务相关的语言描述。


![[<span style='color:red;'>论文</span><span style='color:red;'>阅读</span>] <span style='color:red;'>3</span><span style='color:red;'>D</span>感知相关<span style='color:red;'>论文</span>简单摘要](https://img-blog.csdnimg.cn/direct/76005c74105e46fa8a074afd8da7e919.png)
![[<span style='color:red;'>论文</span><span style='color:red;'>阅读</span>]Multimodal Virtual Point <span style='color:red;'>3</span><span style='color:red;'>D</span> Detection](https://img-blog.csdnimg.cn/direct/8b0c173e29da4b5e85f10f0c87f68892.png)

![[<span style='color:red;'>论文</span><span style='color:red;'>阅读</span>]CT<span style='color:red;'>3</span><span style='color:red;'>D</span>——逐通道transformer改进<span style='color:red;'>3</span><span style='color:red;'>D</span>目标检测](https://img-blog.csdnimg.cn/9395d0a654f74185b4c2a32b01b7f0c1.png)