scrapy爬取豆瓣书单存入MongoDB数据库
一、安装scrapy库
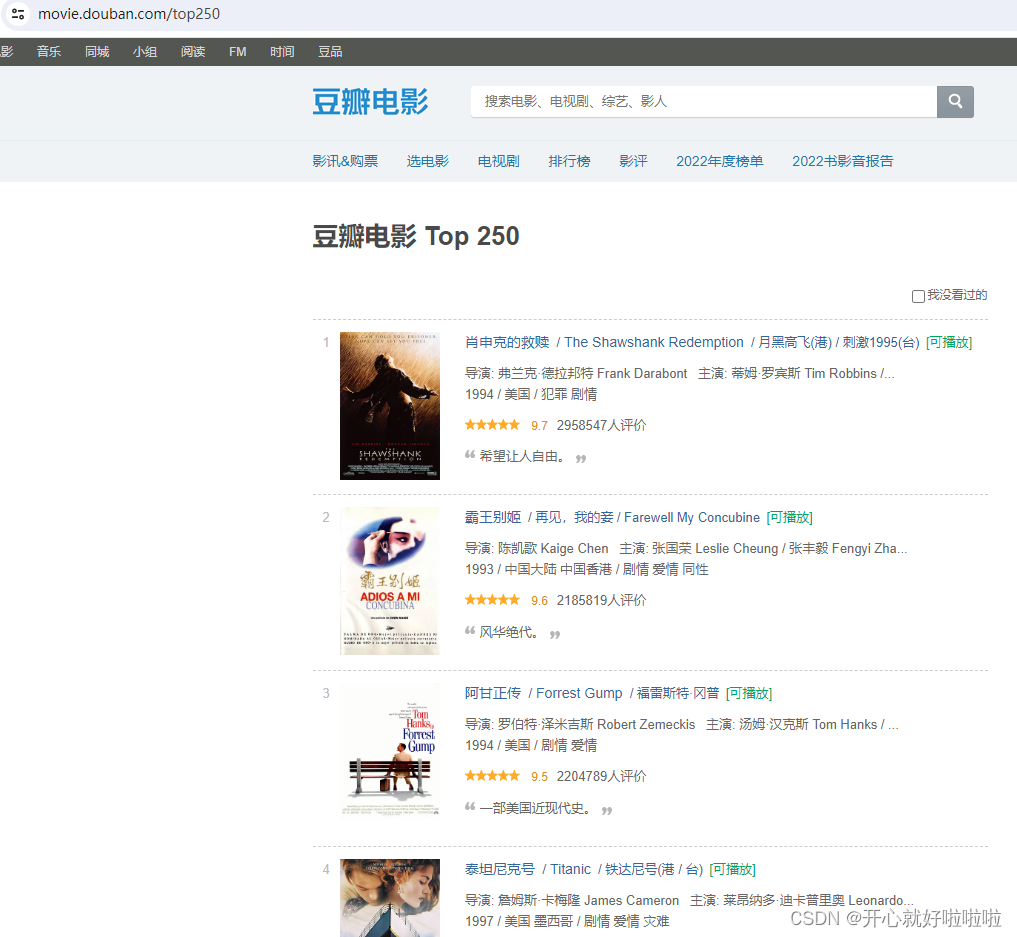
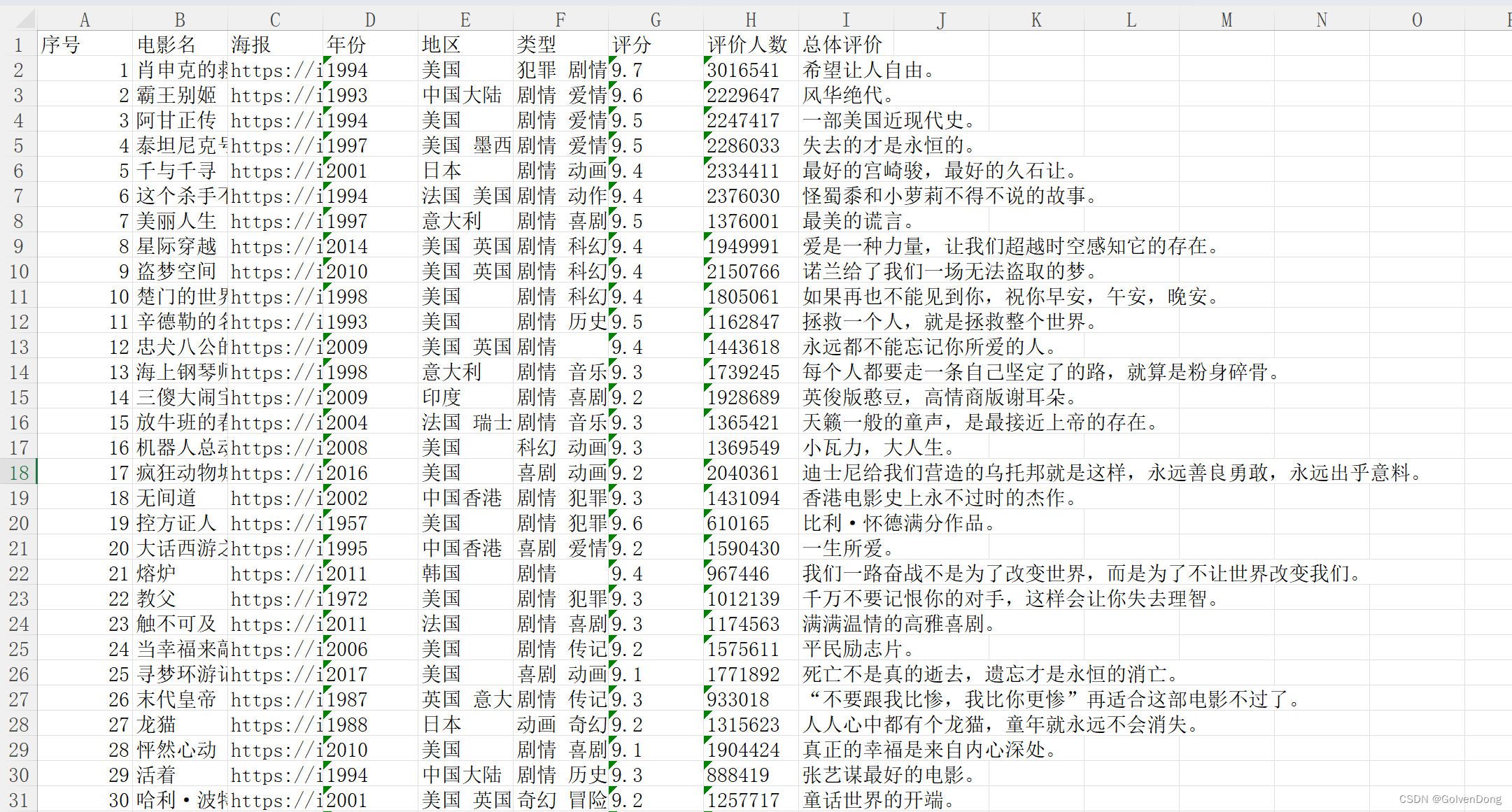
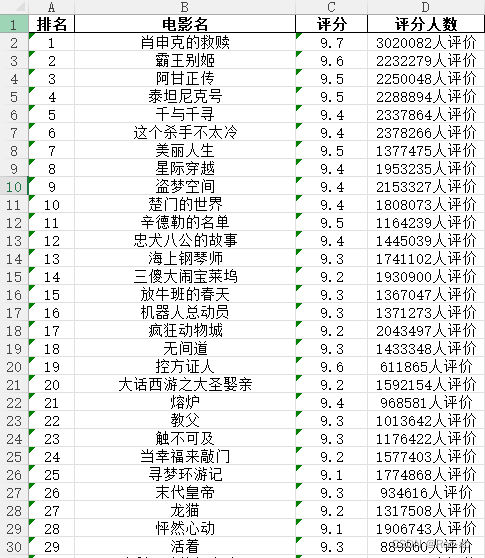
爬取的目标url是https://www.douban.com/doulist/45298673/,完整代码放在最后,使用命令pip install scrapy安装scrapy库。
二、创建scrapy项目
使用命令scrapy startproject doubanshudan来创建scrapy项目,再通过命令cd doubanshudan进入项目目录。
三、创建爬虫
使用命令scrapy genspider douban douban.com创建名为douban的爬虫,起始域名是douban.com。
四、修改settings,设置UA,开启管道
打开settings.py,将ROBOTSTXT_OBEY改为False,LOG_LEVEL设置为ERROR,将User-Agent改为自己的User-Agen,如下图所示:

在settings.py文件中取消管道代码的注释,如下图所示: