题目描述
- 假定有一个无限长的数轴,数轴上每个坐标上的数都是
0。 - 现在,我们首先进行
n次操作,每次操作将某一位置x上的数加c。 - 接下来,进行
m次询问,每个询问包含两个整数l和r,你需要求出在区间[l,r]之间的所有数的和。
输入格式
- 第一行包含两个整数
n和m。 - 接下来
n行,每行包含两个整数x和c。 - 再接下来
m行,每行包含两个整数l和r。
输出格式
- 共
m行,每行输出一个询问中所求的区间内数字和。
数据范围
−10^9 ≤ x ≤ 10^9,1 ≤ n, m ≤ 10^5,−10^9 ≤ l ≤ r ≤ 10^9,−10000 ≤ c ≤ 10000
详细思路
- 这道题的一个最直观的思路是基于数组的,也就是说,类似于根据指定的下标,将数组中某个元素的值增加一个指定的数字。
- 然而,直接使用数组会遇到这样的问题:首先,本题中的位置变量
x可能为负数,而我们不能直接以负数作为位置下标;另外,即使通过一定的方式将x的值都变为非负数(例如所有x都自增10的9次方),本题中x的数据范围仍然太大,更不用说开这么大一个数组所带来的空间消耗了;最后,就算计算机有足够大的内存空间开辟一个如此大的数组,由于指定位置加法操作的次数不超过十万次,所以数组中的大量位置仍然是0,具有明显的稀疏性,内存的使用效率极低。因此,我们必须考虑其他的方法。 - 离散化算法是指将一系列取值范围很大且非连续的数(例如包含浮点数或不连续整数的情况),映射到一系列从0开始的取值范围小得多的连续整数。由于本题中存在的问题即是直观方法中数组下标取值范围太大且并非连续,因此如果能够通过离散化的方法,将这些下标映射为从零开始的连续整数,那么就可以尝试以数组的思路进行求解了。既然如此,那就需要考虑如何进行映射。
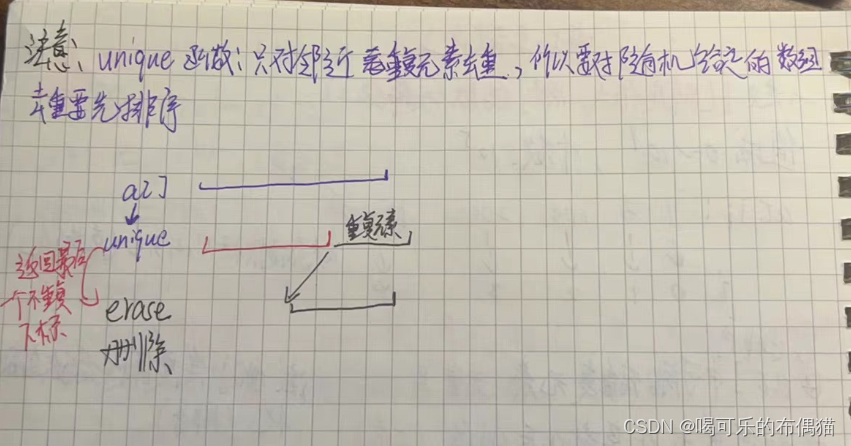
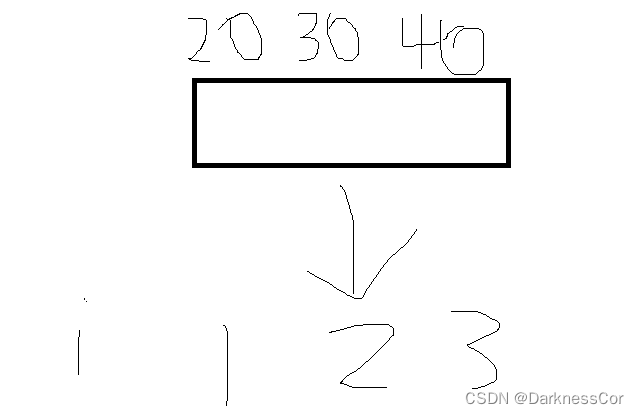
- 离散化算法的映射方式为:首先将这些非连续数字按照从小到大的顺序进行排序,然后按照大小顺序,给这些数组分别分配虚拟下标0、1、2、3…。例如,本题中如果需要进行加法操作的位置分别为
10,100,1000,10000,不采用连续化方法开辟的数组大小至少为10000,而采用连续下标,只需要分别将这四个下标分别映射为0、1、2、3即可,数组大小仅为4,由此可见离散化对本题的作用。排序后,通过二分查找可以快速找到某个原始下标在原始下标序列中的位置,该位置即对应于该原始下标的虚拟下标。 - 离散化的过程中需要考虑去重:对于原始下标序列中相同的下标,它们对应的离散化坐标应该是完成相同的。
- 使用离散化算法得到新的数组下标后,该问题就转换为求一个数组的某个区间的和的问题。但是,如果每次查询,都对一个区间内的元素进行求和,需要进行非常多次的加法,效率相对较低,因此,可以通过前缀和算法对这个过程进行优化,使得每次查询只需要进行一次减法操作即可(空间换时间),具体过程可以参考我的另一篇博客 算法刷题笔记 前缀和(C++实现)。
C++实现代码
// 使用cstdio中的scanf和printf函数取代C++中的cin和cout进行更高效率的输入输出
#include <cstdio>
// 之所以使用向量而非数组是因为C++的STL中的向量的可以方便地进行去重操作
#include <vector>
// 为了使用pair类型而需要导入的C++头文件
#include <utility>
// 为了使用排序函数sort、去重函数unique和删除函数erase而需要导入的C++模块
#include <algorithm>
using namespace std;
vector< pair<int, int> > pair_to_add; // 记录所有加法操作的位置和增加的值
vector<int> positions; // 记录所有加法操作和查询操作的位置
vector< pair<int, int> > query; // 记录所有查询操作的左右端点
// 静态数组空间大小,对应插入操作的最大次数十万和查询操作的最多端点数二十万,多出来的10用于防止数组溢出
const int N = 300010;
int values[N]; // 记录离散化后的每个位置插入的值,由于采用静态数组,所以初始化为零,刚好符合题意
int prefix_sum[N]; // 根据计算完成后的values数组计算得到的前缀和数组,用于快速求出区间和(以空间换时间)
// 通过二分查找,获取当前值的离散化后的下标
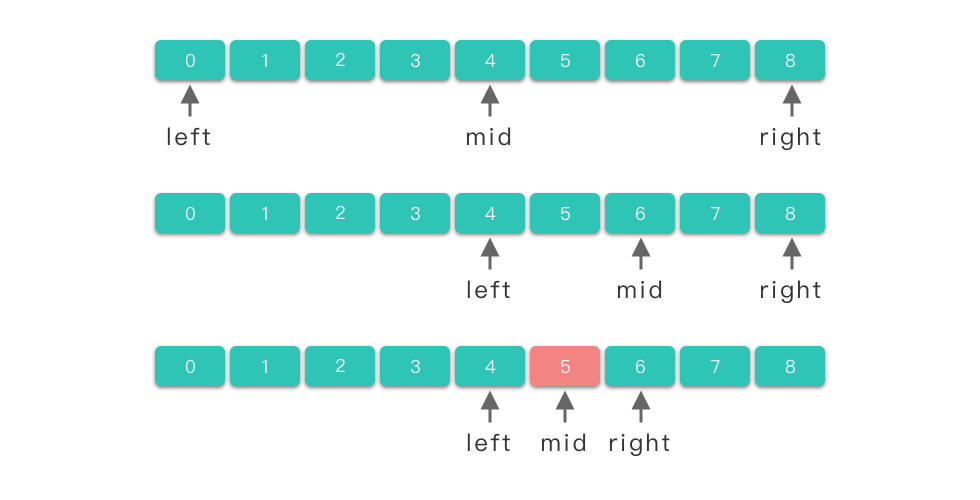
int get_index(const int& x)
{
int left = 0, right = positions.size() - 1;
while(left < right)
{
int mid = (left + right) >> 1; // 右移一位,相当于除以2
if(positions[mid] >= x) right = mid;
else left = mid + 1;
}
return right + 1;
}
int main(void)
{
// 输入加法操作和查询操作的次数
int n, m;
scanf("%d%d", &n, &m);
// 输入指定次数的位置加法操作
for(int i(0); i < n; ++i)
{
int x, c;
scanf("%d%d", &x, &c);
pair_to_add.push_back({x, c}); // 记录当前输入的加法操作
positions.push_back(x); // 记录当前加法操作的位置
}
// 输入指定次数的查询操作
for(int i(0); i < m; ++i)
{
int left, right;
scanf("%d%d", &left, &right);
query.push_back({left, right}); // 记录当前的查询操作
positions.push_back(left); // 记录当前查询操作的左端点
positions.push_back(right); // 记录当前查询操作的右端点
}
// 先对记录的所有位置进行排序,然后去重
sort(positions.begin(), positions.end());
auto after_unique_start = unique(positions.begin(), positions.end());
positions.erase(after_unique_start, positions.end());
// 开始执行加法操作(上面的过程只是进行了记录,还没有真正开始加法)
for(auto item : pair_to_add)
{
int position = get_index(item.first); // 获取当前连续下标对应的离散下标(离散化的过程)
values[position] += item.second; // 将该离散下标处的值增加
}
// values数组计算完成后,基于该数组计算前缀和数组,递归执行即可(因为递归,所以下标从1开始)
for(int i = 1; i <= positions.size(); ++i) prefix_sum[i] = prefix_sum[i - 1] + values[i];
// 处理查询操作
for(auto item : query)
{
int left = get_index(item.first); // 获取查询操作中左端点的离散下标
int right = get_index(item.second); // 获取查询操作中右端点的离散下标
// 输出一次查询的结果
printf("%d\n", prefix_sum[right] - prefix_sum[left - 1]);
}
return 0;
}
由于本题相对较难,因此下面对代码进行逐行解析。
- 第一部分:主函数中读取变量
n和m。这里出于执行效率考虑,没有使用C++中的cin对象进行输入,而是使用C语言中的scanf函数。为了使用这个函数,别忘了导入头文件<cstdio>。 - 第二部分:记录加法操作。
- 首先,代码中采用静态的方式定义了一个向量
pair_to_add,向量中的每个元素是一个有序对类型(pair),每个有序对的首元素表示记录加法的位置,次元素记录加法的运算数。这个向量会在后续的过程中使用。之所以使用向量,是因为C++中向量的效率已经足够高,并且向量有很多比数组方便的多的操作方式。需要注意的是,使用pair和vector需要分别导入头文件<utility>和<vector>,并且加上using namespace std。可以分别使用pair类型的first和second属性获取该有序对的首元素和次元素。 - 接着,代码中定义了一个静态数组
positions,该数组用于存放原始的下标序列。原始的下标序列即直接输入的这些离散的,大取值范围的“数组下标”,也就是数轴上的点。需要存放进positions中的数组下标不仅包括需要进行加法的数轴位置,后续还有进行查询时的左右区间端点的数轴位置。之所以这么做,是因为这样可以简化查询过程的操作,使得查询过程的左右端点都有对应的离散化下标,可以直接相减,而不需要进行复杂的讨论(又是一处空间换时间)。
- 首先,代码中采用静态的方式定义了一个向量
- 第三部分:记录查询操作。首先,代码创建了一个静态向量
query,用于记录每一次查询操作的左右端点。接着,将每一次查询操作的左右端点也放入positions数组中,具体的原因已经在上面进行了说明。 - 第四部分:
positions数组去重。需要说明的是,不去重只排序也并不会影响本题结果的正确性,这是因为后续二分查找的结果对于去重不去重都是该元素对应在数组中的第一个值的位置。但是,经过去重操作后,可以删除positions中多余的元素,从而提高后续过程的效率。这里使用了C++中的sort、unique和erase函数,这三个函数都需要导入头文件<algorithm>。sort的语法:sort(开始排序的位置的迭代器, 结束排序的位置的迭代器),该函数无返回值。unique的语法:该函数用于去除一个有序向量中的重复元素(如果向量无序则首先需要使用sort函数进行排序)。- 有序向量去重的语法:
向量名称.erase((去重开始位置的迭代器, 去重结束位置的迭代器), 向量结束位置的迭代器)。
- 第五部分:进行加法操作。
- 首先,程序创建了一个静态数组
values,该数组用于存储对原始下标进行离散化后,每个新下标对应的元素的值。这里之所以采用静态数组而非向量,是因为整型类型的静态数组初始化后会自动给每个元素赋默认值0,刚好与本题的题意相符方便使用。这里数组的大小为300010,是因为考虑道locations向量的最大容量是300000,即加法操作的最大次数对应的100000个位置和查询操作对应的最大200000个位置,最后用10防止数组溢出。 - 对于
pair_to_add中的每一个元素,根据该元素的原始下标(即数轴位置)获取该元素经过离散化映射后的虚拟下标。由于positions数组是有序数组,因此二分查找是一种效率极高的查找方法。get_index函数即该二分查找算法的一个实现。找到新下标后,将该下标对应的值增加指定的数字即可。
- 首先,程序创建了一个静态数组
- 第六部分:计算前缀和数组。这里的计算只需要递归执行即可。需要注意的是,由于采用递归执行,因此下标应该从
1开始而非从0开始。 这里的前缀和数组prefix_sum也是一个预定义好的静态数组。 - 第七部分:处理查询操作。使用
get_index函数获取每一次查询的左右端点对应的新下标(这里就体现出将查询的端点也放入positions中的方便之处了),然后根据前缀和数组中的元素的差给出答案即可。由于需要求的区间和是left + (left + 1) + … + (right - 1) + right,因此相减的元素应该是prefix[right]和prefix[left-1]。