时间复杂度就是需要执行多少次,空间复杂度就是对象被创建了多少次。
O(1) < O(logn) < O(n) < O(nlogn) < O(n^2) < O(2^n) < O(n!) < O(n^n)
时间复杂度
牢记一个原则:总的时间复杂度就等于量级最大的那段代码的时间复杂度。
说简单点就是执行次数最多的那段代码。
O(1)
首先你必须明确一个概念,O(1) 只是常量级时间复杂度的一种表示方法,并不是指只执行了一行代码。比如这段代码,即便有 3 行,它的时间复杂度也是 O(1),而不是 O(3)。
int i = 8;
int j = 6;
int sum = i + j;
只要代码的执行时间不随 n 的增大而增长,这样代码的时间复杂度我们都记作 O(1)。或者说,一般情况下,只要算法中不存在循环语句、递归语句,即使有成千上万行的代码,其时间复杂度也是Ο(1)。
O(logn)、O(nlogn)
对数阶时间复杂度非常常见,同时也是最难分析的一种时间复杂度。我通过一个例子来说明一下。
i=1;
while (i <= n) {
i = i * 2;
}
根据我们前面讲的复杂度分析方法,第三行代码是循环执行次数最多的。所以,我们只要能计算出这行代码被执行了多少次,就能知道整段代码的时间复杂度。
从代码中可以看出,变量 i 的值从 1 开始取,每循环一次就乘以 2。当大于 n 时,循环结束。还记得我们高中学过的等比数列吗?实际上,变量 i 的取值就是一个等比数列。如果我把它一个一个列出来,就应该是这个样子的:

所以,我们只要知道 x 值是多少,就知道这行代码执行的次数了。通过 2x=n 求解 x 这个问题我们想高中应该就学过了,我就不多说了。x=log2n,所以,这段代码的时间复杂度就是 O(log2n)。
现在,我把代码稍微改下,你再看看,这段代码的时间复杂度是多少?
i=1;
while (i <= n) {
i = i * 3;
}
根据我刚刚讲的思路,很简单就能看出来,这段代码的时间复杂度为 O(log3n)。
实际上,不管是以 2 为底、以 3 为底,还是以 10 为底,我们可以把所有对数阶的时间复杂度都记为 O(logn)。为什么呢?
基于我们前面的一个理论:在采用大 O 标记复杂度的时候,可以忽略系数,即 O(Cf(n)) = O(f(n))。所以,O(log2n) 就等于 O(log3n)。因此,在对数阶时间复杂度的表示方法里,我们忽略对数的“底”,统一表示为 O(logn)。
如果你理解了我前面讲的 O(logn),那 O(nlogn) 就很容易理解了。还记得我们刚讲的乘法法则吗?如果一段代码的时间复杂度是 O(logn),我们循环执行 n 遍,时间复杂度就是 O(nlogn) 了。而且,O(nlogn) 也是一种非常常见的算法时间复杂度。比如,归并排序、快速排序的时间复杂度都是 O(nlogn)。
O(m+n)、O(m*n)
我们再来讲一种跟前面都不一样的时间复杂度,代码的复杂度由两个数据的规模来决定。老规矩,先看代码!
int cal(int m, int n) {
int sum_1 = 0;
int i = 1;
for (; i < m; ++i) {
sum_1 = sum_1 + i;
}
int sum_2 = 0;
int j = 1;
for (; j < n; ++j) {
sum_2 = sum_2 + j;
}
return sum_1 + sum_2;
}
从代码中可以看出,m 和 n 是表示两个数据规模。我们无法事先评估 m 和 n 谁的量级大,所以我们在表示复杂度的时候,就不能简单地利用加法法则,省略掉其中一个。所以,上面代码的时间复杂度就是 O(m+n)。
针对这种情况,原来的加法法则就不正确了,我们需要将加法规则改为:T1(m) + T2(n) = O(f(m) + g(n))。但是乘法法则继续有效:T1(m)*T2(n) = O(f(m) * f(n))。
最好、最坏情况时间复杂度
// n 表示数组 array 的长度
int find(int[] array, int n, int x) {
int i = 0;
int pos = -1;
for (; i < n; ++i) {
if (array[i] == x) pos = i;
}
return pos;
}
这段代码要实现的功能是,在一个无序的数组(array)中,查找变量 x 出现的位置。如果没有找到,就返回 -1。这段代码的复杂度是 O(n),其中,n 代表数组的长度。
我们在数组中查找一个数据,并不需要每次都把整个数组都遍历一遍,因为有可能中途找到就可以提前结束循环了。但是,这段代码写得不够高效。我们可以这样优化一下这段查找代码。
// n 表示数组 array 的长度
int find(int[] array, int n, int x) {
int i = 0;
int pos = -1;
for (; i < n; ++i) {
if (array[i] == x) {
pos = i;
break;
}
}
return pos;
}
这个时候,问题就来了。我们优化完之后,这段代码的时间复杂度还是 O(n) 吗?
因为,要查找的变量 x 可能出现在数组的任意位置。如果数组中第一个元素正好是要查找的变量 x,那就不需要继续遍历剩下的 n-1 个数据了,那时间复杂度就是 O(1)。但如果数组中不存在变量 x,那我们就需要把整个数组都遍历一遍,时间复杂度就成了 O(n)。所以,不同的情况下,这段代码的时间复杂度是不一样的。
为了表示代码在不同情况下的不同时间复杂度,我们需要引入三个概念:最好情况时间复杂度、最坏情况时间复杂度和平均情况时间复杂度。
顾名思义,最好情况时间复杂度就是,在最理想的情况下,执行这段代码的时间复杂度。就像我们刚刚讲到的,在最理想的情况下,要查找的变量 x 正好是数组的第一个元素,这个时候对应的时间复杂度就是最好情况时间复杂度。
同理,最坏情况时间复杂度就是,在最糟糕的情况下,执行这段代码的时间复杂度。就像刚举的那个例子,如果数组中没有要查找的变量 x,我们需要把整个数组都遍历一遍才行,所以这种最糟糕情况下对应的时间复杂度就是最坏情况时间复杂度。
平均情况时间复杂度
最好情况时间复杂度和最坏情况时间复杂度对应的都是极端情况下的代码复杂度,发生的概率其实并不大。为了更好地表示平均情况下的复杂度,我们需要引入另一个概念:平均情况时间复杂度,后面我简称为平均时间复杂度。
平均时间复杂度又该怎么分析呢?我还是借助刚才查找变量 x 的例子来给你解释。
要查找的变量 x 在数组中的位置,有 n+1 种情况:在数组的 0~n-1 位置中和不在数组中。我们把每种情况下,查找需要遍历的元素个数累加起来,然后再除以 n+1,就可以得到需要遍历的元素个数的平均值,即:
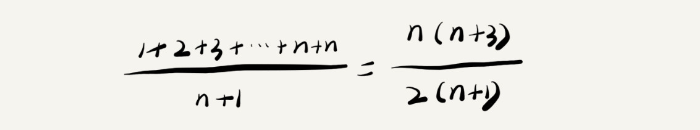
我们知道,时间复杂度的大 O 标记法中,可以省略掉系数、低阶、常量,所以,咱们把刚刚这个公式简化之后,得到的平均时间复杂度就是 O(n)。
这个结论虽然是正确的,但是计算过程稍微有点儿问题。究竟是什么问题呢?我们刚讲的这 n+1 种情况,出现的概率并不是一样的。我带你具体分析一下。(这里要稍微用到一点儿概率论的知识,不过非常简单,你不用担心。)
我们知道,要查找的变量 x,要么在数组里,要么就不在数组里。这两种情况对应的概率统计起来很麻烦,为了方便你理解,我们假设在数组中与不在数组中的概率都为 1/2。另外,要查找的数据出现在 0~n-1 这 n 个位置的概率也是一样的,为 1/n。所以,根据概率乘法法则,要查找的数据出现在 0~n-1 中任意位置的概率就是 1/(2n)。
因此,前面的推导过程中存在的最大问题就是,没有将各种情况发生的概率考虑进去。如果我们把每种情况发生的概率也考虑进去,那平均时间复杂度的计算过程就变成了这样:
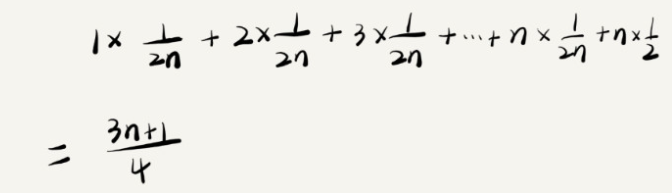
这个值就是概率论中的加权平均值,也叫作期望值,所以平均时间复杂度的全称应该叫加权平均时间复杂度或者期望时间复杂度。
引入概率之后,前面那段代码的加权平均值为 (3n+1)/4。用大 O 表示法来表示,去掉系数和常量,这段代码的加权平均时间复杂度仍然是 O(n)。
引入概率之后,前面那段代码的加权平均值为 (3n+1)/4。用大 O 表示法来表示,去掉系数和常量,这段代码的加权平均时间复杂度仍然是 O(n)。
实际上,在大多数情况下,我们并不需要区分最好、最坏、平均情况时间复杂度三种情况。很多时候,我们使用一个复杂度就可以满足需求了。只有同一块代码在不同的情况下,时间复杂度有量级的差距,我们才会使用这三种复杂度表示法来区分。
均摊时间复杂度
到此为止,你应该已经掌握了算法复杂度分析的大部分内容了。下面我要给你讲一个更加高级的概念,均摊时间复杂度,以及它对应的分析方法,摊还分析(或者叫平摊分析)。
均摊时间复杂度,听起来跟平均时间复杂度有点儿像。对于初学者来说,这两个概念确实非常容易弄混。我前面说了,大部分情况下,我们并不需要区分最好、最坏、平均三种复杂度。平均复杂度只在某些特殊情况下才会用到,而均摊时间复杂度应用的场景比它更加特殊、更加有限。
// array 表示一个长度为 n 的数组
// 代码中的 array.length 就等于 n
int[] array = new int[n];
int count = 0;
void insert(int val) {
if (count == array.length) {
int sum = 0;
for (int i = 0; i < array.length; ++i) {
sum = sum + array[i];
}
array[0] = sum;
count = 1;
}
array[count] = val;
++count;
}
我先来解释一下这段代码。这段代码实现了一个往数组中插入数据的功能。当数组满了之后,也就是代码中的 count == array.length 时,我们用 for 循环遍历数组求和,并清空数组,将求和之后的 sum 值放到数组的第一个位置,然后再将新的数据插入。但如果数组一开始就有空闲空间,则直接将数据插入数组。
那这段代码的时间复杂度是多少呢?你可以先用我们刚讲到的三种时间复杂度的分析方法来分析一下。
最理想的情况下,数组中有空闲空间,我们只需要将数据插入到数组下标为 count 的位置就可以了,所以最好情况时间复杂度为 O(1)。最坏的情况下,数组中没有空闲空间了,我们需要先做一次数组的遍历求和,然后再将数据插入,所以最坏情况时间复杂度为 O(n)。
那平均时间复杂度是多少呢?答案是 O(1)。我们还是可以通过前面讲的概率论的方法来分析。
假设数组的长度是 n,根据数据插入的位置的不同,我们可以分为 n 种情况,每种情况的时间复杂度是 O(1)。除此之外,还有一种“额外”的情况,就是在数组没有空闲空间时插入一个数据,这个时候的时间复杂度是 O(n)。而且,这 n+1 种情况发生的概率一样,都是 1/(n+1)。所以,根据加权平均的计算方法,我们求得的平均时间复杂度就是:
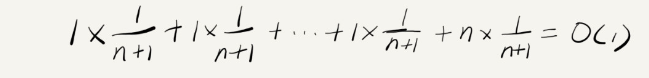
至此为止,前面的最好、最坏、平均时间复杂度的计算,理解起来应该都没有问题。但是这个例子里的平均复杂度分析其实并不需要这么复杂,不需要引入概率论的知识。这是为什么呢?我们先来对比一下这个 insert() 的例子和前面那个 find() 的例子,你就会发现这两者有很大差别。
首先,find() 函数在极端情况下,复杂度才为 O(1)。但 insert() 在大部分情况下,时间复杂度都为 O(1)。只有个别情况下,复杂度才比较高,为 O(n)。这是 insert()第一个区别于 find() 的地方。
我们再来看第二个不同的地方。对于 insert() 函数来说,O(1) 时间复杂度的插入和 O(n) 时间复杂度的插入,出现的频率是非常有规律的,而且有一定的前后时序关系,一般都是一个 O(n) 插入之后,紧跟着 n-1 个 O(1) 的插入操作,循环往复。
所以,针对这样一种特殊场景的复杂度分析,我们并不需要像之前讲平均复杂度分析方法那样,找出所有的输入情况及相应的发生概率,然后再计算加权平均值。
针对这种特殊的场景,我们引入了一种更加简单的分析方法:摊还分析法,通过摊还分析得到的时间复杂度我们起了一个名字,叫均摊时间复杂度。
那究竟如何使用摊还分析法来分析算法的均摊时间复杂度呢?
我们还是继续看在数组中插入数据的这个例子。每一次 O(n) 的插入操作,都会跟着 n-1 次 O(1) 的插入操作,所以把耗时多的那次操作均摊到接下来的 n-1 次耗时少的操作上,均摊下来,这一组连续的操作的均摊时间复杂度就是 O(1)。这就是均摊分析的大致思路。你都理解了吗?
均摊时间复杂度和摊还分析应用场景比较特殊,所以我们并不会经常用到。为了方便你理解、记忆,我这里简单总结一下它们的应用场景。如果你遇到了,知道是怎么回事儿就行了。
对一个数据结构进行一组连续操作中,大部分情况下时间复杂度都很低,只有个别情况下时间复杂度比较高,而且这些操作之间存在前后连贯的时序关系,这个时候,我们就可以将这一组操作放在一块儿分析,看是否能将较高时间复杂度那次操作的耗时,平摊到其他那些时间复杂度比较低的操作上。而且,在能够应用均摊时间复杂度分析的场合,一般均摊时间复杂度就等于最好情况时间复杂度。
空间复杂度分析
空间复杂度简单点可以理解:创建了多少次,总的空间复杂度就等于量级最大的那段代码的空间复杂度。
分析方法同时间复杂度一样。