在分布式环境下,有几个问题是普遍关心的:
- 如何检测当前节点还活着?
- 如何保障高可用?
- 容错处理
- 负载均衡
1.心跳检测
在分布式环境中,我们提及过存在非常多的节点(Node)。那么就有一个非常重要的问题,如何检测一个节点出现了故障乃至无法工作了?
通常解决这一问题采用心跳检测的手段,如同通过仪器对病人进行一些检测诊断一样。
心跳顾名思义,就是以固定的频率向其他节点汇报当前节点状态的方式。收到心跳,一般可以认为一个节点和现在的网络是良好的。当然,心跳汇报时,一般也会携带一些附加的状态、元数据信息,以便管理。
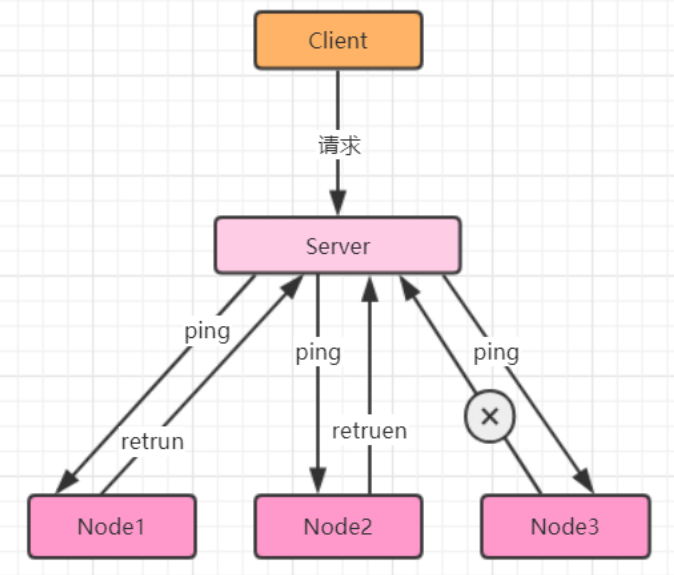
若Server没有收到Node3的心跳时,Server认为Node3失联。但是失联是失去联系,并不确定是否是Node3故障,有可能是Node3处于繁忙状态,导致调用检测超时;也有可能是Server与Node3之间链路出现故障或闪断。所以心跳不是万能的,收到心跳可以确认节点正常,但是收不到心跳也不能认为该节点就已经宣告“死亡”。此时,可以通过一些方法帮助Server做决定:周期检测心跳机制、累计失效检测机制。
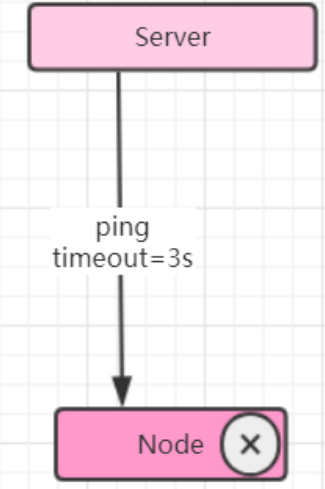
- 周期检测心跳机制
- Server端每隔t秒向Node集群发起检测请求,设定超时时间,如果超过超时时间,则判断“死亡”。可以把该节点踢出集群。
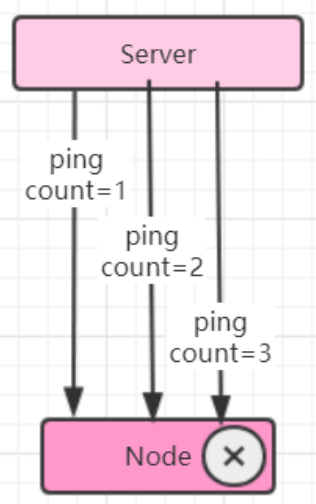
- 累计失效检测机制
- 在周期检测心跳机制的基础上,统计一定周期内节点的返回情况(包括超时及正确返回),依次计算节点的“死亡”概率。另外,对于宣告“濒临死亡”的节点可以发起有限次数的重试,以作进一步判断。如果超过次数则可以把该节点踢出集群。
2.高可用
1)高可用HA设计
高可用(High Availability)是系统架构设计中必须考虑的因素之一,通常是指,经过设计来减少系统不能提供服务的事件。

系统高可用性的常用设计模式包括三种:主备(Master-Slave)、互备(Active-Active)和集群(Cluster)模式。
(1)主备模式
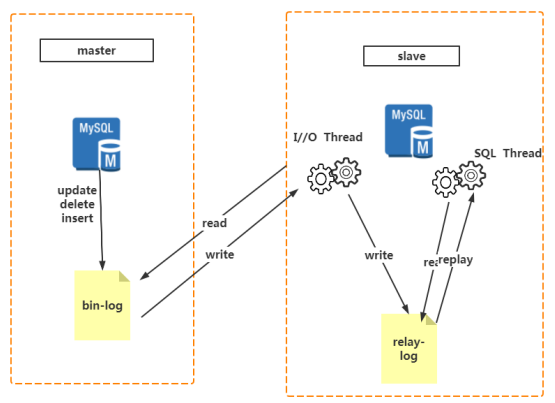
主备模式就是Active-Standby模式,当主机宕机时,备机接管主机的一切工作,待主机恢复正常后,按使用者的设定以自动(热备)或手动(冷备)方式将服务切换到主机上运行。在数据库部分,习惯称之为MS模式。MS模式即Master/Slave模式,这在数据库高可用性方案中比较常用,如MySQL、Redis等就采用MS模式实现主从复制。保证高可用,如图所示。
(2)互备模式
互备模式指两台主机同时运行各自的服务工作且相互检测情况。在数据库高可用部分,常见的互备是MM模式。MM模式即Multi-Master模式,指一个系统存在多个master,每个master都具有read-write能力,会根据时间戳或业务逻辑合并版本。
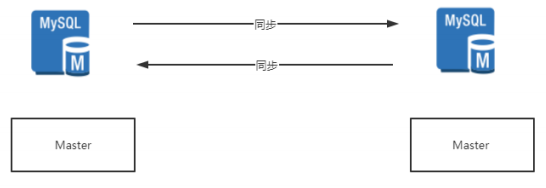
(3)集群模式
集群模式是指有多个节点在运行,同时可以通过主控节点分担服务请求。集群模式需要解决主控节点本身的高可用问题,一般采用主备模式。
2)高可用HA下”脑裂问题“
(1)什么是脑裂
在高可用(HA)系统中,当联系两个节点的“心跳线”断开时(即两个节点断开联系时)。本来为一个整体、动作协调的HA系统,就分裂成为两个独立的节点(即两个独立的个体)。由于相互失去了联系,都以为是对方出了故障,两个节点上的HA软件像“裂脑人”一样,“本能”地争抢“共享资源”、争起“应用服务”。
就会发生严重的后果:
- 共享资源被瓜分、两边“服务”都起不来了;
- 两边“服务”都起来了,但同时读写“共享存储”,导致数据损坏(常见如数据库轮询着的联机日志出错)
两个节点相互争抢共享资源,结果会导致系统混乱,数据损坏。对于无状态服务的HA,无所谓脑裂不脑裂,但对有状态服务(比如MySQL)的HA,必须要严格防止脑裂。
(2)脑裂出现的原因
一般来说,脑裂的发生,有以下几种原因:
- 高可用服务器各节点之间心跳线链路发生故障,导致无法正常通信
- 因网卡及相关驱动坏了,ip配置及冲突问题(网卡直连)
- 因心跳线间连接的设备故障(网卡及交换机)
- 因仲裁的机器出问题(采用仲裁的方案)
- 高可用服务器上开启了iptables防火墙阻挡了心跳消息传输
- 高可用服务器上心跳网卡地址等信息配置不正确,导致发送心跳失败
- 其他服务配置不当等原因,如心跳方式不同,心跳广插冲突、软件Bug等
(3)脑裂预防方案
- 添加冗余的心跳线(即冗余通信的方法)
- 同时用两条心跳线路(即心跳线也HA),这样一条线路坏了,另一个还是好的,依然能传送心跳消息,尽量减少“脑裂”现象的发生几率
- 仲裁机制
- 当两个节点出现分歧时,由第3方的仲裁者决定听谁的。这个仲裁者,可能是一个锁服务,一个共享盘或者其他什么东西。
- Lease机制
- 隔离(Fencing)机制
- 共享存储fencing:确保只有一个Master往共享存储中写数据
- 客户端fencing:确保只有一个Master可以响应客户端的请求
- Slave fencing:确保只有一个Master可以向Slave下发命令
3.容错性
容错性:IT系统对于错误的包容能力
容错的处理是保障分布式环境下相应系统的高可用或者健壮性,一个典型的案例就是对于缓存穿透问题的解决方案。
4.负载均衡
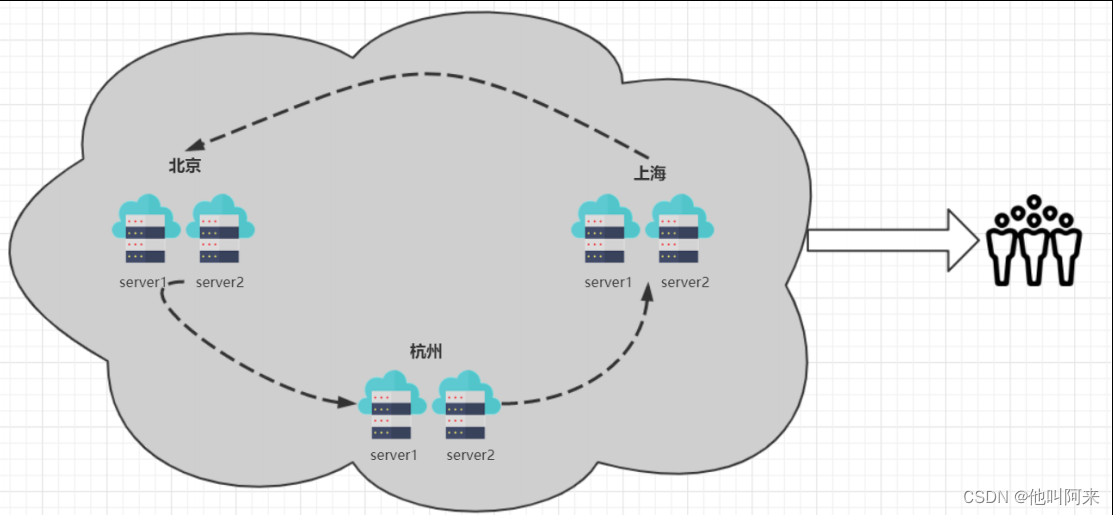
负载均衡:其关键在于使用多态集群服务器共同分担计算任务,把网络请求及计算分配到集群可用的不同服务器节点上,从而达到高可用性及较好的用户操作体验。
如图,不同的用户client1、client2、client3访问呢应用,通过负载均衡器分配到不同的节点
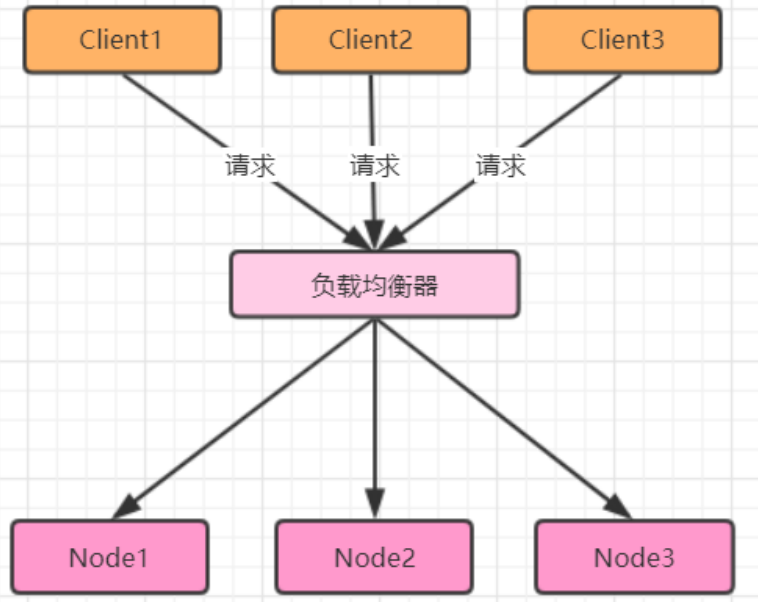
负载均衡器有硬件解决方案,也有软件解决方案。硬件解决方案有著名的F5,软件有LVS、HAProxy、Nginx等。
以Nginx为例,负载均衡有以下6中策略:






























![[FFmpeg学习]windows环境sdl播放音频试验](https://img-blog.csdnimg.cn/direct/27cb970f1fca4730bc9aa2eb638f10a5.png)










