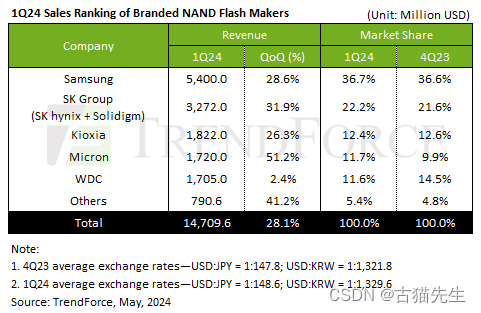
1.环境搭建
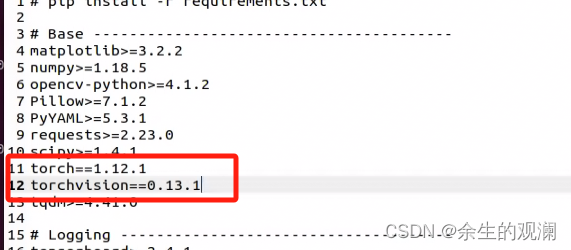
1.1conda创建虚拟环境
confa create -n PaddleOcr --clone base
若出现
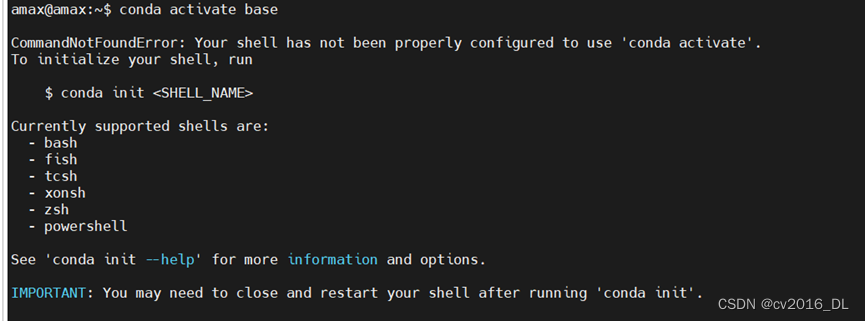
使用命令
source activate
然后再conda activate PaddleOcr 虚拟环境搭建完成。
1.2.若出现Config use_gpu cannot be set as true while your paddle is not compiled with cuda !
需要卸载Paddle 的CPU版本,创建GPU版本
python -m pip install paddlepaddle-gpu==2.5.2
1.3.若出现paddleocr报错:AttributeError: ‘ParallelEnv‘ object has no attribute ‘_device_id‘
用
device = 'gpu:{}'.format(dist.get_rank()) if use_gpu else 'cpu'
1.4.用python ./tools/train.py -c ./configs/rec/rec_svtrnet_ch.yml 可以训练SVTR版本OCR,若能打印信息,说明环境基本正常,需要准备数据
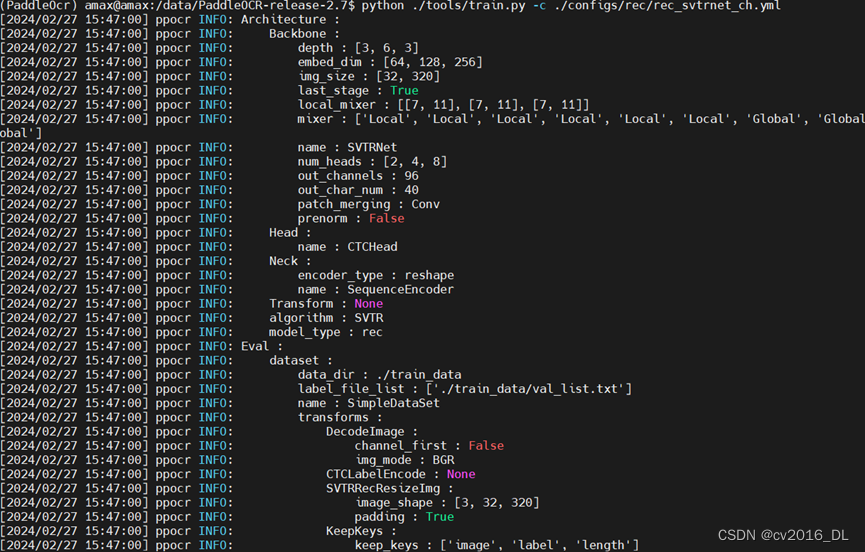
2.测试开源模型效果
代码:
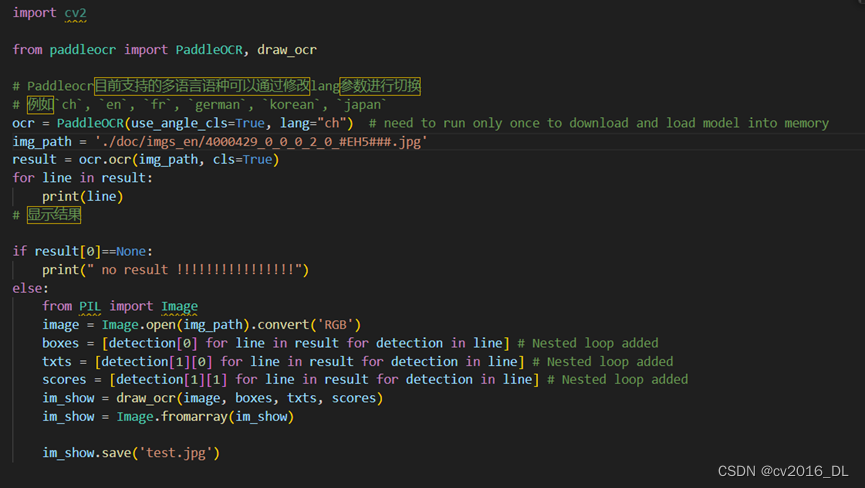
也可以使用如下代码:
import cv2
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
img_path = './doc/imgs_en/img_10.jpg'
# 第一种使用读入图片转为ndarray
from PIL import Image
import numpy as np
img = Image.open(img_path)
img = np.array(img)
result = ocr.ocr(img, cls=True)
# 第二种使用cv2读入图片。
img=cv2.imread(img_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
result = ocr.ocr(img, cls=True)
会下载模型,打印结果:
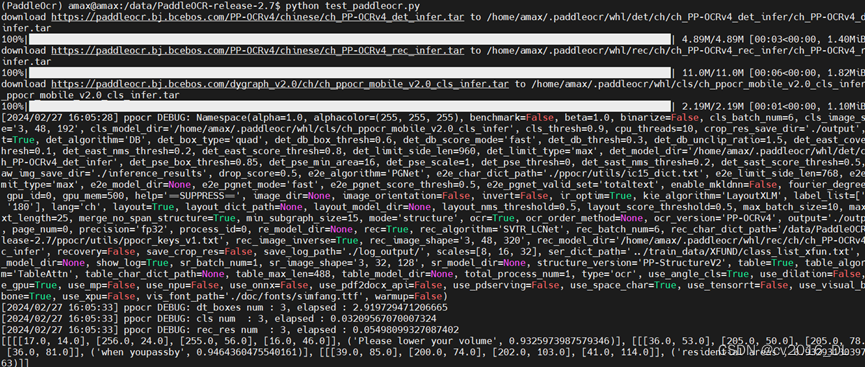
开源模型效果:

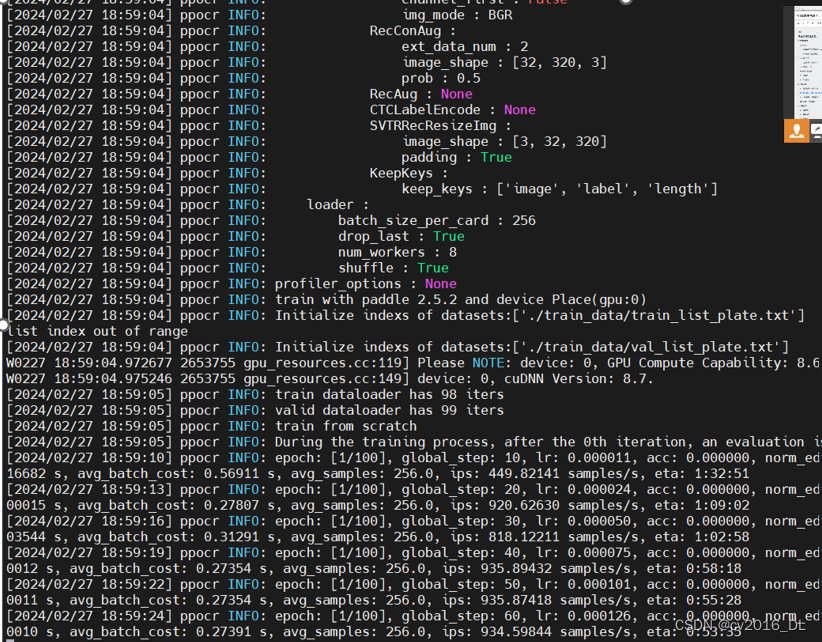
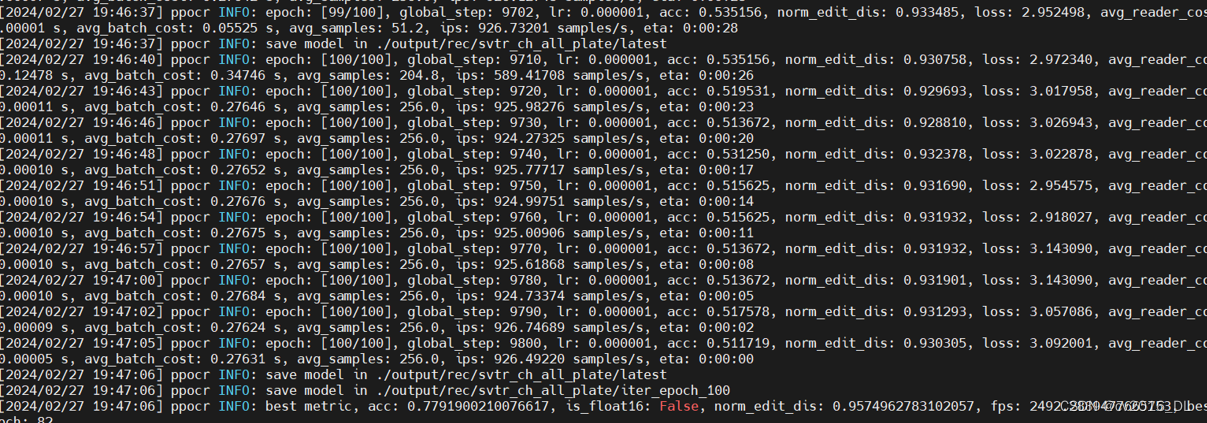
3.训练车牌模型
训练时需要对标注进行转换:
./train/1297499_0_0_0_1_0_陕BR1393.jpg 陕BR1393
./train/1299492_0_0_0_0_0_豫R328DQ.jpg 豫R328DQ
python ./tools/train.py
4.训练模型预测
# 预测车牌结果python tools/infer_rec.py -c configs/rec/rec_svtrnet_ch_plate.yml -o Global.pretrained_model=output/rec/svtr_ch_all_plate_small_only/best_accuracy Global.infer_img=doc/imgs_words/ch/word_0.jpg
识别结果为:鄂E57Z99,识别正确

5.模型导出
python tools/export_model.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o Global.pretrained_model=./output/v3_en_mobile/best_accuracy Global.save_inference_dir=./inference/en_PP-OCRv3_rec/