文章目录
1.预备知识
文件是文件内容+属性(也是数据)
文件的所有操作,无外乎对内容操作和对属性操作
文件在硬盘上放着,我们要想访问文件,本质上是进程在访问文件,进程要想访问文件必须调用接口进行访问(fopen,fwrite…)
要想向硬盘写入,只有操作系统有这个权限,所以如果普通用户想对文件进行操作,就必须调用文件类的系统接口(语言帮我们封装)
关于文件类的系统接口:如果语言不提供对系统接口的封装,那么所有访问文件的操作,都必须使用os的接口,一旦使用系统接口的话,编写的文件代码
就无法在其他平台中直接运行了,不具备跨平台性!
- 什么叫做文件:
站在系统的角度上,能够被input读取,或者能够output的设备文件就叫做就叫做文件
2.c语言接口
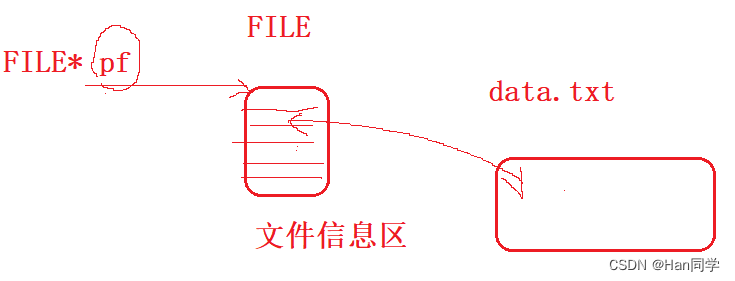
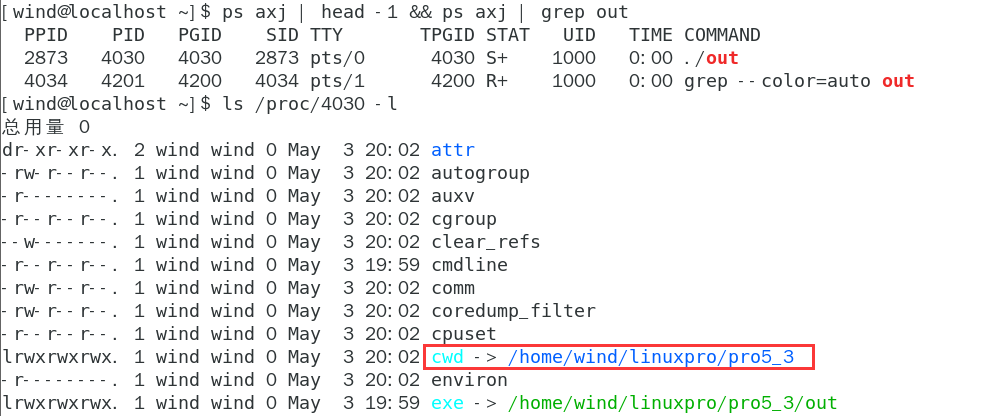
- **FILE *fopen(const char path, const char mode);
其中第一个参数叫做当前路径,指的是一个进程运行起来时,进程记录自己的当前工作目录(cwd),可以通过
ls/proc/pid查看
写入文件
- C 库函数 size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream) 把 ptr 所指向的数组中的数据写入到给定流 stream 中。
- **int fprintf(FILE stream, const char format, …);
- **int fputs(const char s, FILE stream);
const char* s1 = "Hello fwrite\n"; fwrite(s1, strlen(s1), 1, fp); const char* s2 = "Hello fprints\n"; fprintf(fp, "%s", s2); const char* s3 = "Hello fputs\n"; fputs(s3, fp);
- 其中第2行不需要是
strlen(s1)+1,因为\0结尾是c语言的规定,文件不需要遵守,文件需要保存的是有效数据- 由于w打开文件会先清空,所以有个小技巧
>filename相当于向文件写入空白,由于需要打开文件,所以文件内容会被清空读取文件
- char fgets(char str, int n, FILE* stream)**
// 写一个cat命令 int main(int argc, char *argv[]) { if (argc != 2) { printf("%s\n", "argc error!"); return 1; } FILE *fp = fopen(argv[1], "r"); if (fp == NULL) { perror("fopen"); return 2; } // 按行读取文件 char line[16]; // fgets会自动在结尾添加\0 while (fgets(line, sizeof(line), fp) != NULL) { fprintf(stdout, "%s", line); } }
3.系统接口
open
其中
flag表示标记位,使用了位图,原理如同下面,所以可以使用一个flag来表示多种状态#define ONE 0x1 // 0000 0001 #define TWO 0x2 // 0000 0010 #define THREE 0x4 // 0000 0100 void show(int flag) { if (flag & ONE) printf("hello one\n"); if (flag & TWO) printf("hello two\n"); if (flag & THREE) printf("hello three\n"); } int main() { show(ONE); show(TWO); show(ONE | TWO | THREE); show(ONE | THREE); }*ssize_t write(int fd, const void buf, size_t count);
int main() { // 设置umask为0 umask(0); // "r"是 open("log.txt", O_RDONLY); // "a"是 open("log.txt", O_WRONLY | O_CREAT | O_APPEND, 0666); // 以只写的方式打开,如果不存在该文件,则创建,每次打开会清空,并设置权限为666,类似fopen("path", "w") int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666); if (fd == -1) { perror("open:"); return 1; } // 向文件写入内容 const char *s = "hello myfile\n"; write(fd, s, strlen(s)); // 不需要+1 printf("open success, fd: %d\n", fd); close(fd); return 0; }*ssize_t read(int fd, void buf, size_t count);
int main() { int fd = open("log.txt", O_RDONLY); if (fd == -1) { perror("open:"); return 1; } printf("open success, fd: %d\n", fd); char buff[64]; memset(buff, '\0', sizeof buff); read(fd, buff, sizeof(buff)); printf("%s", buff); }

4.文件描述符
4.1 0 1 2
看下面的代码及运行结果
int fd1 = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
int fd2 = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
int fd3 = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
int fd4 = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
printf("open success, fd: %d\n", fd1);
printf("open success, fd: %d\n", fd2);
printf("open success, fd: %d\n", fd3);
printf("open success, fd: %d\n", fd4);

为什么是从3开始的呢?
实际上,0,1,2分别是stdin,stdout,stderro,其中stdin,stdout,stderro是FILE* 类型的,
FILE是个结构体,由c语言标准库提供,当他调用系统接口时,需要用到fd,所以该结构体里一定有fd属性
printf("%d\n", stdin->_fileno); printf("%d\n", stdout->_fileno); printf("%d\n", stderr->_fileno);
char buf[1024]; ssize_t s = read(0, buf, sizeof(buf)); if(s > 0){ buf[s]=0; write(1, buf, strlen(buf)); write(2, buf, strlen(buf)); }理解fd
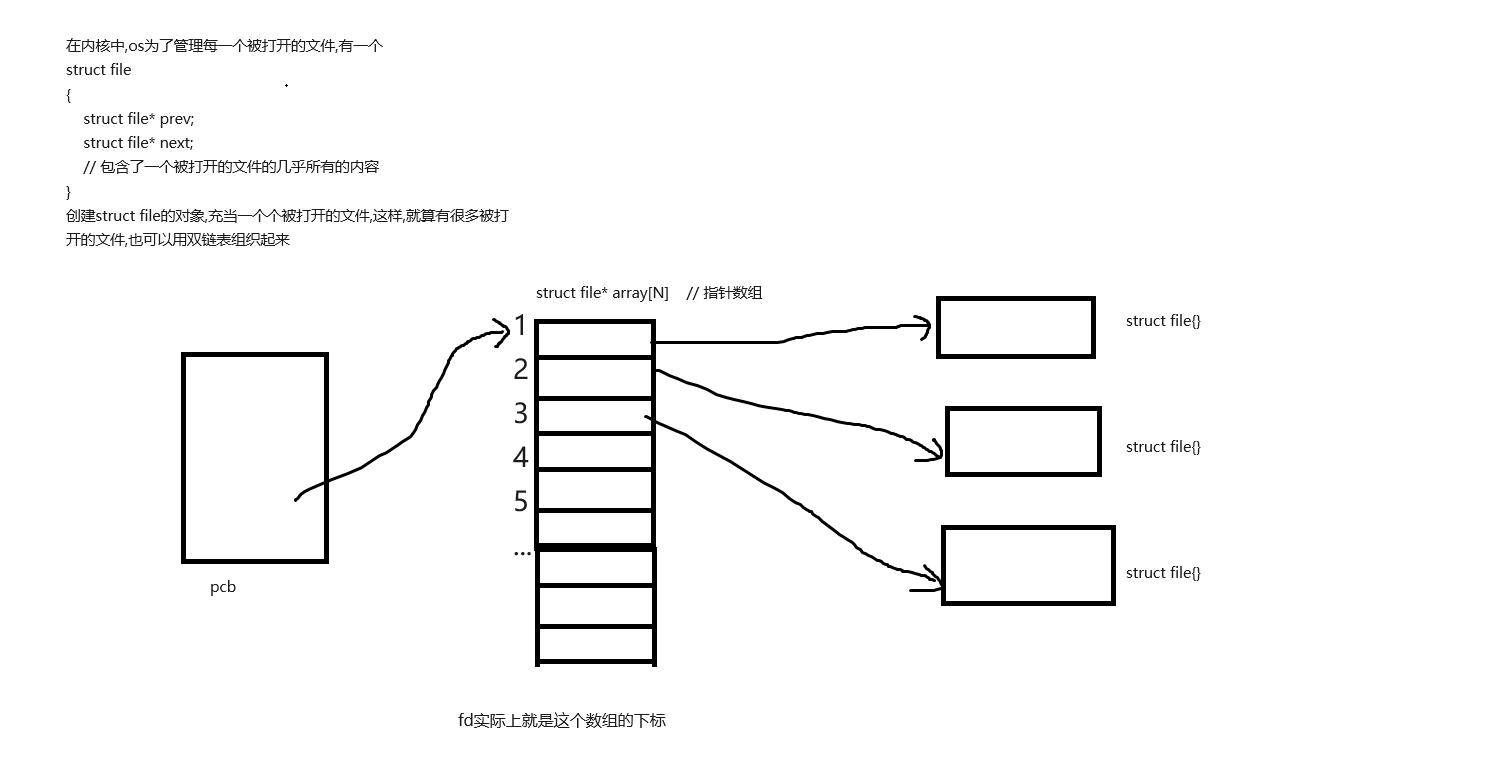
我们知道,进程如果想要访问文件,就必须打开文件,而且进程:打开的文件=1:n,文件要想被访问,前提是加载到内存中,才能被直接访问
如果多个进程都打开多个文件,系统就会存在大量的被打开的文件,所以os需要把如此之多的文件管理起来,先描述,在组织
观察源码
struct task_struct { //... /* open file information */ struct files_struct *files; //... } // Open file table structure // 打开文件表结构 struct files_struct { // ... struct file * fd_array[NR_OPEN_DEFAULT]; // 指针数组 }; // 被打开文件的属性 struct file { union { struct list_head fu_list; struct rcu_head fu_rcuhead; } f_u; struct path f_path; #define f_dentry f_path.dentry #define f_vfsmnt f_path.mnt const struct file_operations *f_op; spinlock_t f_lock; /* f_ep_links, f_flags, no IRQ */ atomic_long_t f_count; unsigned int f_flags; fmode_t f_mode; loff_t f_pos; struct fown_struct f_owner; const struct cred *f_cred; struct file_ra_state f_ra; u64 f_version; // ... }

4.2 文件描述符的分配规则
看下面的代码
int main()
{
close(0);
int fd = open("log.txt", O_WRONLY|O_CREAT|O_TRUNC, 0666);
if(fd < 0){
perror("open:");
return 1;
}
printf("fd :%d\n", fd);
close(fd);
return 0;
}
运行结果是0, 当我们
close(2)时,打印结果是和2,可见,文件描述符的分配规则是: 在fd_array数组中, 找到当前没有被使用的一个最小的下标,作为新的文件描述符
4.3 重定向
close(1);
int fd = open("log.txt", O_WRONLY|O_CREAT|O_TRUNC, 0666);
if(fd < 0){
perror("open:");
return 1;
}
printf("fd :%d\n", fd);
printf("fd :%d\n", fd);
printf("fd :%d\n", fd);
printf("fd :%d\n", fd);
fprintf(stdout, "hello fprintf\n");
const char* s="hello fwrite\n";
fwrite(s, strlen(s), 1, stdout);
fflush(stdout);
close(fd);

可以看到,原本应该写入到显示器上的内容现在加载到了文件中,这种现象叫做输出重定向
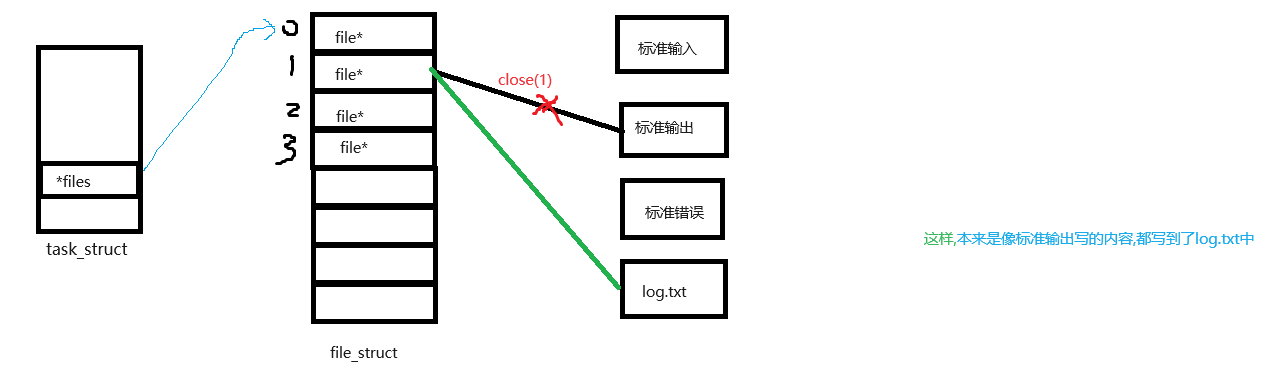
所以,重定向的本质,其实是在os内部,更改fd对应内容的指向
输入重定向
close(0); int fd = open("log.txt", O_RDONLY); if(fd < 0){ perror("open:"); return 1; } printf("fd: %d\n", fd); char buff[64]; while(fgets(buff, sizeof buff, stdin)!=NULL) printf("%s", buff);
追加重定向
close(1); int fd = open("log.txt", O_WRONLY|O_APPEND|O_CREAT); if(fd < 0){ perror("open:"); return 1; } fprintf(stdout, "appen value\n");


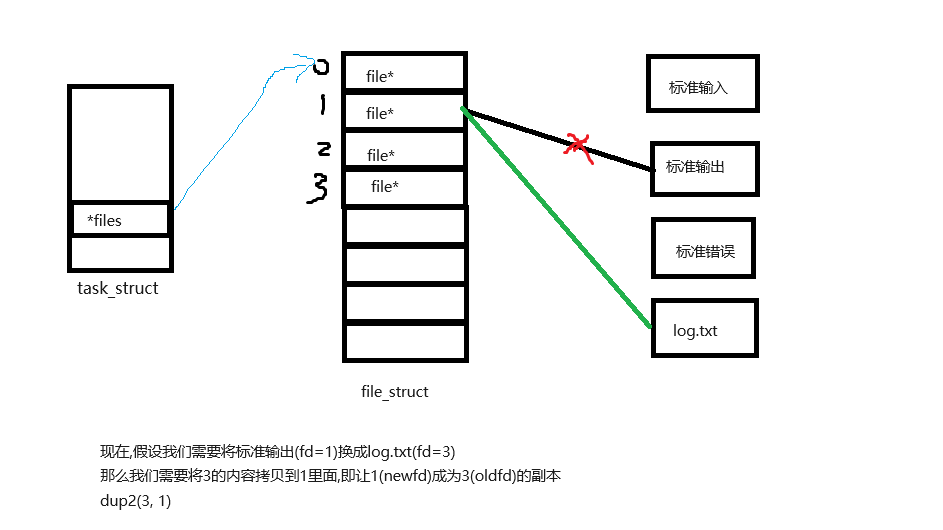
4.4 dup2
int dup2(int oldfd, int newfd);
dup2() makes newfd be the copy of oldfd, closing newfd first if necessary, but note the following:
* If oldfd is not a valid file descriptor, then the call fails, and newfd is not closed.
* If oldfd is a valid file descriptor, and newfd has the same value as oldfd, then dup2() does nothing, and returns newfd.
dup2()使newfd成为oldfd的副本,必要时首先关闭newfd, 但注意以下事项:
* 如果oldfd不是有效的文件描述符,则调用失败,并且newfd不会关闭。
* 如果oldfd是有效的文件描述符,并且newfd与oldfd具有相同的值,则dup2()不执行任何操作,并返回newfd。
这里拷贝的内容是fd_array数组中的
file*指针
 \
\
// 实现输出重定向
int main(int argc, char *argv[]) { if (argc != 2) { printf("default!\n"); return 2; } int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666); if (fd < 0) { perror("open:"); return 1; } dup2(fd, 1); // 写入到fd=1的文件中 fprintf(stdout, "%s\n", argv[1]); close(fd); }

4.5如何理解一切皆文件
使用面向对象的思想,将每一个硬件抽象成同一个file结构体,单独实现每一个硬件的方法(多态)


5.缓冲区
- 什么是缓冲区
就是一段内存空间
- 为什么要有缓冲区
提高整机效率,主要是提高用户的响应速度
缓冲区的刷新策略:一般+特殊一般:
- 立即刷新
- 行刷新(行缓冲,满一行再刷新)
- 满刷新(全缓冲)
特殊:
- 用户强制刷新(fflush)
- 进程退出
- 缓冲区由谁维护?在哪里?
c语言标准库(用户级缓冲区) 在c语言的struct FILE{}结构体里
内核级缓冲区一般而言,行缓冲的设备–显示器
全缓冲的设备 – 磁盘
且所有的设备永远倾向全缓冲,因为这将会有更少的io,提高效率,其它的刷新策略是结合具体情况做的妥协
5.1打印问题
int main()
{
// 下面是c语言提供的函数
printf("hello printf\n");
fprintf(stdout, "hello fprintff\n");
const char* s = "hello fputs\n";
fputs(s, stdout);
// 下面是os提供的函数
const char* s2 = "hello write\n";
write(1, s2, strlen(s2));
// 创建子进程
fork();
}


向显示器上打印和重定向到文件(磁盘上)中,结果却不一样 (如果去掉最后的fork()就不会有这种情况,所以可以确定是fork的原因)
5.2解释打印问题
- 如果向显示器打印,刷新策略是行刷新,那么最后执行fork()的时候,
函数执行结束并且数据已经被刷新了,此时fork()无意义- 如果对应的程序进行了重定向,即要向硬盘文件打印,那么对应的刷新策略就变成了全缓冲,\n没有意义了
那么最后执行fork()的时候,函数执行结束但是数据还没有刷新,数据还存在当前进程对应的c标准库中的缓冲区里,这部分数据属于父进程的数据,
当fork()分流结束,父子进程各自return,进程退出,需要刷新数据,刷新也属于"写",所以会发生写时拷贝,这样,我们就看到了处于缓冲区里面的数据被打印了两份!
所以,如果在fork()之前强制刷新,fflush(stdout),结果会是这样,因为刷新了c语言的缓冲区

6.让之前写的minishell支持重定向
#include <iostream>
#include <stdlib.h>
#include <stdio.h>
#include <cstring>
#include <stdio.h>
#include <sys/wait.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
#include <algorithm>
#include <assert.h>
using namespace std;
const int N = 1024;
char cmd_line[N];
char *g_argv[64]; // 用于储存分割后的命令
// 写一个环境变量buffer
char g_myval[N];
// 定义几个重定向 宏
#define INPUT_REDIR 1
#define OUTPUT_REDIR 2
#define APPEND_REDIR 3
#define NONE_REDIR 0
// 默认为没有重定向
int redir_status = NONE_REDIR;
char *CheckRedir(char *start)
{
assert(start);
// end要指向被打开的文件
char *end = start + strlen(start) - 1; // "ls -a -l\0", 此时end指向-l
while (end >= start)
{
if (*end == '>')
{
// 我们只考虑两种情况
// echo aaa>log.txt
// echo bbb>>log.txt
if (*(end - 1) == '>')
{
redir_status = APPEND_REDIR;
*(end - 1) = '\0';
end++;
break;
}
redir_status = OUTPUT_REDIR;
*end = '\0';
end++;
break;
}
else if (*end == '<')
{
// cat<log.txt 输入重定向
redir_status = INPUT_REDIR;
*(end) = '\0';
end++;
break;
}
else
end--;
}
// 通过break跳出,证明有重定向,返回打开的文件
if (end >= start)
return end;
// 没有重定向
return NULL;
}
// shell运行原理: 通过让子进程执行命令,父进程等待&&解析命令
int main()
{
// 命令行解释器一定是一个常住内存的解释器,不退出
while (true)
{
// 1. 打印出提示信息
cout << "[root@localhost myshell]# ";
fflush(stdout); // 需要手动刷新缓冲区
// 2. 获取用户的键盘输入
fgets(cmd_line, sizeof cmd_line, stdin);
cmd_line[strlen(cmd_line) - 1] = '\0';
// 2.1分析是否有重定向, "ls -a -l>log.txt"
char *sep = CheckRedir(cmd_line);
// 3. 命令字符串解析
g_argv[0] = strtok(cmd_line, " ");
int i = 1; // g_argv[N]的下标
if (strcmp(g_argv[0], "ls") == 0)
{
g_argv[i++] = (char *)"--color=auto";
}
else if (strcmp(g_argv[0], "ll") == 0)
{
g_argv[0] = (char *)"ls";
g_argv[i++] = (char *)"-l";
g_argv[i++] = (char *)"--color=auto";
}
while (g_argv[i++] = strtok(NULL, " "))
;
if (strcmp(g_argv[0], "export") == 0 && g_argv[1] != NULL)
{
strcpy(g_myval, g_argv[1]);
putenv(g_myval);
continue;
}
// 4.内置命令,让父进程(shell)自己执行的命令,叫做内置命令或者内建命令
if (strcmp(g_argv[0], "cd") == 0)
{
if (g_argv[1] != NULL)
chdir(g_argv[1]);
}
// 5.fork()
pid_t id = fork();
if (id == 0)
{
// child
if (sep != NULL)
{
int fd = 0;
switch (redir_status)
{
case INPUT_REDIR:
fd = open(sep, O_RDONLY);
dup2(fd, 0);
break;
case OUTPUT_REDIR:
// cout<<"执行了输出重定向"<<endl;
fd = open(sep, O_WRONLY | O_TRUNC | O_CREAT, 0666);
dup2(fd, 1);
break;
case APPEND_REDIR:
fd = open(sep, O_WRONLY | O_APPEND | O_CREAT, 0666);
dup2(fd, 1);
break;
default:
cout << "error" << endl;
break;
}
}
// 当执行cd命令(cd ..)时,只会影响子进程的当前目录,不会影响父进程的路径,所以有第四步
execvp(g_argv[0], g_argv);
exit(66);
}
// father
int status = 0;
pid_t ret = waitpid(id, &status, 0);
if (ret > 0)
cout << "退出码:" << WEXITSTATUS(status) << endl;
}
return 0;
}

7.为何需要fflush?
close(1);
int fd = open("log.txt", O_CREAT | O_WRONLY | O_TRUNC, 0666);
if(fd < 0) {
perror("open");
return 1;
}
printf("hello world, fd: %d\n", fd);
fflush(stdout);
close(fd);
看上面的代码,由于close(1),所以printf()并不会打印到显示器上,而是会将数据重定向写到log.txt中
如果不进行fflush(stdout),数据会暂存到stdout的缓冲区中,而随后执行的close()又会关闭fd,此时数据变无法刷新

8.标准错误
8.1重定向
// stdout->1
printf("hello printf 1\n");
fprintf(stdout,"hello fprintf 1\n");
const char* s1 = "hello write1\n";
write(1, s1, strlen(s1));
std::cout<<"hello cout 1" << std::endl;
// stderr->2
perror("hello perror 2");
const char* s2 = "hello write 2\n";
write(2, s2, strlen(s2));
std::cerr<<"hello cerr 2" << std::endl;

可以看到,重定向默认只重定向1号fd内容的数据
虽然1号fd和2号fd都对应的显示器文件,但是他们两个是不同的,如同认为,同一个显示器文件,被打开了两次,所以log.txt里只有1号fd的内容,而显示器上还是2号fd内容的数据
如果想将标准输出和标准错误的打印结果分文件保存,可以使用

如果想让标准输出和标准错误的打印结果放到同一个文件,可以使用

要想实现文件内容的拷贝,可以使用(下图为将log.txt的内容拷贝到back.txt中)

一般而言,如果程序运行可能有问题的话,建议使用stderr,或者cerr来打印,如果是常规的文本内容,我们建议进行定cout,stdout来打印
8.2 perror的原理
perror的实现原理
perror函数的具体实现取决于操作系统和编译器的不同。一般来说,它通过读取全局变量errno来获取错误代码,并将其转换为可读的错误描述。errno是一个整数类型的宏定义,表示最近一次发生的错误代码。
当系统调用失败时,通常会将错误代码存储在errno中。而perror函数会根据错误代码查询系统定义的错误信息表,找到对应的描述,并输出到标准错误流。
看下面的代码及运行结果
// 手动设置errno
errno = 1;
perror("err");

errno = 2;
perror("err");

8.3自己实现perror
调用[strerror()](C 库函数 – strerror() | 菜鸟教程 (runoob.com))
void MyPerror(const char* msg)
{
fprintf(stderr, "%s: %s\n", msg, strerror(errno));
}
int main()
{
// 打开一个不存在的文件
int fd = open("not_exist", O_RDONLY);
if(fd < 0) {
MyPerror("open");
return 1;
}
close(fd);
return 0;
}

下面来看未被打开的文件–磁盘级文件
9. inode
9.1 理解文件系统

首先,磁盘的基本单位是扇区(512字节),但是操作系统(文件系统)和磁盘进行io的基本单位是4kb(8*512byte)
其中,这4kb称为block大小,因此磁盘也被称为块设备
- Data blocks: 是多个4kb(扇区*8)大小的集合,保存的是特定文件的内容
- inode Table: 是一个大小128byte的空间,保存的是对应文件的属性,该块组内,所有文件的inode空间的集合,需要标识唯一性
即每一个inode块,都要有一个inode编号.一般而言,一个文件,一个inode块,一个inode编号- Block Bitmap: 假设有10000+个blocks,10000+bit位,比特位和特定的block是一一对应的,其中bit位为1,代表该block被占用,否则表示可用
- inode Bitmap:同理,每个bit表示每一个inode是否空闲可用
- GDT:块组描述符,描述块组属性信息 ,包括但不限于,这个块组多大,已经使用多少了,有多少个inode,已经占用了多少个,还剩多少,一共有多少个block,使用了多少…
- super Block:存放文件系统本身的属性信息。记录的信息主要有:block和 inode的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个文件系统结构就被破坏了
9.2 inode
假设一个文件只对应一个inode属性节点,inode编号
但是一个文件不能只对应一个block,因为一个block才4kb
那么
- 我们如何确定哪些block属于同一个文件?
- 确定文件的inode编号,就可以找到该文件,就可以找到该文件的inode属性集合,可是文件的内容呢?
实际上,我们可以简单理解inode结构体为
struct inode
{
// 文件的大小
// 文件的inode编号
// 其他属性
int blocks[N]; // 这个保存的是和它同一个块组的块的编号
};
这样,有了blocks[N]数组之后,我们就可以确定哪些block属于同一个文件,也可以找到该block,进而找到文件的内容
9.3 inode和文件名的关系
linux中,inode的属性里面,没有文件名的说法
- 一个目录下,可以保存很多文件,但是这些文件没有重复的文件名
- 实际上,目录也是文件,也有自己的inode,有自己的Data blocks. 其Data blocks里面储存的内容就是
文件名:inode的映射关系,这里的文件名和inode是互为key的,具有唯一性,文件系统即可以用文件名做key值,也可以用inode做key值所以,如果要想在一个目录里面创建文件,必须要有目录的写(w)权限,实际上就是为了能够有 在目录的Data blocks里面写入
文件名:inode的权限
同理,如果想在一个目录里面显示所有的文件名和属性,必须要有目录的读®权限, 实际上就是为了能够有 在目录的Data blocks里面读取文件名:inode的权限
如果要想找到一个文件, 需要经过: inode编号->这个分区特定的Block Group-> inode块 -> 文件属性 -> 文件内容
要想找到文件的inode,需要依托于目录结构
这个目录结构叫做目录项(dentry),目录项指的是文件系统中用于跟踪文件和目录的结构。具体来说,目录项是文件系统用来缓存文件名和inode(索引节点)之间映射的数据结构。
9.4 系统做了什么?
创建文件,系统做了什么?

创建文件,系统做了什么?

查看文件,系统做了什么?

inode和数据块是独立管理的。一个文件或目录需要一个inode来记录元数据,同时需要数据块来存储数据。如果inode用尽,即使数据块还有剩余,也无法创建新的文件或目录,因为新的文件或目录没有inode来记录其元数据。反之,如果数据块用尽,即使还有未使用的inode,也无法存储新的数据。
即inode最大个数是固定的,Data blocks的个数也是固定的,所以会存在某一方先用完这种情况,这时可能会出现明明有空间,却创建不了文件的情况.
10 软硬链接
10.1 软链接
软链接是一种特殊的文件,它包含了指向另一个文件或目录的路径。软链接更像是一个快捷方式或指针,它并不与目标文件共享inode,而是存储了一个指向目标的路径。软链接是一个独立的文件
特点
- 软链接可以跨文件系统创建,因为它存储的是目标的路径。
- 软链接可以指向文件或目录。
- 如果软链接指向的目标被移动或删除,软链接将变成一个“死链接”(dangling link),即它指向的目标不再存在。
- 软链接有自己的inode,因此它有自己的文件属性,如权限和所有者。
- 软链接的大小通常很小,因为它只存储路径信息。
10.2 硬链接
硬链接是指向文件inode的直接引用。当创建一个硬链接时,不是真正的创建新文件,而是在指定的目录下, 建立了文件名和指定inode的映射关系. 这意味着硬链接和原始文件共享同一个inode,因此它们**实际上是同一个文件的不同名字。**硬链接不是一个独立的文件
特点
- 硬链接不能跨文件系统创建。创建硬链接的文件和链接本身必须位于同一个文件系统中。
- 硬链接可以指向目录,但删除指向目录的硬链接并不会影响目录本身。
- 当删除一个硬链接时,文件的数据并不立即被删除,只有当所有指向该inode的硬链接都被删除后,文件数据才会被回收。
- 硬链接不包含文件路径信息,它直接指向文件系统中的inode。
10.3 硬链接数
硬链接数(Link count)是指在文件系统中指向一个特定inode的硬链接的数量。
- 硬链接共享: 当一个硬链接被创建指向一个文件时,文件的硬链接数会增加。因为硬链接是文件的直接引用,所以它们共享同一个inode。
- inode释放: 当硬链接数为1时,表示只有原始文件名指向该inode。如果删除原始文件名,inode会被释放,因为没有任何硬链接指向它了。
- 删除行为: 如果硬链接数大于1,即使删除了原始文件名,inode也不会被释放,因为还有其它硬链接指向它。只有当所有硬链接都被删除后,inode才会被释放。
- 可以使用
ls -l命令来查看文件的硬链接数。输出的第二列显示的是硬链接数
- 创建一个普通文件,默认硬链接数是1,因为只有自己的文件名和inode相对应
- 创建一个目录,默认硬链接是2,因为不但有自己的文件名和inode相对应,而且目录里还有一个 . 文件
10.4 创建软硬链接
创建硬链接
ln source_file hard_link_name这将创建一个名为
hard_link_name的硬链接,指向source_file文件。创建软链接
ln -s target_file soft_link_name这将创建一个名为
soft_link_name的软链接,指向target_file。
10.5 使用场景
- 硬链接:通常用于备份重要文件,因为它们提供了对文件数据的直接访问,不受文件名或路径变化的影响。
- 软链接:常用于创建快捷方式或简化复杂的文件路径,特别是在脚本和配置文件中。
11 动静态库
库(Library)是一组可以被多个程序共享的代码和资源。库的主要目的是代码重用和模块化,它们可以包含函数、变量、宏等。Linux中的库分为两大类:静态库和动态库。
11.1 静态库(Static Libraries)
静态库通常以.a为文件扩展名。它们在程序编译时被包含进最终的可执行文件中。
特点
- 编译时链接: 静态库在编译期间被链接到最终的可执行文件中。这意味着静态库中的代码和数据会被复制到可执行文件中。
- 体积较大: 由于静态库的代码被包含在每个使用它的可执行文件中,因此生成的可执行文件通常比较大。
- 性能: 静态库可以提高程序的加载速度,因为它们在编译时已经被包含进程序中,运行时不需要额外的链接过程。
- 版本控制: 使用静态库时,程序携带的是库的特定版本,因此不容易出现版本冲突问题。
- 独立性: 静态库生成的可执行文件不依赖于系统中的库文件,可以在没有安装相应库的系统上运行。
11.2 动态库
动态库通常以.so(Shared Object)为文件扩展名。它们在程序运行时被加载和链接。
特点
- 运行时链接: 动态库在程序运行时才被加载和链接。这意味着多个程序可以共享同一份库文件,节省内存和磁盘空间。
- 体积较小: 由于动态库的代码在运行时才被加载,生成的可执行文件通常比较小。
- 灵活性: 动态库允许程序使用库的最新版本,因为它们可以在不重新编译程序的情况下更新。
- 依赖性: 使用动态库的可执行文件在运行时需要依赖于系统中的库文件,如果库文件被删除或更改,程序可能无法正常运行。
- 性能开销: 动态库在程序启动时需要进行加载和链接,可能会有一定的性能开销。
11.3 链接过程
- 静态链接: 在编译时,编译器会将静态库中的相关代码直接复制到可执行文件中。
- 动态链接: 在运行时,动态链接器(如ld.so)会负责将动态库加载到内存中,并与程序的其余部分链接。
11.4 使用场景
- 静态库: 需要生成一个独立的可执行文件,或者在没有网络连接的环境中部署程序时
- 动态库: 需要共享库文件,或者希望利用库的最新版本时
11.5 如何写一个静态库并安装
我们现在写了mymath和myprint
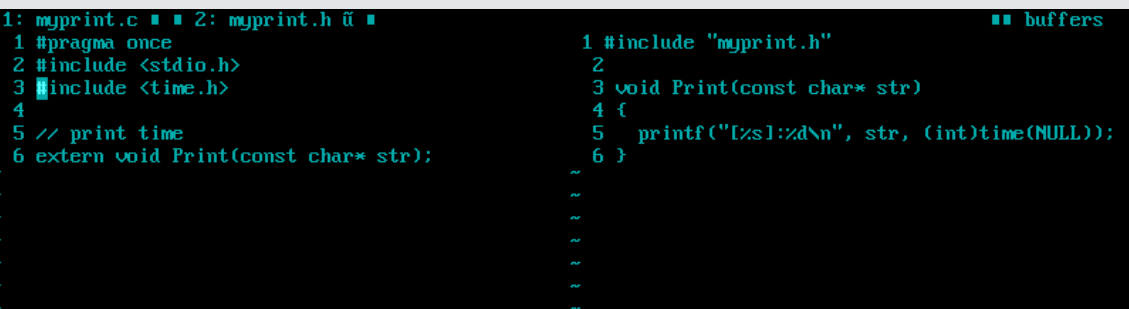

将其汇编后生成.o文件


创建归档文件(静态库)
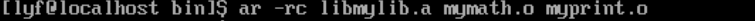
我们可以将上面的过程写一个Makefile
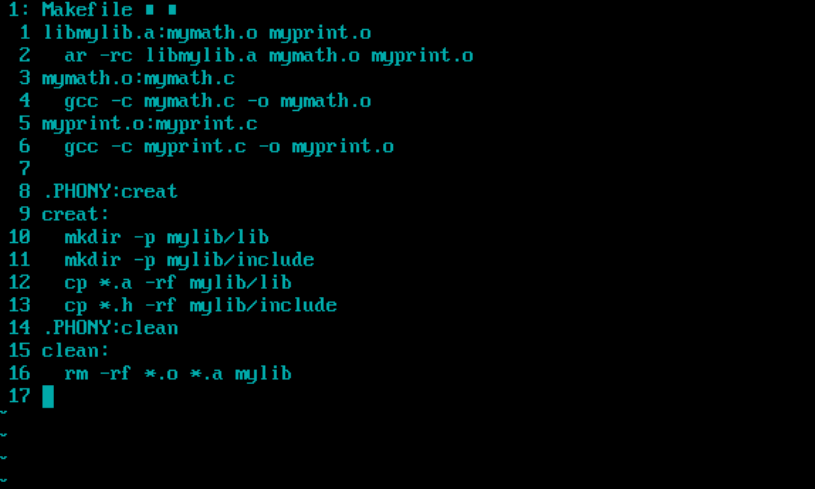
当执行make creat时,会创建文件夹mylib/lib和mylib/include,并将库文件和头文件拷贝一份进去
或者这样修改, 看第6行和第7行,不需要写$@,因为gcc -c默认就会给.c文件重命名成同名的.o文件(加上也无所谓)
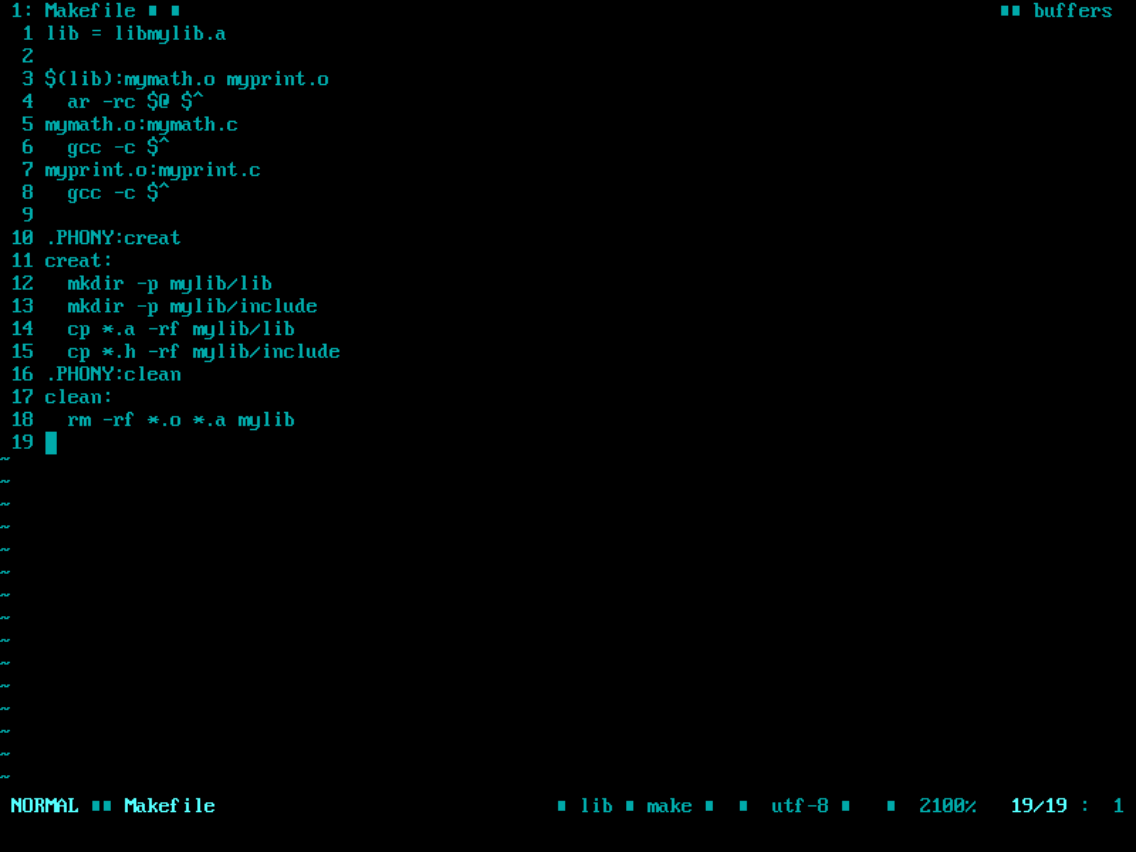
将其拷贝到gcc的默认搜索路径
头文件的默认搜索路径是: /usr/include
库文件的默认搜索路径是: lib64 or /usr/lib64

接下来使用main.c 链接这个静态库:gcc main.c -l库名
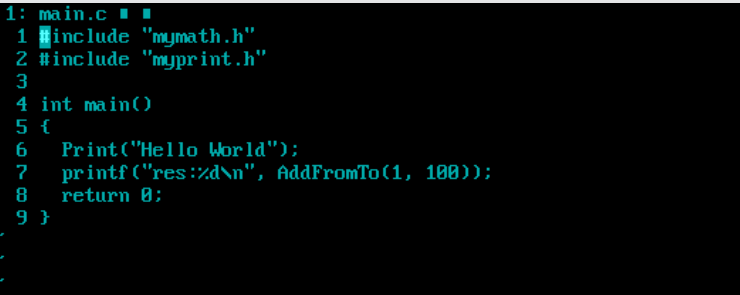

上面的操作就叫做库的安装,一般而言,在网上下载的库,推荐使用这种方法
方法2
告诉main.c在哪里搜索头文件和库 以及 具体要用哪个库

方法3
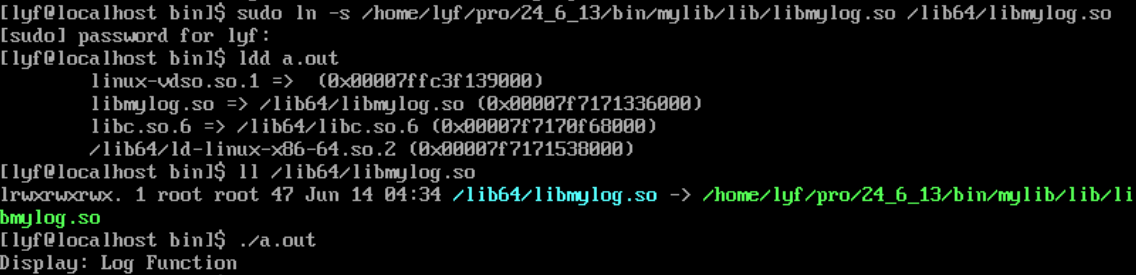
使用软链接
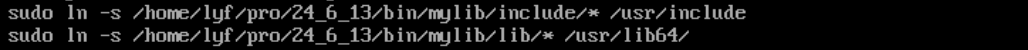

但我们使用ldd命令看,并没有显示"not found"(由于ldd会显示可执行程序依赖的动态库,所以如果显示"not found"可以证明是静态链接),说明gcc默认是动态链接的
我们可以知道,如果系统中既有动态库,也有静态库,那么gcc就默认使用动态链接,想要静态链接,得使用gcc -static选项
如果系统中只有静态库,那么gcc也没有办法使用动态链接,这时,就默认使用静态链接了
11.6写一个动态库并安装
现在写一个mylogc.h和mylog.c,用于创建动态库
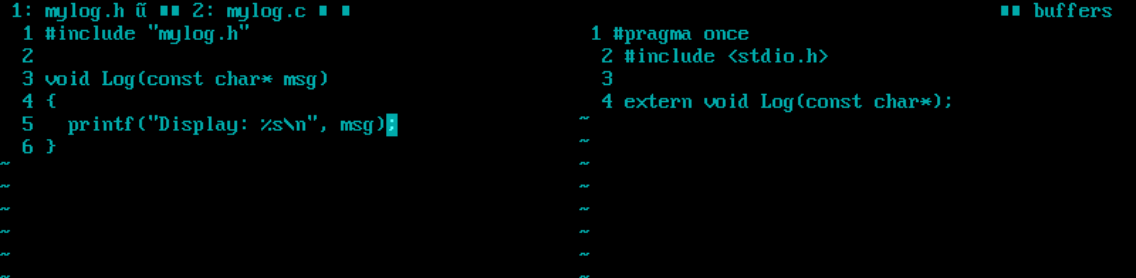
生成动态库


我们可以看到,动态库带了一个x属性(可执行),这是因为当使用动态库时,它需要被加载到内存
此时Makefile为
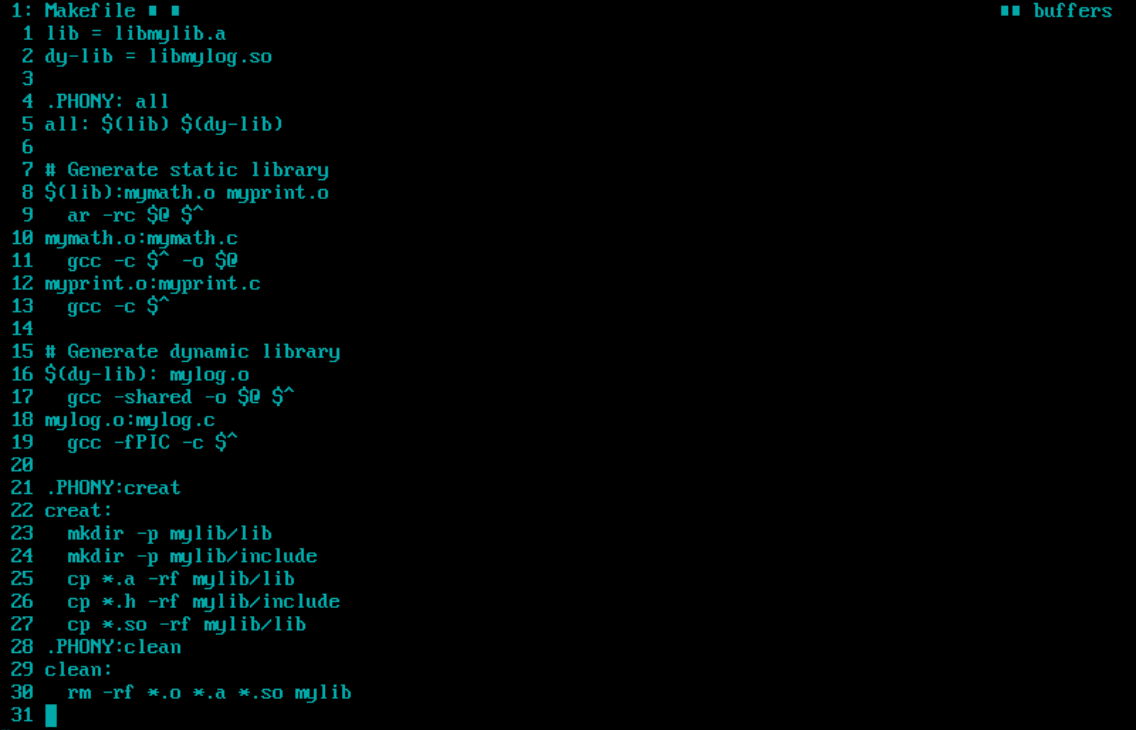
运行结果为

此时main函数为

当我们使用这种方法时,确实可以生成可执行程序(注意,gcc后面可以跟多个-l选项)

但是当我们运行时

为了防止混淆,我们把静态库用到的.h和代码去掉,只剩下Log方法
通过ldd命令可以看到并没有找到这个静态库

实际上,虽然能我们已经告诉了gcc编译器要用哪个库,编译器也成功完成了它的工作,形成了可执行文件.
但是,并没有告诉加载器需要加载哪个动态库,所以会出现找不到库的情况
而静态库则没有这个问题,因为静态库的代码在编译阶段就已经被复制到可执行文件中,因此在程序运行时不会进行搜索或加载。
11.7加载动态库的几种方法
1.直接安装到系统里(一般使用这个)

2.使用软链接
3.将库所在的路径,添加到系统变量LD_LIBRARY_PATH
LD_LIBRARY_PATH作用: 它允许用户为动态链接器添加额外的搜索路径,这在安装非标准路径下的库或调试时非常有用。
LD_LIBRARY_PATH设置: 可以通过在shell中执行以下命令来设置
LD_LIBRARY_PATH:export LD_LIBRARY_PATH=/path/to/libraries:$LD_LIBRARY_PATH or export LD_LIBRARY_PATH=$LD_LIBRARY_PATH: /path/to/libraries # 区别 第一种情况 (export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/path/to/libraries): 这种用法会将 /path/to/libraries 添加到当前 LD_LIBRARY_PATH 环境变量值的末尾。这意味着,如果 LD_LIBRARY_PATH 已经包含了一些路径,这些路径将在搜索顺序中排在 /path/to/libraries 之前。 第二种情况 (export LD_LIBRARY_PATH=/path/to/libraries:$LD_LIBRARY_PATH): 这种用法会首先将 /path/to/libraries 设置为 LD_LIBRARY_PATH 的初始部分,然后将原来 LD_LIBRARY_PATH 中的路径追加到这个新值的末尾。这意味着 /path/to/libraries 会在搜索顺序中优先于原来 LD_LIBRARY_PATH 中的任何路径。

4.在/etc/ld.so.conf.d建立自己的动态库路径的配置文件(存放动态库的路径),然后重新ldconfid即可


注意,一个配置文件,一个路径
11.8动态库的加载
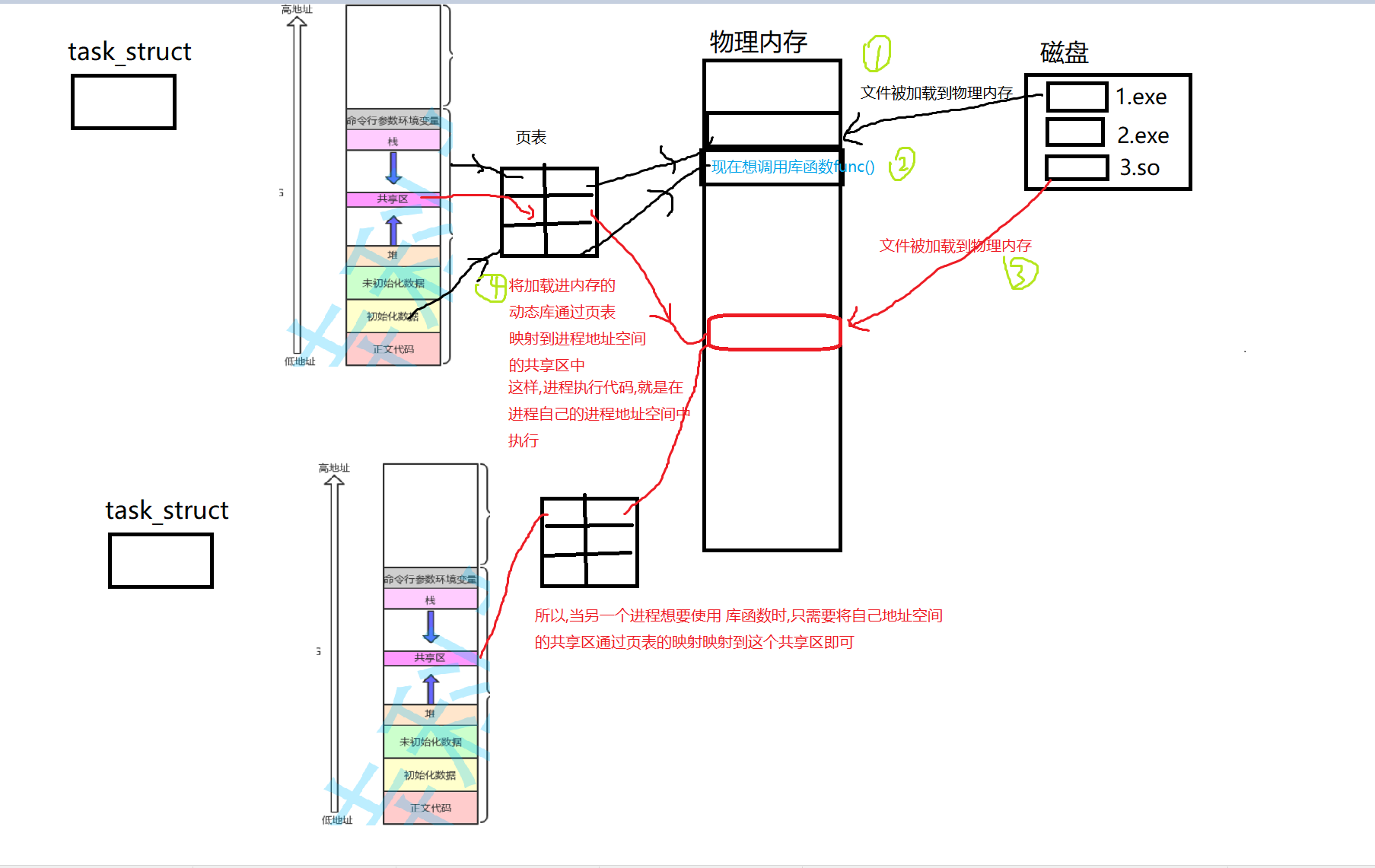
我们知道,动态库在进程运行的时候,是要被加载的(静态库没有), 且常见的动态库是被所有程序动态链接的,都要使用, 所以动态库也叫共享库.于是我们可以得到一个结论,动态库在系统中加载之后,会被所有进程共享
- 共享性: 动态库设计上允许多个进程共享同一份库文件,这意味着物理存储上,库文件不会被复制,多个进程可以访问同一份库代码。
- 内存中的共享: 虽然多个进程可以访问同一个动态库文件,但每个进程在内存中有自己的地址空间。当动态库被加载到内存中时,通常是通过一种称为“内存映射”的方式,这允许文件内容被映射到进程的地址空间。在某些配置下,多个进程可能共享内存映射区域,但这不意味着它们共享同一个内存副本;每个进程仍然有自己的内存页。
- 加载时机:动态库不一定在所有进程启动时加载。只有在进程代码中使用了库中的符号(如函数调用)时,动态库才会被加载。如果一个进程没有使用到某个动态库,那么这个库就不会被加载到该进程的地址空间。
12. 关于地址
12.1几个概念
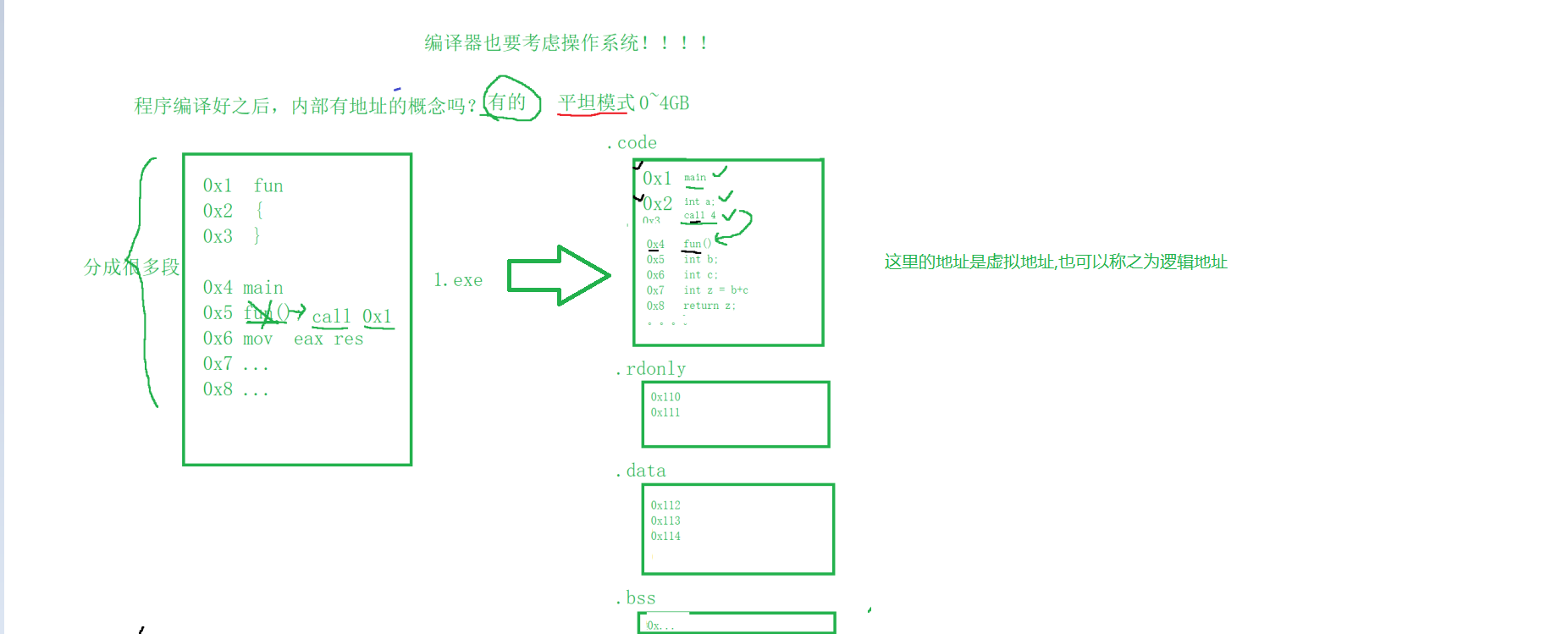
虚拟地址(Virtual Address):
- 虚拟地址是程序在执行时使用的地址,它们是相对于程序自己的地址空间的。在程序生成跳转指令或访问栈、全局变量等时,使用的是虚拟地址。
- 虚拟地址空间为每个进程提供了一个抽象的、连续的地址范围,这个范围可能远大于实际的物理内存大小。
- 虚拟地址的使用允许多个进程同时运行而不会发生地址冲突,因为每个进程都有自己的虚拟地址空间。
物理地址(Physical Address):
- 物理地址是实际内存单元的地址,它们是直接映射到硬件的内存芯片上的。
- 物理地址通常对程序来说是透明的,程序不会直接使用它们。
内存管理单元(MMU):
- 当程序运行并访问其虚拟地址空间中的某个地址时,内存管理单元(MMU)负责将虚拟地址转换为对应的物理地址。
- 这个转换过程对程序是透明的,由硬件自动处理。
程序加载:
- 当你启动一个程序时,操作系统会将其代码和初始数据加载到物理内存中,并为该程序创建一个虚拟地址空间。
- 程序开始执行时,CPU中的程序计数器(PC)包含的是虚拟地址,而不是物理地址。
执行过程中的地址转换:
- 在程序执行过程中,CPU生成的是虚拟地址。当CPU需要访问内存时,MMU将这些虚拟地址转换为物理地址。
程序未加载时:
- 即使程序还未加载到内存中,它的可执行文件和相关资源在磁盘上也是定义了虚拟地址空间的。当程序被加载时,这个虚拟地址空间会被操作系统映射到物理内存。
程序的执行:
- 程序的执行是基于虚拟地址空间的。即使在程序开始执行之前,操作系统也需要解析程序的虚拟地址空间,以便在程序加载时正确地映射到物理内存。
虚拟地址和物理地址的区别不在于程序是否已经加载到内存中,而在于它们在内存访问过程中的角色。虚拟地址是程序直接使用的地址,而物理地址是实际存储在内存芯片上的地址。程序的执行是基于虚拟地址空间的,由操作系统和MMU负责管理虚拟地址到物理地址的映射。
12.2 程序没有被加载到内存的地址时
12.3 程序加载后的地址
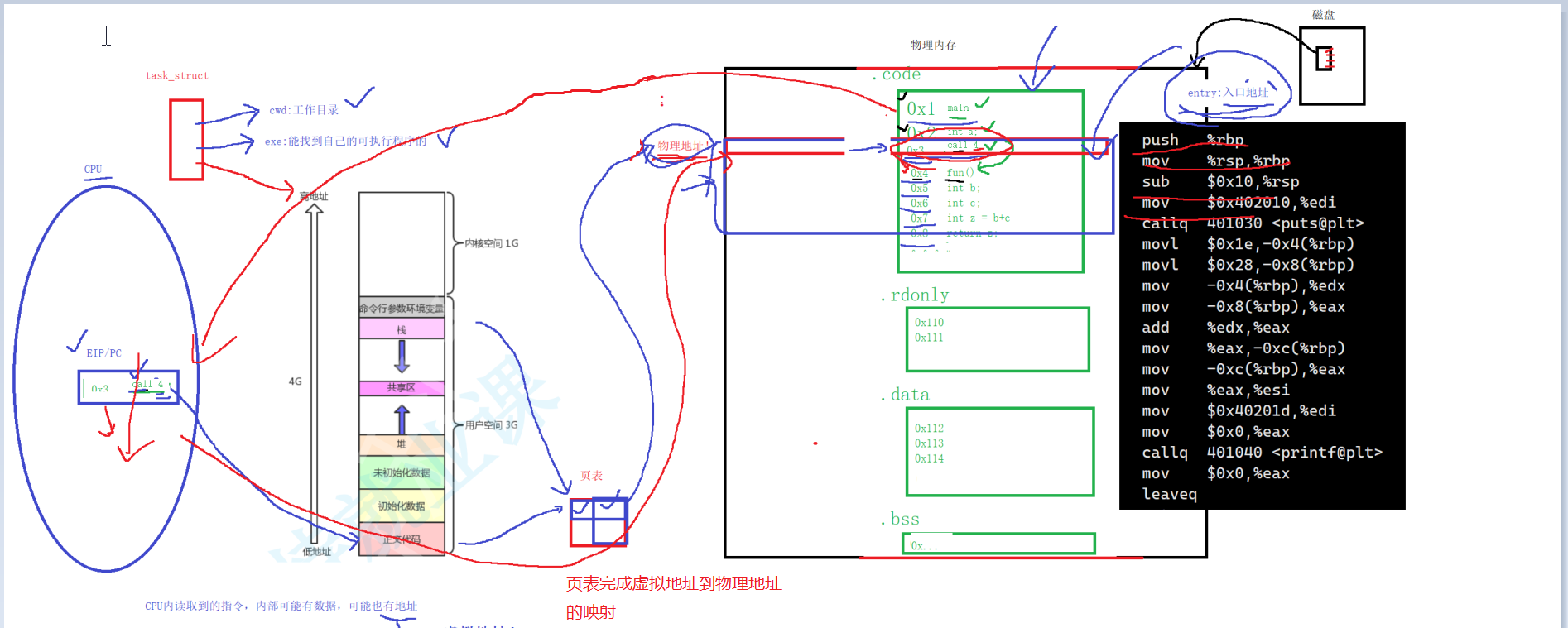
当程序尝试访问的虚拟地址没有对应的物理页帧时,或者页面当前不在物理内存中,那就发生缺页中断,更新页表的映射关系 或 将磁盘中的内容加载到内存中
12.4动态库的地址

问题:静态库为什么不谈加载:因为静态库中的代码和数据会被复制到可执行文件中,所以就不存在上图所说的加载问题;同理,也没有与位置无关码,不需要使用偏移量,直接使用绝对地址即可



![14.[<span style='color:red;'>文件</span>]<span style='color:red;'>Linux</span>的<span style='color:red;'>文件</span>](https://img-blog.csdnimg.cn/img_convert/57570b052f9ecb72f386a42b4dd25130.png)